


En teknik til at forbedre maskinlæring inspireret af menneskelige spædbørns adfærd
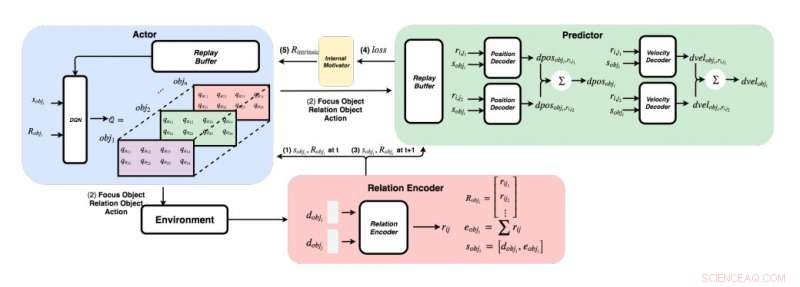
Et detaljeret diagram over tilgangen udviklet af forskerne. (Nederst til højre) For hvert par genstande, forskerne fodrer deres funktioner ind i en relationskoder for at få relation rij og objekt i's tilstand sobji. (øverst til venstre) Ved at bruge den grådige metode, for hvert objekt, de finder den maksimale Q-værdi for at få vores fokusobjekt, relationsobjekt, og handling. (Øverst til højre) Når de havde samlet deres fokusobjekt og relationsobjekt, de fodrer deres tilstande og alle deres relationer til deres dekodere for at forudsige ændringen i position og hastighedsændring. Kredit:Choi &Yoon.
Fra deres første leveår, mennesker har den medfødte evne til at lære kontinuerligt og bygge mentale modeller af verden, blot ved at observere og interagere med ting eller mennesker i deres omgivelser. Kognitiv psykologi undersøgelser tyder på, at mennesker gør udstrakt brug af denne tidligere erhvervede viden, især når de møder nye situationer eller når de træffer beslutninger.
På trods af de betydelige nylige fremskridt inden for kunstig intelligens (AI), de fleste virtuelle agenter kræver stadig hundredvis af timers træning for at opnå præstation på menneskeligt niveau i flere opgaver, mens mennesker kan lære at udføre disse opgaver på få timer eller mindre. Nylige undersøgelser har fremhævet to vigtige bidragsydere til menneskers evne til at tilegne sig viden så hurtigt – nemlig, intuitiv fysik og intuitiv psykologi.
Disse intuitionsmodeller, som er blevet observeret hos mennesker fra tidlige udviklingsstadier, kan være kernefacilitatorerne for fremtidig læring. Baseret på denne idé, forskere ved Korea Advanced Institute of Science and Technology (KAIST) har for nylig udviklet en iboende belønningsnormaliseringsmetode, der giver AI-agenter mulighed for at vælge handlinger, der forbedrer deres intuitionsmodeller mest. I deres papir, forudgivet på arXiv, forskerne foreslog specifikt et grafisk fysiknetværk integreret med dyb forstærkningslæring inspireret af den indlæringsadfærd, der observeres hos menneskelige spædbørn.
"Forestil dig menneskelige spædbørn i et rum med legetøj liggende i en tilgængelig afstand, " forklarer forskerne i deres papir. "De griber konstant, kaste og udføre handlinger på genstande; Sommetider, de observerer følgerne af deres handlinger, men nogle gange, de mister interessen og går videre til et andet objekt. Synet på 'barn som videnskabsmand' antyder, at menneskelige spædbørn er iboende motiverede til at udføre deres egne eksperimenter, finde mere information, og til sidst lære at skelne forskellige objekter og skabe rigere interne repræsentationer af dem."
Psykologiske undersøgelser tyder på, at i deres første leveår, mennesker eksperimenterer konstant med deres omgivelser, og dette giver dem mulighed for at danne en nøgleforståelse af verden. I øvrigt, når børn observerer resultater, der ikke lever op til deres forudgående forventninger, hvilket er kendt som forventningsbrud, de opfordres ofte til at eksperimentere yderligere for at opnå en bedre forståelse af den situation, de er i.
Holdet af forskere ved KAIST forsøgte at reproducere denne adfærd i AI-agenter ved hjælp af en forstærkningslæringstilgang. I deres undersøgelse, de introducerede først et grafisk fysiknetværk, der kan udtrække fysiske relationer mellem objekter og forudsige deres efterfølgende adfærd i et 3-D-miljø. Efterfølgende de integrerede dette netværk med en dyb-forstærkende læringsmodel, introduktion af en iboende belønningsnormaliseringsteknik, der tilskynder en AI-agent til at udforske og identificere handlinger, der løbende vil forbedre dens intuitionsmodel.
Ved hjælp af en 3-D fysikmotor, forskerne demonstrerede, at deres grafiske fysiknetværk effektivt kan udlede forskellige objekters positioner og hastigheder. De fandt også ud af, at deres tilgang tillod det dybe forstærkende læringsnetværk til løbende at forbedre sin intuitionsmodel, opmuntre det til at interagere med objekter udelukkende baseret på indre motivation.
I en række evalueringer, den nye teknik udviklet af dette team af forskere opnåede bemærkelsesværdig nøjagtighed, med AI-agenten, der udfører et større antal forskellige udforskende handlinger. I fremtiden, det kunne informere udviklingen af maskinlæringsværktøjer, der kan lære af deres tidligere erfaringer hurtigere og mere effektivt.
"Vi har testet vores netværk på både stationære og ikke-stationære problemer i forskellige scener med sfæriske objekter med varierende masser og radier, " forklarer forskerne i deres papir. "Vores håb er, at disse fortrænede intuitionsmodeller senere vil blive brugt som en forudgående viden til andre målorienterede opgaver såsom ATARI-spil eller videoforudsigelse."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Cyberværktøjssæt en komplet pakke til detektiver, virksomhederPurdue Toolkit til selektiv analyse og rekonstruktion af filer (FileTSAR) samler i én komplet pakke de bedste open source-efterforskningsværktøjer, der bruges af digitale retsmedicinske retshåndhævels
Cyberværktøjssæt en komplet pakke til detektiver, virksomhederPurdue Toolkit til selektiv analyse og rekonstruktion af filer (FileTSAR) samler i én komplet pakke de bedste open source-efterforskningsværktøjer, der bruges af digitale retsmedicinske retshåndhævels -
 Det britiske bilsalg ramte det seksårige lavt niveau i 2019:branchens organMange biler, færre købere Det nye britiske bilsalg sank i 2019 til et laveste niveau på seks år på grund af en svag efterspørgsel efter dieselmotorer med høj forurening og blandt Brexit-usikkerhed
Det britiske bilsalg ramte det seksårige lavt niveau i 2019:branchens organMange biler, færre købere Det nye britiske bilsalg sank i 2019 til et laveste niveau på seks år på grund af en svag efterspørgsel efter dieselmotorer med høj forurening og blandt Brexit-usikkerhed -
 Fiat Chrysler får et svagere salg højere nettoresultatFiat Chrysler -salget faldt i andet kvartal 2019, men gruppen formåede stadig at bogføre et højere nettoresultat, eksklusive ekstraordinære varer Fiat Chrysler (FCA) er blevet ramt af et faldende
Fiat Chrysler får et svagere salg højere nettoresultatFiat Chrysler -salget faldt i andet kvartal 2019, men gruppen formåede stadig at bogføre et højere nettoresultat, eksklusive ekstraordinære varer Fiat Chrysler (FCA) er blevet ramt af et faldende -
 Kønsneutrale emojis ramte skærme i den nye Apple -opdateringApples kønsneutrale emojis har hårklipp, tøj eller ansigtsstrukturer, der adskiller sig fra de mandlige og kvindelige Apple har udsendt nye kønsneutrale emojis for de fleste af sine ikoner - herun
Kønsneutrale emojis ramte skærme i den nye Apple -opdateringApples kønsneutrale emojis har hårklipp, tøj eller ansigtsstrukturer, der adskiller sig fra de mandlige og kvindelige Apple har udsendt nye kønsneutrale emojis for de fleste af sine ikoner - herun
- Sådan beregnes koncentration i PPM
- Brexit ændrede folks opfattelse af immigranter til det bedre
- Design af komplekse strukturer ud over mulighederne for konventionel litografi
- Forskere udvikler briller til røntgenlasere
- Berigelsesprogrammet øger STEM for sorte studerende, men efterlader latinere
- Hvordan og hvornår blev kulstof fordelt på jorden?