


En model til at bestemme virkningen af DDoS-angreb ved hjælp af Twitter-data
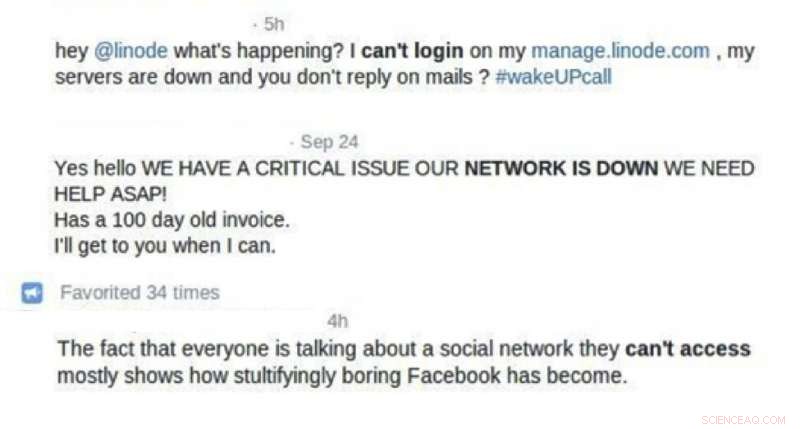
Et eksempel på tweets, der inspirerede forskningsstudiet. Kredit:Zhang et al.
Distributed denial of service (DDoS) angreb, som er designet til at forhindre legitime brugere i at få adgang til specifikke netværkssystemer, er blevet mere og mere almindelige i løbet af det seneste årti eller deromkring. Disse angreb gør tjenester som Facebook, Reddit og netbankwebsteder ekstremt langsomme eller umulige at bruge på grund af udmattende netværks- eller serverressourcer (f.eks. båndbredde, CPU og hukommelse).
Forskere verden over har forsøgt at udvikle teknikker til at forhindre DDoS-angreb eller hurtigt gribe ind for at reducere deres negative virkninger. Et vigtigt skridt i at modvirke sådanne angreb er den hurtige indsamling af feedback fra brugerne for at bestemme deres indvirkning og komme med målrettede løsninger.
Med det i tankerne, et team af forskere ved University of Maryland har udviklet en maskinlæringsmodel, der kan hjælpe med at bestemme omfanget af virkningen af DoS-angreb, mens de finder sted baseret på tweets, som er sendt af brugere. Deres studie, for nylig forudgivet på arXiv, blev finansieret af et UMBC-USNA Cyber Innovation Grant.
"Undersøgelsen var baseret på den observation, at når der er vanskeligheder med at få adgang til netværkstjenester, kunder deler nogle gange disse oplysninger på sociale netværk, "Dr. Tim Oates, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Vores hovedmål var at udvikle et system, der sporer netværksdenial-of-service-angreb (DoS) ved at analysere deres ringvirkninger gennem opslag på sociale medier."
Til at starte med, Dr. Oates og hans kolleger indsamlede et kurateret sæt tweets om DoS-angreb baseret på en historisk tidslinje over angreb, der fandt sted i fortiden. Ser man på disse tweets, hvor brugerne beskrev de problemer, de oplevede under et angreb, forskerne var i stand til at identificere 'sprogmønstre' (dvs. relevante søgeord). De trænede derefter en beslutningstræklassificering til at opdage DDoS-angreb baseret på disse nøgleord.
"Vi antog, at påvirkede kunder bruger lignende sprog på sociale medier til at beskrive problemer under et DDoS-angreb, såsom at systemet eller produktet er langsomt eller kravler, "Chi Zhang, en anden forsker involveret i undersøgelsen fortalte TechXplore. "Dermed, når nye tweets indsamles (historisk eller i realtid), Modellen finder først ud af emnerne (et sæt nøgleord, der bredt definerer et diskussionsområde) for de tweets, der er indsamlet i det tidsvindue."
Efterfølgende klassificeringen udviklet af Dr. Oates, Zhang og deres kolleger rangerer tweets baseret på, hvor meget nøgleordene afveg fra sprogmønstre observeret i brugerindlæg under tidligere DDoS-angreb. Endelig, modellen bruger antallet af detekterede DDos-relaterede tweets til at beregne omfanget af virkningen af et angreb.
Da forskerne vurderede deres model, de fandt ud af, at den opnåede lignende resultater som overvågede avancerede tilgange til at bestemme omfanget af DDoS-angreb. En stor fordel ved deres klassificering, imidlertid, er, at det er svagt overvåget, det kræver derfor meget lidt menneskelig mærkning af træningsdata.
"Vi var i stand til at udvikle en svagt overvåget model til ny hændelsesdetektion, der præsterer næsten lige så godt som overvågede modeller, " sagde Zhang. "Dens svagt overvågede natur betyder, at der kun er brug for en lille mængde menneskemærkede data, dermed sparer det en masse ressourcer i form af menneskelig arbejdskraft, da det typisk er ret dyrt at bede folk om at kommentere potentielt tusindvis af tweets."
I fremtiden, deres svagt overvågede model kunne hjælpe med at bestemme omfanget af DDoS-angreb hurtigt og mere effektivt, udelukkende baseret på Twitter-data. Den kan også tilpasses og anvendes til andre opgaver, der kan drage fordel af analysen af bruger-tweets i realtid.
I deres næste studier, forskerne planlægger at udvikle deres model yderligere for at analysere tweets skrevet på andre sprog. Til sidst, de vil også gerne ændre dets klassifikationslag for at teste dets ydeevne til at bestemme omfanget af virkningen af andre typer begivenheder, såsom sygdomsudbrud (f.eks. ebola).
"Vi indså, at folk har mange måder at beskrive problemer på Twitter, "Ashwinkumar Ganesan, en anden forsker, der udførte undersøgelsen, fortalte TechXplore. "Derfor, der er behov for at bygge en større cache af tweets og bedre modeller, der håndterer denne variation i sproget. Ud over, angreb er ikke begrænset til mål i den engelsktalende verden, så det er også meget vigtigt at designe systemet, så det kan skaleres til andre sprog."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Dieselgate ser Toyota vinde i EuropaToyota er kommet frem som en klar vinder af dieselgate-skandalen En bilindustri, der vender sig væk fra diesel og europæiske bilister, der i stigende grad foretrækker hybridbiler:læg det sammen, o
Dieselgate ser Toyota vinde i EuropaToyota er kommet frem som en klar vinder af dieselgate-skandalen En bilindustri, der vender sig væk fra diesel og europæiske bilister, der i stigende grad foretrækker hybridbiler:læg det sammen, o -
 Giv det videre:Råd om arbejdsliv fra Twitter-kurationsdirektørPå dette udaterede billede leveret af Twitter poserer virksomhedens kuratordirektør Joanna Geary til et billede. Geary talte med The Associated Press om at tjene et globalt publikum, som er Twitter. (
Giv det videre:Råd om arbejdsliv fra Twitter-kurationsdirektørPå dette udaterede billede leveret af Twitter poserer virksomhedens kuratordirektør Joanna Geary til et billede. Geary talte med The Associated Press om at tjene et globalt publikum, som er Twitter. ( -
 Udskiftning af diesel med flydende natur fører til en brændstoføkonomi på op til 60%Kredit:CC0 Public Domain Substitutionen af dieselolie med flydende naturgas (LNG) til godstransport i São Paulo vil muligvis føre til en betydelig reduktion i brændstofomkostninger og drivhusgas
Udskiftning af diesel med flydende natur fører til en brændstoføkonomi på op til 60%Kredit:CC0 Public Domain Substitutionen af dieselolie med flydende naturgas (LNG) til godstransport i São Paulo vil muligvis føre til en betydelig reduktion i brændstofomkostninger og drivhusgas -
 En ny tilgang til at opdage visuelle mønstre i kunstsamlingerKredit:Shen, Efros &Aubry. Forskere ved UC Berkeley og Ecole des Ponts Paris Tech har for nylig udviklet en dyb læringstilgang til at opdage tilbagevendende visuelle mønstre i kunstsamlinger. Dere
En ny tilgang til at opdage visuelle mønstre i kunstsamlingerKredit:Shen, Efros &Aubry. Forskere ved UC Berkeley og Ecole des Ponts Paris Tech har for nylig udviklet en dyb læringstilgang til at opdage tilbagevendende visuelle mønstre i kunstsamlinger. Dere
- Undersøgelse finder, at kuldioxidemissioner fra Amazonfloden næsten balancerer jordbaseret optagel…
- Når temperaturen stiger, det samme gør kriminaliteten:beviser fra Sydafrika
- Hvad er Silikatforvitring?
- DHS trækker sig tilbage om mulig ansigtsscreening af amerikanske borgere
- Konsekvent varmere vejr betyder, at høstsæsonen kommer tidligt
- Ledere værdsat over ledere, uanset pasform