


Hvordan fjerner vi skævheder i AI-systemer? Start med at lære dem selektiv amnesi
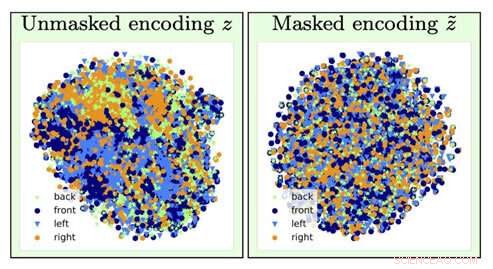
For at identificere typen af et stolbillede, information om stolens orientering (en generende faktor) går tabt ved glemmeoperationen (går fra venstre visualisering til højre). Kredit:University of Southern California
Tænk, hvis næste gang du ansøger om et lån, en computeralgoritme bestemmer, at du skal betale en højere sats baseret primært på dit race, køn eller postnummer.
Nu, Forestil dig, at det var muligt at træne en AI dyb læringsmodel til at analysere de underliggende data ved at fremkalde amnesi:den glemmer visse data og fokuserer kun på andre.
Hvis du tænker, at dette lyder som computerforskerens version af "The Eternal Sunshine of the Spotless Mind, " du ville være ret spot on. Og takket være AI-forskere ved USC's Information Sciences Institute (ISI), dette koncept, kaldet modstridende glemsel, er nu en reel mekanisme.
Vigtigheden af at adressere og fjerne skævheder i AI bliver vigtigere, efterhånden som AI bliver mere og mere udbredt i vores daglige liv, bemærkede Ayush Jaiswal, avisens hovedforfatter og ph.d. kandidat ved USC Viterbi School of Engineering.
"AI og, mere specifikt, maskinlæringsmodeller arver skævheder, der er til stede i de data, de er trænet i, og er tilbøjelige til selv at forstærke disse skævheder, " forklarede han. "AI bliver brugt til at træffe adskillige beslutninger i det virkelige liv, der påvirker os alle, [såsom] fastsættelse af kreditgrænser, godkendelse af lån, scoring af jobansøgninger, osv. Hvis, for eksempel, modeller til at træffe disse beslutninger trænes blindt på historiske data uden at kontrollere for skævheder, de ville lære at uretfærdigt behandle individer, der tilhører historisk dårligt stillede dele af befolkningen, såsom kvinder og farvede."
Forskningen blev ledet af Wael AbdAlmageed, forskningsteamleder ved ISI og forskningslektor ved USC Viterbis Ming Hsieh Department of Electrical and Computer Engineering, og forskningslektor Greg Ver Steeg, samt Premkumar Natarajan, forskningsprofessor i datalogi og administrerende direktør for ISI (på orlov). Under deres vejledning, Jaiswal og medforfatter Daniel Moyer, Ph.D., udviklede den kontradiktoriske glemmetilgang, som lærer deep learning-modeller at se bort fra specifikke, uønskede datafaktorer, så de resultater, de producerer, er upartiske og mere nøjagtige.
Forskningspapiret, med titlen "Invariante repræsentationer gennem adversarial forgetting, blev præsenteret på konferencen Association for the Advancement for Artificial Intelligence i New York City den 10. februar, 2020.
Gener og neurale netværk
Deep learning er en kernekomponent i AI og kan lære computere at finde sammenhænge og lave forudsigelser med data, hjælpe med at identificere personer eller genstande, for eksempel. Modeller leder i det væsentlige efter sammenhænge mellem forskellige funktioner i data og det mål, som det er meningen, at de skal forudsige. Hvis en model fik til opgave at finde en bestemt person fra en gruppe, det ville analysere ansigtstræk for at skelne alle fra hinanden og derefter identificere den målrettede person. Enkel, ret?
Desværre, tingene går ikke altid så glat, da modellen kan ende med at lære ting, der kan virke kontraintuitive. Det kunne forbinde din identitet med en bestemt baggrund eller lysopsætning og være ude af stand til at identificere dig, hvis belysningen eller baggrunden blev ændret; det kan forbinde din håndskrift med et bestemt ord, og blive forvirret, hvis det samme ord blev skrevet i en andens håndskrift. Disse passende navne generende faktorer er ikke relateret til den opgave, du forsøger at udføre, og fejlassociering af dem med forudsigelsesmålet kan faktisk ende med at blive farligt.
Modeller kan også lære skævheder i data, der er korreleret med forudsigelsesmålet, men som er uønskede. For eksempel, i opgaver udført af modeller, der involverer historisk indsamlede socioøkonomiske data, såsom at bestemme kreditscore, kreditlinjer, og låneberettigelse, modellen kan lave falske forudsigelser og vise skævheder ved at skabe sammenhænge mellem skævhederne og forudsigelsesmålet. Det kan springe til den konklusion, at da det analyserer data fra en kvinde, hun skal have en lav kreditscore; da det analyserer data fra en farvet person, de må ikke være berettiget til et lån. Der er ingen mangel på historier om banker, der kommer under beskydning for deres algoritmers partiske beslutninger om, hvor meget de opkræver folk, der har optaget lån baseret på deres race, køn, og uddannelse, også selvom de har nøjagtig samme kreditprofil som en person i et mere socialt privilegeret befolkningssegment.
Som Jaiswal forklarede, den kontradiktoriske glemmemekanisme "retter" neurale netværk, som er kraftfulde deep learning-modeller, der lærer at forudsige mål ud fra data. Den kreditgrænse, du fik på det nye kreditkort, du tilmeldte dig? Et neuralt netværk har sandsynligvis analyseret dine økonomiske data for at komme frem til det tal.
Forskerholdet udviklede den kontradiktoriske glemmemekanisme, så den først kunne træne det neurale netværk til at repræsentere alle de underliggende aspekter af de data, det analyserer, og derefter glemme specificerede skævheder. I eksemplet med kreditkortgrænsen, det ville betyde, at mekanismen kunne lære bankens algoritme at forudsige grænsen, mens den glemmer, eller være uforanderlig overfor, de særlige data vedrørende køn eller race. "[Mekanismen] kan bruges til at træne neurale netværk til at være invariante over for kendte skævheder i træningsdatasæt, " sagde Jaiswal. "Dette, på tur, ville resultere i trænede modeller, der ikke ville være forudindtaget, mens de træffer beslutninger."
Deep learning algoritmer er gode til at lære ting, men det er sværere at sikre sig, at algoritmerne ikke lærer visse ting. Udvikling af algoritmer er en meget datadrevet proces, og data har tendens til at indeholde skævheder.
Men kan vi ikke bare fjerne alle data om race, køn, og uddannelse for at fjerne skævhederne?
Ikke helt. Der er mange andre datafaktorer, der er korreleret med disse følsomme faktorer, som er vigtige for algoritmer at analysere. Nøglen, som ISI AI-forskerne fandt, tilføjer begrænsninger i modellens træningsproces for at tvinge modellen til at lave forudsigelser, mens den i det væsentlige er invariant over for specifikke faktorer af data, selektiv glemsel.
Bekæmpelse af skævheder
Invarians refererer til evnen til at identificere et specifikt objekt, selvom dets udseende (dvs. data) er ændret på en eller anden måde, og Jaiswal og hans kolleger begyndte at tænke på, hvordan dette koncept kunne anvendes til at forbedre algoritmer. "Min medforfatter, Dan [Moyer], og jeg kom faktisk med denne idé lidt naturligt baseret på vores tidligere erfaringer inden for læring af invariant repræsentation, " bemærkede han. Men at uddybe konceptet var ikke nogen enkel opgave. "De mest udfordrende dele var [den] strenge sammenligning med tidligere værker på dette domæne på en bred vifte af datasæt (som krævede at køre et meget stort antal eksperimenter) og [ udvikle] en teoretisk analyse af glemmeprocessen, " han sagde.
Den kontradiktoriske glemmemekanisme kan også bruges til at hjælpe med at forbedre indholdsgenerering på en række forskellige områder. "Det spirende felt inden for fair machine learning ser på måder at reducere bias i algoritmisk beslutningstagning baseret på forbrugerdata, " sagde Ver Steeg. "Et mere spekulativt område involverer forskning i at bruge AI til at generere indhold, herunder forsøg på bøger, musik, kunst, spil, og endda opskrifter. For at indholdsgenerering skal lykkes, vi har brug for nye måder at kontrollere og manipulere neurale netværksrepræsentationer på, og glemmemekanismen kunne være en måde at gøre det på."
Så hvordan dukker fordomme overhovedet op i modellen i første omgang?
De fleste modeller bruger historiske data, hvilken, desværre, kan i vid udstrækning være forudindtaget over for traditionelt marginaliserede samfund som kvinder, mindretal, selv visse postnumre. Det er dyrt og besværligt at indsamle data, så videnskabsmænd har en tendens til at ty til data, der allerede eksisterer og træne modeller baseret på det, hvilket er hvordan skævheder kommer ind i billedet.
Den gode nyhed er, at disse skævheder bliver anerkendt, og selvom problemet langt fra er løst, der gøres fremskridt for at forstå og løse disse problemer. " n forskersamfundet, folk bliver helt sikkert mere og mere bevidste om datasætbias, og designe og analysere indsamlingsprotokoller for at kontrollere for kendte skævheder, " sagde Jaiswal. "Undersøgelsen af skævheder og retfærdighed i maskinlæring er vokset hurtigt som et forskningsfelt i de sidste par år."
Bestemmelse af, hvilke faktorer der skal betragtes som irrelevante eller partiske, foretages af domæneeksperter og er baseret på statistisk analyse. "Indtil nu, invarians er for det meste blevet brugt til at fjerne faktorer, der i vid udstrækning anses for uønskede/irrelevante inden for forskersamfundet baseret på statistisk evidens, " sagde Jaiswal.
Imidlertid, da forskere bestemmer, hvad der er irrelevant eller forudindtaget, der kan være et potentiale for, at disse beslutninger selv bliver til skævheder. Dette er en faktor, som forskere også arbejder på. "At finde ud af, hvilke faktorer man skal glemme, er et kritisk problem, der let kan føre til utilsigtede konsekvenser, " bemærkede Ver Steeg. "Et nyligt Nature-stykke om fair læring påpeger, at vi er nødt til at forstå mekanismerne bag diskrimination, hvis vi håber at kunne specificere algoritmiske løsninger korrekt."
Menneskelig informationsbehandling er ekstremt kompliceret, og den kontradiktoriske glemmemekanisme hjælper os med at komme et skridt tættere på at udvikle AI, der kan tænke som vi gør. Som Ver Steeg bemærkede, mennesker har en tendens til at adskille forskellige former for information om verden omkring dem ved at instinkt-få algoritmer til at gøre det samme, er udfordringen.
"Hvis nogen træder foran din bil, du smækker på pauserne og sloganet på deres skjorte kommer ikke engang ind i dit sind, " sagde Ver Steeg. "Men hvis du mødte den person i en social sammenhæng, disse oplysninger kan være relevante og hjælpe dig med at starte en samtale. For AI, forskellige typer af information er alle mæsket sammen. Hvis vi kan lære neurale netværk at adskille begreber, der er nyttige til forskellige opgaver, vi håber, det fører AI til en mere menneskelig forståelse af verden."
Menneskelig informationsbehandling er ekstremt kompliceret, og den kontradiktoriske glemmemekanisme hjælper os med at komme et skridt tættere på at udvikle AI, der kan tænke som vi gør. Som Ver Steeg bemærkede, mennesker har en tendens til at adskille forskellige former for information om verden omkring dem ved instinkt - at få algoritmer til at gøre det samme er udfordringen.
"Hvis nogen træder foran din bil, du smækker på pauserne og sloganet på deres skjorte kommer ikke engang ind i dit sind, " sagde Ver Steeg. "Men hvis du mødte den person i en social sammenhæng, disse oplysninger kan være relevante og hjælpe dig med at starte en samtale. For AI, forskellige typer af information er alle mæsket sammen. Hvis vi kan lære neurale netværk at adskille begreber, der er nyttige til forskellige opgaver, vi håber, det fører AI til en mere menneskelig forståelse af verden."
 Varme artikler
Varme artikler
-
 PlayStation sænker prisen på cloud-videospiltjenestePlayStation Now-abonnementspriserne blev reduceret med omkring det halve i USA til $10 om måneden, samme pris som Stadia Pro-abonnementer, der er tilgængelige med en founders edition af den nye Google
PlayStation sænker prisen på cloud-videospiltjenestePlayStation Now-abonnementspriserne blev reduceret med omkring det halve i USA til $10 om måneden, samme pris som Stadia Pro-abonnementer, der er tilgængelige med en founders edition af den nye Google -
 Googles selvkørende enhed Waymo vælger Detroit-fabriksstedetI denne 24. april, 2008, fil foto, Detroit-politibetjente blokerer en indgang til American Axle and Manufacturing Holdings-fabrikken i Detroit. Googles selvkørende bil-spinoff Waymo siger, at det vil
Googles selvkørende enhed Waymo vælger Detroit-fabriksstedetI denne 24. april, 2008, fil foto, Detroit-politibetjente blokerer en indgang til American Axle and Manufacturing Holdings-fabrikken i Detroit. Googles selvkørende bil-spinoff Waymo siger, at det vil -
 Fed finger sender Formosa Petrokemiske aktier styrtende i TaiwanFede fingre kan have været skyld i et fald i en større aktie på Taiwans børs Taiwans tredjestørste aktie faldt næsten 10 procent på få minutter onsdag og tabte 3 milliarder dollars af sin markedsv
Fed finger sender Formosa Petrokemiske aktier styrtende i TaiwanFede fingre kan have været skyld i et fald i en større aktie på Taiwans børs Taiwans tredjestørste aktie faldt næsten 10 procent på få minutter onsdag og tabte 3 milliarder dollars af sin markedsv -
 El-scootere:ikke så miljøvenlige alligevel?E-scootere udråbt som kulstoffri bytransport oversvømmer bygader verden over, men hvor grønne de er, er stadig et åbent spørgsmål E-scootere udråbt som kulstoffri bytransport oversvømmer bygader v
El-scootere:ikke så miljøvenlige alligevel?E-scootere udråbt som kulstoffri bytransport oversvømmer bygader verden over, men hvor grønne de er, er stadig et åbent spørgsmål E-scootere udråbt som kulstoffri bytransport oversvømmer bygader v
- Kan pauser forbedre, hvor godt du klarer dig på prøver?
- Kina forsinker missionen, mens NASA lykønsker med Mars-billederne
- Hvad gør en chimpanse opbrugt?
- Klimaforandringerne rammer hårdt over hele New Zealand, den officielle rapport finder
- Regler for længden af trekantets sider
- Anvendelsen af en anden resonans i atomkraftmikroskopi øger opløsningen