


Nvidia udarbejder en hurtig proces for at vise 3-D-modeller fra 2-D-billeder
Kredit:Nvidia
Målet:At ændre 2-D-billeder til 3-D-modeller ved hjælp af en speciel encoder-decoder-arkitektur. Skuespillerne:Nvidia. Ros:En smart udnyttelse af maskinlæring med gavnlige applikationer fra den virkelige verden.
Paul Lilly ind Varm hardware var blandt de tekniske iagttagere, der gjorde opmærksom på, at den måde, de gik fra 2-D-til-3-D på, var nyheder. Det er ikke nogen stor overraskelse, når vejen er den omvendte – 3-D til 2-D – men "at skabe en 3-D-model uden at fodre et system med 3D-data er langt mere udfordrende."
Lilly citerede Jun Gao, en fra forskerholdet, der arbejdede på gengivelsesmetoden. "Dette er i bund og grund første gang nogensinde, at du kan tage stort set ethvert 2-D-billede og forudsige relevante 3-D-egenskaber."
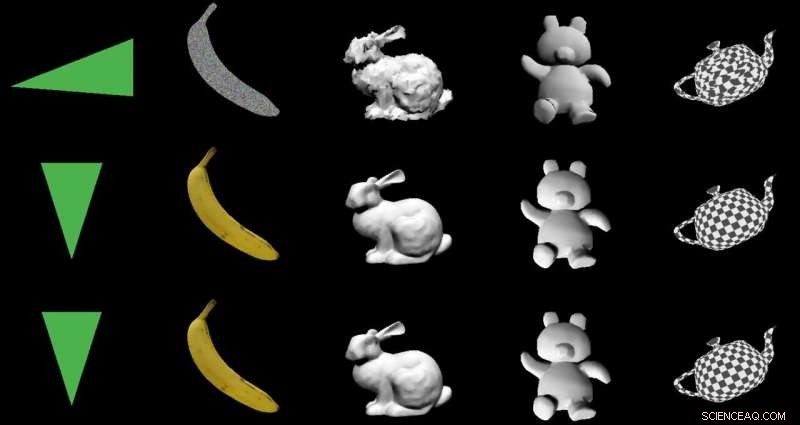
Deres magiske sauce til at producere et 3-D objekt fra 2-D billeder er en "differentierbar interpolationsbaseret renderer, " eller DIB-R. Forskerne på Nvidia trænede deres model på datasæt, der inkluderede fuglebilleder. Efter træning, DIB-R havde en evne til at tage et fuglebillede og levere en 3D-skildring, med den rigtige form og tekstur af en 3-D fugl.
Nvidia beskrev yderligere input transformeret til et feature map eller vektor, der bruges til at forudsige specifik information såsom form, farve, tekstur og belysning af et billede.
Hvorfor dette betyder noget: Gizmodo 's overskrift opsummerede det. "Nvidia lærte en kunstig intelligens til øjeblikkeligt at generere fuldt teksturerede 3-D-modeller fra flade 2-D-billeder." Det ord "øjeblikkeligt" er vigtigt.
DIB-R kan producere et 3-D objekt fra et 2-D billede på mindre end 100 millisekunder, sagde Nvidias Lauren Finkle. "Det gør det ved at ændre en polygonkugle - den traditionelle skabelon, der repræsenterer en 3-D-form. DIB-R ændrer den, så den matcher den virkelige objektform, der er portrætteret i 2-D-billederne."
Andrew Liszewski i Gizmodo fremhævede dette tidselement på 100 millisekunder. "Denne imponerende behandlingshastighed er det, der gør dette værktøj særligt interessant, fordi det har potentialet til at forbedre, hvordan maskiner kan lide robotter, eller selvkørende biler, se verden, og forstå, hvad der ligger foran dem."
Med hensyn til autonome biler, Liszewski sagde, "Stillbilleder hentet fra en live videostream fra et kamera kunne øjeblikkeligt konverteres til 3D-modeller, hvilket muliggør en autonom bil, for eksempel, for nøjagtigt at måle størrelsen på en stor lastbil, den skal undgå."

Holdet testede DIB-R på fire 2D-billeder af fugle (yderst til venstre). Det første eksperiment brugte et billede af en gul sanger (øverst til venstre) og producerede et 3D-objekt (øverste to rækker). Kredit:Nvidia
En model, der kunne udlede et 3-D-objekt fra et 2-D-billede, ville være i stand til at udføre bedre objektsporing, og Lilly vendte sig til at tænke på dets anvendelse i robotteknologi. "Ved at behandle 2-D-billeder til 3-D-modeller, en autonom robot ville være i en bedre position til at interagere med sit miljø mere sikkert og effektivt, " han sagde.
Nvidia bemærkede, at autonome robotter, for at gøre det, "skal være i stand til at fornemme og forstå sine omgivelser. DIB-R kunne potentielt forbedre disse dybdeopfattelsesevner."
Gizmodo 's Liszewski, i mellemtiden, nævnt, hvad Nvidia-tilgangen kunne gøre for sikkerheden. "DIB-R kunne endda forbedre ydeevnen af sikkerhedskameraer, der har til opgave at identificere personer og spore dem, da en øjeblikkeligt genereret 3D-model ville gøre det lettere at udføre billedmatches, når en person bevæger sig gennem sit synsfelt."
Nvidia-forskere vil præsentere deres model i denne måned på den årlige konference om neurale informationsbehandlingssystemer (NeurIPS), i Vancouver.
De, der ønsker at lære mere om deres forskning, kan tjekke deres papir på arXiv, "Lær at forudsige 3D-objekter med en interpolationsbaseret differentierbar renderer." Forfatterne er Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson og Sanja Fidler.
De foreslog "en komplet rasteriseringsbaseret differentierbar renderer, for hvilken gradienter kan beregnes analytisk." Når det er viklet omkring et neuralt netværk, deres rammer lærte at forudsige form, struktur, og lys fra enkelte billeder, de sagde, og de fremviste deres rammer "for at lære en generator af 3-D teksturerede former."
I deres abstrakte, Forfatterne observerede, at "Mange maskinlæringsmodeller opererer på billeder, men ignorer det faktum, at billeder er 2-D projektioner dannet af 3-D geometri, der interagerer med lys, i en proces kaldet rendering. At gøre det muligt for ML-modeller at forstå billeddannelse kan være nøglen til generalisering."
De præsenterede DIB-R som en ramme, der tillader gradienter at blive analytisk beregnet for alle pixels i et billede.
De sagde, at nøglen til deres tilgang var "at se forgrundsrasterisering som en vægtet interpolation af lokale egenskaber og baggrundsrasterisering som en afstandsbaseret aggregering af global geometri. Vores tilgang giver mulighed for nøjagtig optimering over toppunktspositioner, farver, normale, lysretninger og teksturkoordinater gennem en række forskellige belysningsmodeller."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 H2 Power, opstart af brintbrændstof, licenserer ny formel fra Army Research LabDr. Anit Giri, en fysiker fra US Army Research Laboratory, observerer en prøve af et unikt aluminiumsnanomaterialepulver, der reagerer med vand for at producere brint. Kredit:David McNally/Army Resear
H2 Power, opstart af brintbrændstof, licenserer ny formel fra Army Research LabDr. Anit Giri, en fysiker fra US Army Research Laboratory, observerer en prøve af et unikt aluminiumsnanomaterialepulver, der reagerer med vand for at producere brint. Kredit:David McNally/Army Resear -
 Britisk farm går ind i ny teknologi med 5G-halsbånd på køerPå dette billede taget i onsdags, 28. august, 2019, projektleder Duncan Forbes holder en smartphone, der viser biometriske data om sine køer i Agri-EPI Centre, et mejeriudviklingscenter i Shepton Mall
Britisk farm går ind i ny teknologi med 5G-halsbånd på køerPå dette billede taget i onsdags, 28. august, 2019, projektleder Duncan Forbes holder en smartphone, der viser biometriske data om sine køer i Agri-EPI Centre, et mejeriudviklingscenter i Shepton Mall -
 Robotel:Japansk hotel bemandet af robotdinosaurerDinosaurrobotter venter på at tjekke kunder ind på Henn na-hotellet Receptionen på Henn na Hotel øst for Tokyo er uhyggeligt stille, indtil kunderne nærmer sig robotdinosaurerne, der bemander rece
Robotel:Japansk hotel bemandet af robotdinosaurerDinosaurrobotter venter på at tjekke kunder ind på Henn na-hotellet Receptionen på Henn na Hotel øst for Tokyo er uhyggeligt stille, indtil kunderne nærmer sig robotdinosaurerne, der bemander rece -
 Uber-aktien skal lanceres til $45 per aktie (opdatering)Ubers Wall Street-debut er en milepæl for ride-hailing-sektoren, men risici omfatter klager over virksomhedens forretningsmodel med at bruge uafhængige entreprenører Uber er klar til sin Wall Stre
Uber-aktien skal lanceres til $45 per aktie (opdatering)Ubers Wall Street-debut er en milepæl for ride-hailing-sektoren, men risici omfatter klager over virksomhedens forretningsmodel med at bruge uafhængige entreprenører Uber er klar til sin Wall Stre
- En biologisk tilgang til præcisionsmedicin retter sig mod et uendeligt antal sygdomme
- Hunde plejede at snuse ud sjældne arter
- Forskere opretter en fungerende Mott -transistorprototype
- Bekæmpelse af kræft ved nulpunktet med designermolekyler
- 3-D berøringsfri interaktiv skærm registrerer fingerfugtighed for at skifte farve
- Undersøgelse af virkningen af COVID-19-pandemien på det amerikanske vestlige landdistrikt