


Talegenkendelse ved hjælp af kunstige neurale netværk og kunstig bikolonioptimering
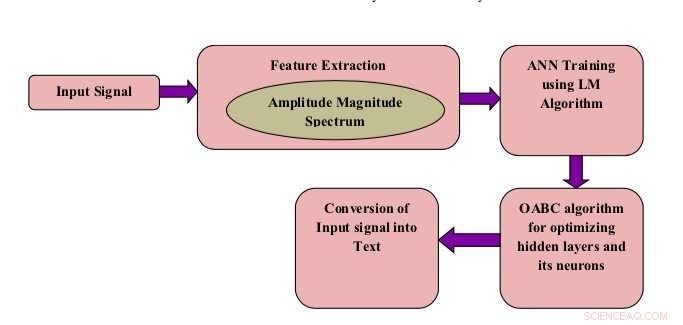
Blokdiagram af foreslået model. Kredit:Shukla &Jain.
I løbet af det seneste årti eller deromkring, fremskridt inden for maskinlæring har banet vejen for udviklingen af stadigt mere avancerede talegenkendelsesværktøjer. Ved at analysere lydfiler af menneskelig tale, disse værktøjer kan lære at identificere ord og sætninger på forskellige sprog, konvertere dem til et maskinlæsbart format.
Mens flere maskinlæringsbaserede modeller har opnået lovende resultater på talegenkendelsesopgaver, de klarer sig ikke altid godt på alle sprog. For eksempel, når et sprog har et ordforråd med mange enslydende ord, ydeevnen af talegenkendelsessystemer kan falde betydeligt.
Forskere ved Mahatma Gandhi Missions College of Engineering &Technology og Jaypee Institute of Information Technology, i Indien, har udviklet et talegenkendelsessystem til at løse dette problem. Dette nye system, præsenteret i et papir offentliggjort i Springer Link's International Journal of Speech Technology , kombinerer et kunstigt neuralt netværk (ANN) med en optimeringsteknik kendt som opposition kunstig bikoloni (OABC).
"I dette arbejde, standardstrukturen af ANN'er er redesignet ved hjælp af Levenberg-Marquardt-algoritmen for at hente en optimal forudsigelseshastighed med nøjagtighed, " skrev forskerne i deres papir. "De skjulte lag og neuroner i de skjulte lag er yderligere optimeret ved hjælp af oppositionens kunstige bikolonioptimeringsteknik."
Et unikt kendetegn ved systemet udviklet af forskerne er, at det bruger en OABC-optimeringsalgoritme til at optimere ANN's lag og kunstige neuroner. Som navnet antyder, kunstige bikolonier (ABC) algoritmer er designet til at simulere honningbiers adfærd for at tackle en række optimeringsproblemer.
"Generelt, optimeringsalgoritmer initialiserer tilfældigt løsningerne i det matchende domæne, " forklarede forskerne i deres papir. "Men denne løsning kunne ligge i den modsatte retning af den bedste løsning, og derved øger de beregningsmæssige overhead betydeligt. Derfor betegnes denne oppositionsbaserede initialisering som OABC."
Systemet udviklet af forskerne betragter individuelle ord, der er talt af forskellige mennesker, som et input-talesignal. Efterfølgende det ekstraherer såkaldte amplitudemodulations (AM) spektrogramfunktioner, som i det væsentlige er lydspecifikke egenskaber.
De funktioner, som modellen uddrager, bruges derefter til at træne ANN i at genkende menneskelig tale. Efter at den er trænet i en stor database med lydfiler, ANN lærer at forudsige isolerede ord i nye prøver af menneskelig tale.
Forskerne testede deres system på en række menneskelige talelydklip og sammenlignede det med mere konventionelle talegenkendelsesteknikker. Deres teknik overgik alle de andre metoder, opnå bemærkelsesværdige nøjagtighedsscore.
"Følsomheden, specificitet, og nøjagtigheden af den foreslåede metode er 90,41 procent, 99,66 procent og 99,36 procent, henholdsvis, hvilket er bedre end alle de eksisterende metoder, " skrev forskerne i deres papir.
I fremtiden, talegenkendelsessystemet kunne bruges til at opnå mere effektiv menneske-maskine kommunikation i en række forskellige indstillinger. Ud over, den tilgang, de brugte til at udvikle systemet, kunne inspirere andre teams til at designe lignende modeller, som kombinerer ANN'er og OABC-optimeringsteknikker.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Atomsprænghoveder? Denne robot kan finde demDetektorrobot i PPPL-gang før neutrontest. Bag robot fra venstre, Harry Fetsch, Science Undergraduate Laboratory Intern (SULI) og Rob Goldston, co-principal investigator af projektet. Kredit:Elle Star
Atomsprænghoveder? Denne robot kan finde demDetektorrobot i PPPL-gang før neutrontest. Bag robot fra venstre, Harry Fetsch, Science Undergraduate Laboratory Intern (SULI) og Rob Goldston, co-principal investigator af projektet. Kredit:Elle Star -
 Ny 3D-udskrivningsteknik muliggør hurtigere, bedre, og billigere modeller af patientspecifikke medi…Denne 3D-printede model af Steven Keatings kranium og hjerne viser tydeligt hans hjernesvulst og andre fine detaljer takket være den nye databehandlingsmetode, som undersøgelsens forfattere var banebr
Ny 3D-udskrivningsteknik muliggør hurtigere, bedre, og billigere modeller af patientspecifikke medi…Denne 3D-printede model af Steven Keatings kranium og hjerne viser tydeligt hans hjernesvulst og andre fine detaljer takket være den nye databehandlingsmetode, som undersøgelsens forfattere var banebr -
 Hvor meget altseende AI-overvågning er for meget?I denne 23. april, 2018, Foto, Ashley McManus, global marketingdirektør i det Boston-baserede kunstige intelligensfirma, Affektive, demonstrerer ansigtsgenkendelsesteknologi, der er beregnet til at hj
Hvor meget altseende AI-overvågning er for meget?I denne 23. april, 2018, Foto, Ashley McManus, global marketingdirektør i det Boston-baserede kunstige intelligensfirma, Affektive, demonstrerer ansigtsgenkendelsesteknologi, der er beregnet til at hj -
 Jilted Fujifilm sagsøger Xerox for 1 mia. USD efter afbrudt fusionFujifilm kræver mere end 1 mia. USD i erstatning Den japanske teknologigigant Fujifilm sagde tirsdag, at den sagsøgte det amerikanske firma Xerox. søger mere end 1 milliard dollars i erstatning ef
Jilted Fujifilm sagsøger Xerox for 1 mia. USD efter afbrudt fusionFujifilm kræver mere end 1 mia. USD i erstatning Den japanske teknologigigant Fujifilm sagde tirsdag, at den sagsøgte det amerikanske firma Xerox. søger mere end 1 milliard dollars i erstatning ef
- Synchrotron kaster lys over den amfibiske livsstil af en ny raptorial dinosaur
- Delhi halvmaraton for at gå videre trods smog, domstolsregler
- NASAs Operation IceBridge afslutter 11 års polarundersøgelser
- Sådan fungerer Sarin
- Hvor gamle forbindelser kunne blive morgendagens livreddere
- En ny maskinlæringsmetode kunne superlade batteriudviklingen til elektriske køretøjer