


Efterhånden som naturlige sprogbehandlingsteknikker forbedres, forslag bliver hurtigere og mere relevante
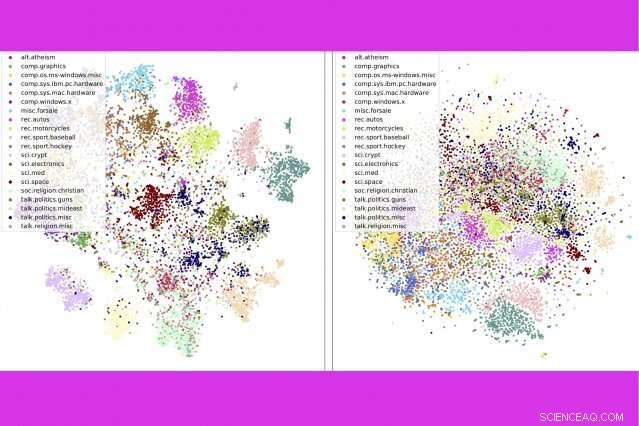
I en ny undersøgelse, forskere ved MIT og IBM kombinerer tre populære tekstanalyseværktøjer - emnemodellering, ordindlejringer, og optimal transport — for at sammenligne tusindvis af dokumenter i sekundet. Her, de viser, at deres metode (venstre) grupperer nyhedsgruppeindlæg efter kategori mere stramt end en konkurrerende metode. Kredit:Massachusetts Institute of Technology
Med milliarder af bøger, nyhedshistorier, og dokumenter online, der har aldrig været et bedre tidspunkt at læse – hvis du har tid til at gennemskue alle mulighederne. "Der er masser af tekst på internettet, " siger Justin Solomon, en adjunkt ved MIT. "Alt, der hjælper med at skære igennem alt det materiale, er ekstremt nyttigt."
Med MIT-IBM Watson AI Lab og hans Geometric Data Processing Group på MIT, Solomon præsenterede for nylig en ny teknik til at skære igennem enorme mængder tekst på konferencen om neurale informationsbehandlingssystemer (NeurIPS). Deres metode kombinerer tre populære tekstanalyseværktøjer - emnemodellering, ordindlejringer, og optimal transport - for at levere bedre, hurtigere resultater end konkurrerende metoder på et populært benchmark til klassificering af dokumenter.
Hvis en algoritme ved, hvad du kunne lide tidligere, den kan scanne de millioner af muligheder for noget lignende. Efterhånden som naturlige sprogbehandlingsteknikker forbedres, disse "du måske også synes om" forslag bliver hurtigere og mere relevante.
I metoden præsenteret på NeurIPS, en algoritme opsummerer en samling af, sige, bøger, til emner baseret på almindeligt anvendte ord i samlingen. Den opdeler derefter hver bog i dens fem til 15 vigtigste emner, med et skøn over, hvor meget hvert emne samlet set bidrager til bogen.
For at sammenligne bøger, forskerne bruger to andre værktøjer:ordindlejringer, en teknik, der forvandler ord til lister over tal for at afspejle deres lighed i populær brug, og optimal transport, en ramme til at beregne den mest effektive måde at flytte objekter - eller datapunkter - mellem flere destinationer.
Ordindlejringer gør det muligt at udnytte optimal transport to gange:først for at sammenligne emner inden for samlingen som helhed, og så, i ethvert par bøger, at måle, hvor tæt fælles temaer overlapper hinanden.
Teknikken fungerer især godt ved scanning af store samlinger af bøger og lange dokumenter. I undersøgelsen, forskerne giver eksemplet med Frank Stocktons "The Great War Syndicate, " en amerikansk roman fra det 19. århundrede, der forudså fremkomsten af atomvåben. Hvis du leder efter en lignende bog, en emnemodel ville hjælpe med at identificere de dominerende temaer, der deles med andre bøger – i dette tilfælde, nautiske, elementært, og martial.
Men en emnemodel alene ville ikke identificere Thomas Huxleys forelæsning fra 1863, "Den organiske naturs tidligere tilstand, "som et godt match. Forfatteren var en forkæmper for Charles Darwins evolutionsteori, og hans foredrag, krydret med omtaler af fossiler og sedimentation, afspejlede nye ideer om geologi. Når temaerne i Huxleys foredrag matches med Stocktons roman via optimal transport, nogle tværgående motiver dukker op:Huxleys geografi, flora/fauna, og videnstemaer er tæt på Stocktons nautiske, elementært, og kampsportstemaer, henholdsvis.
Modellering af bøger efter deres repræsentative emner, snarere end individuelle ord, gør sammenligninger på højt niveau mulig. "Hvis du beder nogen om at sammenligne to bøger, de opdeler hver enkelt i letforståelige begreber, og sammenligne derefter begreberne, " siger studiets hovedforfatter Mikhail Yurochkin, en forsker hos IBM.
Resultatet er hurtigere, mere præcise sammenligninger, viser undersøgelsen. Forskerne sammenlignede 1, 720 par bøger i Gutenberg Project-datasættet på et sekund - mere end 800 gange hurtigere end den næstbedste metode.
Teknikken gør også et bedre stykke arbejde med at sortere dokumenter nøjagtigt end rivaliserende metoder - f.eks. gruppering af bøger i Gutenberg-datasættet efter forfatter, produktanmeldelser på Amazon efter afdeling, og BBC-sportshistorier efter sport. I en række visualiseringer, forfatterne viser, at deres metode pænt klynger dokumenter efter type.
Ud over at kategorisere dokumenter hurtigt og mere præcist, metoden giver et vindue ind i modellens beslutningsproces. Gennem listen over emner, der vises, brugere kan se, hvorfor modellen anbefaler et dokument.
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT-forskning, innovation og undervisning.
Sidste artikelHonda selvkørende koncept tilbyder tænd og sluk-tilstande
Næste artikelRolls-Royce:Nul-emissionsfuglesæt til 2020
 Varme artikler
Varme artikler
-
 Renault-Nissan-Mitsubishi er fortsat den bedste bilgruppeRenault-Nissan-Mitsubishi-alliancen holdt snævert på pladsen som topsælgeren af biler sidste år Renault-Nissan-Mitsubishi-alliancen holdt snævert fast i sin plads som topsælgeren af biler sids
Renault-Nissan-Mitsubishi er fortsat den bedste bilgruppeRenault-Nissan-Mitsubishi-alliancen holdt snævert på pladsen som topsælgeren af biler sidste år Renault-Nissan-Mitsubishi-alliancen holdt snævert fast i sin plads som topsælgeren af biler sids -
 Edmunds fremhæver de nyeste sikkerheds- og teknologitrendsDette udaterede billede leveret af Toyota, viser 2018 Lexus LS 500. Top-of-the-line Mercedes- og Lexus-køretøjer har automatisk styreundvigelse, hvilket betyder, at de automatisk kan svinge for at und
Edmunds fremhæver de nyeste sikkerheds- og teknologitrendsDette udaterede billede leveret af Toyota, viser 2018 Lexus LS 500. Top-of-the-line Mercedes- og Lexus-køretøjer har automatisk styreundvigelse, hvilket betyder, at de automatisk kan svinge for at und -
 Apple -patentsnak:Endnu en nøglefri undren, da bilen ser dig nærme digKredit:US20190039570 Ideer, klager og argumenter over de bedste sikre - og bekvemme - systemer til chaufførgodkendelse er lette at finde. Apple indgav for nogen tid siden et patent, der foreslår e
Apple -patentsnak:Endnu en nøglefri undren, da bilen ser dig nærme digKredit:US20190039570 Ideer, klager og argumenter over de bedste sikre - og bekvemme - systemer til chaufførgodkendelse er lette at finde. Apple indgav for nogen tid siden et patent, der foreslår e -
 Panasonic vil flytte britisk hovedkvarter om Brexit -frygtPanasonic planlægger at flytte sit europæiske hovedkvarter fra Storbritannien til Holland på grund af bekymring over potentielle skattespørgsmål i forbindelse med Brexit Panasonic planlægger at fl
Panasonic vil flytte britisk hovedkvarter om Brexit -frygtPanasonic planlægger at flytte sit europæiske hovedkvarter fra Storbritannien til Holland på grund af bekymring over potentielle skattespørgsmål i forbindelse med Brexit Panasonic planlægger at fl
- Klimatilpasning giver sundhedsmæssige fordele
- Social støttes rolle i forhold til vold i intim partnerskab og økonomiske vanskeligheder
- Sådan beregnes 2/3 af et nummer
- Syntetisering af sukker:Kemikere udvikler metode til at forenkle opbygning af kulhydrater
- Masseskattetricks kostede Europa 55 mia. euro:rapport
- Observation af topologiske magnon-isolatortilstande i et superledende kredsløb