


Mona Lisa gæst på TV? Forskere regner ud fra billeder, kunst
Kredit:Egor Zakharov et al.
Et papir, der diskuterer en kunstig intelligens-bedrift, der nu er oppe på arXiv, giver tech-watchers endnu en grund til at føle, at dette er Enfrightenment-alderen.
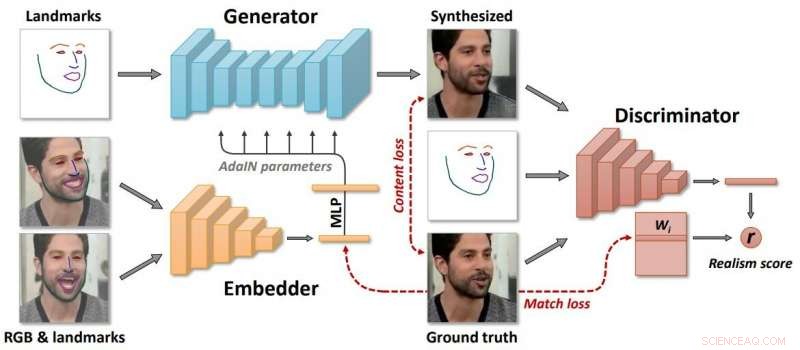
"Fow-Shot Adversarial Learning of Realistic Neural Talking Head Models" af Egor Zakharov, Aliaksandra Shysheya, Egor Burkov og Victor Lempitsky afslører deres teknik, der kan forvandle fotos og malerier til animerede talking heads. Forfattertilknytninger omfatter Samsung AI Center, Moskva og Skolkovo Institut for Videnskab og Teknologi.
Nøglespilleren i alt dette? Samsung. Det åbnede forskningscentre i Moskva, Cambridge og Toronto sidste år, og slutresultatet kunne meget vel være flere overskrifter i AI-historien.
Ja, Mona Lisa kan se ud, som om hun fortæller sin tv-vært, hvorfor hun foretrækker leave-in hårbalsam. Albert Einstein kan se ud, som om han taler for slet ingen hårprodukter.
De skrev, at "vi betragter problemet med at syntetisere fotorealistiske personlige hovedbilleder givet et sæt af ansigts vartegn, som driver modellens animation." Et skud lærer fra et enkelt billede, også selvom, er muligt.
Khari Johnson, VentureBeat , bemærkede, at de kan generere realistiske animerede talking heads fra billeder uden afhængig af traditionelle metoder såsom 3D-modellering.
Forfatterne fremhævede, at "Det er afgørende, systemet er i stand til at initialisere parametrene for både generatoren og diskriminatoren på en personspecifik måde, så træningen kan baseres på nogle få billeder og udføres hurtigt, på trods af behovet for at tune titusinder af parametre."
Hvad er deres tilgang? Ivan Mehta ind Det næste web gik læserne gennem de trin, der danner deres teknik.
"Samsung sagde, at modellen skaber tre neurale netværk under læringsprocessen. For det første, det skaber et indlejret netværk, der forbinder rammer relateret til ansigtets vartegn med vektorer. Brug derefter disse data, systemet opretter et generatornetværk, som kortlægger vartegn i de syntetiserede videoer. Endelig, diskriminatornetværket vurderer realismen og posituren af genererede frames."
Forfatterne beskrev "langvarig meta-læring" på et stort datasæt af videoer, og i stand til at indramme få- og enkeltindlæring af neurale talende hovedmodeller af tidligere usete mennesker som modstridende træningsproblemer, med højkapacitetsgeneratorer og diskriminatorer.
Hvem ville egentlig bruge dette system? Rapporter nævnte teletilstedeværelse, spil med flere spillere og specialeffektindustrien.
Ikke desto mindre, Johnson og andre, der indgav deres rapporter, var ikke ved at ignorere risikoen for teknologiske fremskridt i de forkerte hænder, hvor de drilske kan producere falskhed med dårlige hensigter.
"Sådan teknologi kunne helt klart også bruges til at skabe deepfakes, " skrev Johnson.
Så, vi vil måske slå pause på den tanke. Bare at forfattere nu så henkastet refererer til de "dybe falske" resultater, der kommer ud af nogle kunstig intelligens-projekter. Og forfattere undrer sig over, hvad dette Samsung-trin i teknologi kan betyde i deepfakes.
Jon Christian havde overblik i Futurisme . "I løbet af de sidste par år har Vi har set den hastige fremgang af 'deepfake'-teknologi, der bruger maskinlæring til at analysere optagelser af rigtige mennesker – og derefter producerer overbevisende videoer af dem, der gør ting, de aldrig har gjort, eller siger ting, de aldrig har sagt."
Joan Solsman i CNET:"Den hurtige fremgang inden for kunstig intelligens betyder, at hver gang en forsker deler et gennembrud inden for deepfake-skabelse, dårlige skuespillere kan begynde at skrabe deres egne jury-rigtige værktøjer sammen for at efterligne det."
Interessant nok, jo mere offentligheden er opmærksom på AI-falsk, jo lettere kan de acceptere, at nogle animationer er falske - eller ej? En seerkommentar på videosiden:"I fremtiden, afpresning er umulig, fordi alle ved, at du nemt kan lave en video ud af hvad som helst."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 New York mister samkørselsudbyder, da Juno dropper udEn af New Yorks samkørselstjenester, Juno, lukker ned, med henvisning til markedsforhold og nye regler pålagt af byen Det New York-baserede rideshare-firma Juno sagde mandag, at det lukkede ned fo
New York mister samkørselsudbyder, da Juno dropper udEn af New Yorks samkørselstjenester, Juno, lukker ned, med henvisning til markedsforhold og nye regler pålagt af byen Det New York-baserede rideshare-firma Juno sagde mandag, at det lukkede ned fo -
 Ny bog afslører AIs grænserKredit:Macmillan Lige siden dets oprindelse i efterkrigsforskning, AI har været udsat for dyb hyperbole, henrykte prognoser, og projekterede mareridt. I 2019, tingene har endnu engang nået feberhø
Ny bog afslører AIs grænserKredit:Macmillan Lige siden dets oprindelse i efterkrigsforskning, AI har været udsat for dyb hyperbole, henrykte prognoser, og projekterede mareridt. I 2019, tingene har endnu engang nået feberhø -
 Den britiske vagthund vurderer beviser fra Cambridge AnalyticaScenen ved et vindue, hvor informationskommissærens håndhævelsesofficerer arbejder inde på Cambridge Analyticas kontorer i det centrale London, efter at en højesteretsdommer udstedte en ransagningsken
Den britiske vagthund vurderer beviser fra Cambridge AnalyticaScenen ved et vindue, hvor informationskommissærens håndhævelsesofficerer arbejder inde på Cambridge Analyticas kontorer i det centrale London, efter at en højesteretsdommer udstedte en ransagningsken -
 Twitter-udfald rapporteret fra Japan til USABrugere fra Japan til USA rapporterede, at de ikke var i stand til at logge ind, brug mobilappen eller se direkte beskeder Flere funktioner på Twitter var nede onsdag, platformen sagde, med bruger
Twitter-udfald rapporteret fra Japan til USABrugere fra Japan til USA rapporterede, at de ikke var i stand til at logge ind, brug mobilappen eller se direkte beskeder Flere funktioner på Twitter var nede onsdag, platformen sagde, med bruger
- Girl power:Alle kvindelige hold konkurrerer ved robotarrangementer
- Har du tillid til politikere? Det afhænger af, hvordan du definerer tillid
- Southwest forlænger MAX-jordforbindelse indtil april 2020
- Kan vores hjerne se den fjerde dimension?
- Little Foot skull afslører, hvordan denne mere end 3 millioner år gamle menneskelige forfader leve…
- Nye kosmiske magnetfeltstrukturer opdaget i galaksen NGC 4217