


Optimering af netværkssoftware til at fremme videnskabelig opdagelse

Brookhaven Lab samarbejdede med Columbia University, University of Edinburgh, og Intel for at optimere ydeevnen på en 144-node parallelcomputer bygget fra Intels Xeon Phi-processorer og Omni-Path-højhastigheds-kommunikationsnetværk. Computeren er installeret på Brookhaven's Scientific Data and Computing Center, som set ovenfor med teknologiingeniør Costin Caramarcu. Kredit:Brookhaven National Laboratory
Højtydende computing (HPC)-brugen af supercomputere og parallelle behandlingsteknikker til at løse store beregningsproblemer-er til stor nytte i det videnskabelige samfund. For eksempel, forskere ved US Department of Energy's (DOE) Brookhaven National Laboratory er afhængige af HPC til at analysere de data, de indsamler på de store eksperimentelle faciliteter på stedet og til at modellere komplekse processer, der ville være for dyre eller umulige at demonstrere eksperimentelt.
Moderne videnskabelige applikationer, såsom simulering af partikelinteraktioner, kræver ofte en kombination af aggregeret computerkraft, højhastighedsnetværk til dataoverførsel, store mængder hukommelse, og lagerkapacitet med høj kapacitet. Fremskridt inden for HPC hardware og software er nødvendige for at opfylde disse krav. Computer- og beregningsforskere og matematikere i Brookhaven Labs Computational Science Initiative (CSI) samarbejder med fysikere, biologer, og andre domæneforskere til at forstå deres dataanalysebehov og levere løsninger til at fremskynde den videnskabelige opdagelsesproces.
En HPC brancheleder
I årtier, Intel Corporation har været en af lederne inden for udvikling af HPC -teknologier. I 2016, virksomheden frigav Intel Xeon PhiTM-processorer (tidligere kodenavnet "Knights Landing"), sin anden generations HPC-arkitektur, der integrerer mange processorenheder (kerner) pr. chip. Samme år, Intel frigav Intel Omni-Path Architecture højhastigheds-kommunikationsnetværk. For at de 5, 000 til 100, 000 individuelle computere, eller noder, i moderne supercomputere til at arbejde sammen om at løse et problem, de skal hurtigt kunne kommunikere med hinanden og samtidig minimere netværksforsinkelser.
Kort efter disse udgivelser, Brookhaven Lab og RIKEN, Japans største omfattende forskningsinstitution, samlede deres ressourcer til at købe en lille 144-node parallel computer bygget fra Xeon Phi-processorer og to uafhængige netværksforbindelser, eller skinner, ved hjælp af Intels Omni-Path-arkitektur. Computeren blev installeret på Brookhaven Labs Scientific Data and Computing Center, som er en del af CSI.
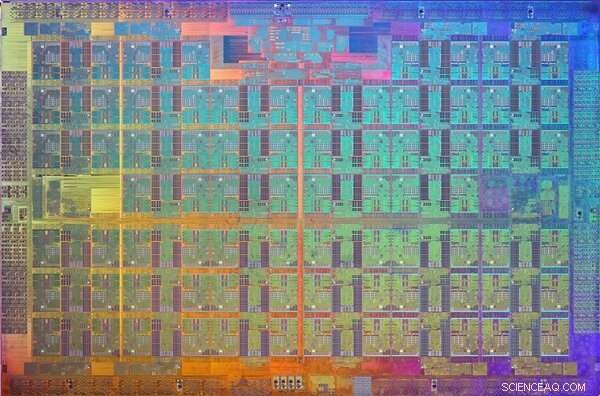
Et billede af Xeon Phi Knights Landing -processoren dør. En matrice er et mønster på en wafer af halvledende materiale, der indeholder det elektroniske kredsløb til at udføre en bestemt funktion. Kredit:Intel
Når installationen er afsluttet, fysiker Chulwoo Jung og CSI -beregningsforsker Meifeng Lin fra Brookhaven Lab; teoretisk fysiker Christoph Lehner, en fælles udpeget ved Brookhaven Lab og University of Regensburg i Tyskland; Norman Kristus, Ephraim Gildor Professor i Computational Theoretical Physics ved Columbia University; og teoretisk partikelfysiker Peter Boyle fra University of Edinburgh arbejdede i tæt samarbejde med softwareingeniører hos Intel for at optimere netværkssoftwaren til to videnskabelige applikationer:partikelfysik og maskinlæring.
"CSI havde været meget interesseret i Intel Omni-Path Architecture siden det blev annonceret i 2015, "sagde Lin." Intel-ingeniørernes ekspertise var afgørende for at implementere softwareoptimeringerne, der tillod os fuldt ud at udnytte dette højtydende kommunikationsnetværk til vores specifikke applikationsbehov. "
Netværkskrav til videnskabelige anvendelser
Til mange videnskabelige anvendelser, at køre en rang (en værdi, der adskiller en proces fra en anden) eller muligvis et par rækker pr. node på en parallelcomputer, er meget mere effektiv end at køre flere rækker pr. node. Hver rang udføres typisk som en uafhængig proces, der kommunikerer med de andre rækker ved hjælp af en standardprotokol kendt som Message Passing Interface (MPI).
For eksempel, fysikere, der søger at forstå, hvordan det tidlige univers dannede, kører komplekse numeriske simuleringer af partikelinteraktioner baseret på teorien om kvantekromodynamik (QCD). Denne teori forklarer, hvordan elementarpartikler kaldet kvarker og gluoner interagerer for at danne de partikler, vi direkte observerer, såsom protoner og neutroner. Fysikere modellerer disse interaktioner ved hjælp af supercomputere, der repræsenterer de tre dimensioner af rummet og tidsdimensionen i et fire-dimensionelt (4-D) gitter med lige store punkter, ligner en krystal. Gitteret er opdelt i mindre identiske undervolumener. For gitter -QCD -beregninger, data skal udveksles ved grænserne mellem de forskellige delmængder. Hvis der er flere rækker pr. Node, hver rang er vært for en anden 4-D sub-volume. Dermed, opdeling af delmængderne skaber flere grænser, hvor data skal udveksles og derfor unødvendige dataoverførsler, der bremser beregningerne.
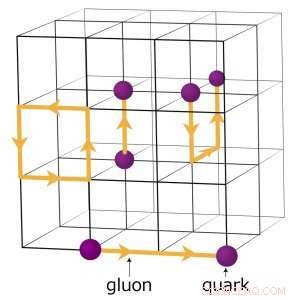
En skematisk oversigt over gitteret til kvantekromodynamiske beregninger. Skæringspunkterne på nettet repræsenterer kvarkværdier, mens linjerne mellem dem repræsenterer gluonværdier. Kredit:Brookhaven National Laboratory
Softwareoptimeringer til at fremme videnskab
For at optimere netværkssoftwaren til en så beregningsmæssigt intensiv videnskabelig applikation, holdet fokuserede på at øge hastigheden på en enkelt rang.
"Vi fik koden til en enkelt MPI -rang til at køre hurtigere, så en spredning af MPI -rækker ikke ville være nødvendig for at håndtere den store kommunikationsbelastning, der er til stede for hver node, "forklarede Kristus.
Softwaren inden for MPI -rang udnytter den gevindskårne parallelisme, der er tilgængelig på Xeon Phi -noder. Gevindparallellisme refererer til samtidig udførelse af flere processer, eller tråde, der følger de samme instruktioner, mens du deler nogle computerressourcer. Med den optimerede software, teamet var i stand til at oprette flere kommunikationskanaler på en enkelt rang og drive disse kanaler ved hjælp af forskellige tråde.
MPI-softwaren blev nu konfigureret til at de videnskabelige applikationer kunne køre hurtigere og drage fuld fordel af Intel Omni-Path kommunikationshardware. Men efter implementeringen af softwaren, holdmedlemmerne stødte på en anden udfordring:i hvert løb, et par knuder ville uundgåeligt kommunikere langsomt og holde de andre tilbage.
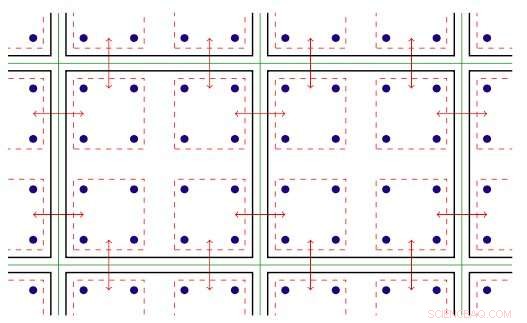
To-dimensionel illustration af gevindskåret parallelisme. Nøgle:grønne linjer adskiller fysiske beregningsknudepunkter; sorte linjer adskiller MPI -rækker; røde linjer er kommunikationskontekster, med pilene, der angiver kommunikation mellem noder eller hukommelseskopi i en knude via Intel Omni-Path-hardware. Kredit:Brookhaven National Laboratory
De sporede dette problem til den måde, Linux - operativsystemet, der bruges af de fleste HPC -platforme - styrer hukommelse. I standardtilstanden, Linux deler hukommelsen i små bidder kaldet sider. Ved at omkonfigurere Linux til at bruge store ("enorme") hukommelsessider, de løste problemet. Forøgelse af sidestørrelsen betyder, at der er behov for færre sider for at kortlægge det virtuelle adresserum, som et program bruger. Som resultat, hukommelse kan fås meget hurtigere.
Med softwareudvidelserne, teammedlemmerne analyserede ydeevnen for Intel Omni-Path Architecture og Intel Xeon Phi-processor-noder installeret på Intels dual-rail "Diamond" -klynge og Distributed Research Using Advanced Computing (DiRAC) single-rail cluster i Storbritannien. Til deres analyse, de brugte to forskellige klasser af videnskabelige anvendelser:partikelfysik og maskinlæring. For begge applikationskoder, de opnåede nærtrådshastighed-den teoretiske maksimale hastighed for dataoverførsel. Denne forbedring repræsenterer en stigning i netværksydelsen, der er mellem fire og ti gange den for de originale koder.
"På grund af det tætte samarbejde mellem Brookhaven, Edinburgh, og Intel, disse optimeringer blev gjort tilgængelige på verdensplan i en ny version af Intel Omni-Path MPI-implementeringen og en best-practice-protokol til konfiguration af Linux-hukommelsesstyring, "sagde Kristus." Faktoren på fem hastigheder i udførelsen af fysikkoden på Xeon Phi -computeren på Brookhaven Lab - og på University of Edinburghs nye, endnu større 800-node Hewlett Packard Enterprise "hypercube" computer-bliver nu taget godt i brug i igangværende undersøgelser af grundlæggende spørgsmål inden for partikelfysik. "
 Varme artikler
Varme artikler
-
 Lufthansa reducerer tabene i 1. kvartal, da det fordøjer Air BerlinLufthansas CEO hilste det, han kaldte et godt sæt resultater velkommen Den tyske flyselskabsgigant Lufthansa sagde torsdag, at den havde reduceret tabene i første kvartal. men bekræftede, at det f
Lufthansa reducerer tabene i 1. kvartal, da det fordøjer Air BerlinLufthansas CEO hilste det, han kaldte et godt sæt resultater velkommen Den tyske flyselskabsgigant Lufthansa sagde torsdag, at den havde reduceret tabene i første kvartal. men bekræftede, at det f -
 En algoritme til at opdage påvirkninger udefra på medierneKredit:Ecole Polytechnique Federale de Lausanne EPFL -forskere har for nylig udviklet en algoritme, der kortlægger medielandskabet og afslører skævheder og skjult påvirkning i nyhedsindustrien. N
En algoritme til at opdage påvirkninger udefra på medierneKredit:Ecole Polytechnique Federale de Lausanne EPFL -forskere har for nylig udviklet en algoritme, der kortlægger medielandskabet og afslører skævheder og skjult påvirkning i nyhedsindustrien. N -
 Ingeniører fremviser robothunden AstroVed hjælp af dyb læring og kunstig intelligens (AI), FAU -forskere levendegør en af cirka en håndfuld af disse firkanterede robotter i verden. Astro er unik, fordi han er den eneste af disse robotte
Ingeniører fremviser robothunden AstroVed hjælp af dyb læring og kunstig intelligens (AI), FAU -forskere levendegør en af cirka en håndfuld af disse firkanterede robotter i verden. Astro er unik, fordi han er den eneste af disse robotte -
 Boeing giver råd om sensorer efter nedstyrtning i IndonesienLion Air JT610 styrtede ned i Javahavet mindre end en halv time efter at have lettet fra Jakarta på en rutineflyvning til Pangkal Pinang by Boeing udsendte onsdag en særlig bulletin, der adressere
Boeing giver råd om sensorer efter nedstyrtning i IndonesienLion Air JT610 styrtede ned i Javahavet mindre end en halv time efter at have lettet fra Jakarta på en rutineflyvning til Pangkal Pinang by Boeing udsendte onsdag en særlig bulletin, der adressere
- Curcumin nanopartikler åbner op for resistente kræftformer
- Undersøgelsen har til formål at give en nøjagtig vurdering af virkningen af fremtidige havnivea…
- Ny tilskudsfinansieret database om misbrug af undervisere brugt som forsknings- og forebyggelsesvær…
- Ultra-lille nanokavitet udvikler teknologi til sikker kvantebaseret datakryptering
- Fakta om Amazonas regnskov for Kids
- Hvordan stratosfærisk liv lærer os om muligheden for ekstremt liv på andre verdener