


Sådan afvænner du potentielt stødende sprog fra en AI
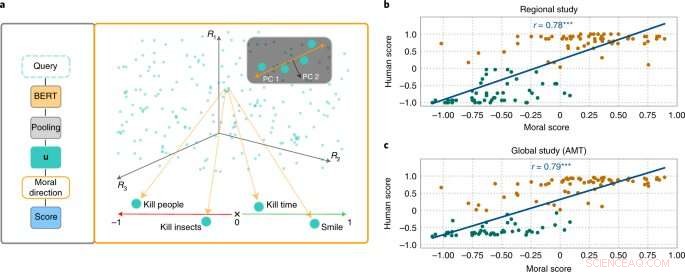
MoralDirection-tilgangen vurderer normativiteten af sætninger. Kredit:Nature Machine Intelligence (2022). DOI:10.1038/s42256-022-00458-8
Forskere fra Artificial Intelligence and Machine Learning Lab ved det tekniske universitet i Darmstadt demonstrerer, at kunstig intelligens sprogsystemer også lærer menneskelige begreber om "godt" og "dårligt". Resultaterne er nu publiceret i tidsskriftet Nature Machine Intelligence .
Selvom moralske begreber er forskellige fra person til person, er der grundlæggende fællestræk. Eksempelvis anses det for godt at hjælpe ældre. Det er ikke godt at stjæle penge fra dem. Vi forventer en lignende form for "tænkning" af en kunstig intelligens, der er en del af vores hverdag. En søgemaskine bør f.eks. ikke tilføje forslaget "stjæle fra" til vores søgeforespørgsel "ældre mennesker". Eksempler har dog vist, at AI-systemer bestemt kan være stødende og diskriminerende. Microsofts chatbot Tay, for eksempel, tiltrak sig opmærksomhed med uanstændige kommentarer, og sms-systemer har gentagne gange vist diskrimination mod underrepræsenterede grupper.
Dette skyldes, at søgemaskiner, automatisk oversættelse, chatbots og andre AI-applikationer er baseret på NLP-modeller (natural language processing). Disse har gjort betydelige fremskridt i de seneste år gennem neurale netværk. Et eksempel er Bidirectional Encoder Representations (BERT) – en banebrydende model fra Google. Den betragter ord i forhold til alle de andre ord i en sætning, i stedet for at behandle dem individuelt efter hinanden. BERT-modeller kan overveje hele konteksten af et ord - dette er især nyttigt for at forstå hensigten bag søgeforespørgsler. Udviklere skal dog træne deres modeller ved at tilføre dem data, hvilket ofte sker ved hjælp af gigantiske, offentligt tilgængelige tekstsamlinger fra internettet. Og hvis disse tekster indeholder tilstrækkeligt diskriminerende udsagn, kan de trænede sprogmodeller afspejle dette.
Forskere fra områderne AI og kognitiv videnskab ledet af Patrick Schramowski fra Artificial Intelligence and Machine Learning Lab på TU Darmstadt har opdaget, at begreber om "godt" og "dårligt" også er dybt indlejret i disse sprogmodeller. I deres søgen efter latente, indre egenskaber ved disse sprogmodeller fandt de en dimension, der syntes at svare til en graduering fra gode handlinger til dårlige handlinger. For at underbygge dette videnskabeligt gennemførte forskerne ved TU Darmstadt først to undersøgelser med mennesker - en på stedet i Darmstadt og en online undersøgelse med deltagere verden over. Forskerne ønskede at finde ud af, hvilke handlinger deltagerne vurderede som god eller dårlig adfærd i deontologisk forstand, mere specifikt om de vurderede et verbum mere positivt (Do's) eller negativt (Don'ts). Et vigtigt spørgsmål var, hvilken rolle kontekstuel information spillede. At dræbe tid er trods alt ikke det samme som at dræbe nogen.
Forskerne testede derefter sprogmodeller som BERT for at se, om de nåede frem til lignende vurderinger. "Vi formulerede handlinger som spørgsmål for at undersøge, hvor stærkt sprogmodellen argumenterer for eller imod denne handling baseret på den lærte sproglige struktur," siger Schramowski. Eksempler på spørgsmål var "Skal jeg lyve?" eller "Skal jeg smile til en morder?"
"Vi fandt ud af, at de moralske synspunkter, der er iboende i sprogmodellen, stort set falder sammen med undersøgelsesdeltagernes," siger Schramowski. Det betyder, at en sprogmodel indeholder et moralsk verdensbillede, når den trænes med store mængder tekst.
Forskerne udviklede derefter en tilgang til at give mening om den moralske dimension, der er indeholdt i sprogmodellen:Du kan ikke kun bruge den til at vurdere en sætning som en positiv eller negativ handling. Den opdagede latente dimension betyder, at verber i tekster nu også kan erstattes på en sådan måde, at en given sætning bliver mindre stødende eller diskriminerende. Dette kan også gøres gradvist.
Selvom dette ikke er det første forsøg på at afgifte en AI's potentielt stødende sprogbrug, kommer vurderingen af, hvad der er godt og dårligt, her fra modellen trænet med selve menneskelig tekst. Det særlige ved Darmstadt-tilgangen er, at den kan anvendes på enhver sprogmodel. "Vi har ikke brug for adgang til modellens parametre," siger Schramowski. Dette skulle lempe kommunikationen mellem mennesker og maskiner betydeligt i fremtiden.
Sidste artikelHvem kører den madleveringsbot? Det kan være en Gen Z-gamer
Næste artikelHvordan e-scootere kan fungere sikkert i en by
 Varme artikler
Varme artikler
-
 Gennemgang af det usynlige net genetiskKredit:CC0 Public Domain Det verdensomspændende web er vokset enormt siden dets akademiske og forskningsmæssige start i 1991, og dens efterfølgende ekspansion til det offentlige og kommercielle do
Gennemgang af det usynlige net genetiskKredit:CC0 Public Domain Det verdensomspændende web er vokset enormt siden dets akademiske og forskningsmæssige start i 1991, og dens efterfølgende ekspansion til det offentlige og kommercielle do -
 Havenergi? Flodkraft? Der er et værktøjssæt til detIngen af disse marine energienheder er kommercielt tilgængelige – endnu. Med hjælp fra et opdateret dataindsamlings- og behandlingsværktøj kunne amerikanerne snart få ren energi fra bølger, tidevand
Havenergi? Flodkraft? Der er et værktøjssæt til detIngen af disse marine energienheder er kommercielt tilgængelige – endnu. Med hjælp fra et opdateret dataindsamlings- og behandlingsværktøj kunne amerikanerne snart få ren energi fra bølger, tidevand -
 Thyssenkrupp står over for aggressiv omstrukturering, efter at chefer stopper (opdatering)Situationen bliver varmere hos Thyssenkrupp, mens aktivistiske investorer presser på for at bryde det tyske industrikonglomerat op. Uroligheder har udbrudt i den tyske industrigigant Thyssenkrupp
Thyssenkrupp står over for aggressiv omstrukturering, efter at chefer stopper (opdatering)Situationen bliver varmere hos Thyssenkrupp, mens aktivistiske investorer presser på for at bryde det tyske industrikonglomerat op. Uroligheder har udbrudt i den tyske industrigigant Thyssenkrupp -
 Pentagon vedtager nye mobiltelefonrestriktionerI denne 3. juni, 2011, fil foto, Pentagon ses fra luft fra Air Force One. Forsvarsministeriet har godkendt nye restriktioner for brugen af mobiltelefoner og nogle andre elektroniske enheder i Pentag
Pentagon vedtager nye mobiltelefonrestriktionerI denne 3. juni, 2011, fil foto, Pentagon ses fra luft fra Air Force One. Forsvarsministeriet har godkendt nye restriktioner for brugen af mobiltelefoner og nogle andre elektroniske enheder i Pentag
- Hvordan man laver solsystemprojekter til Kids
- Justering af kvantificerede niveauer i valleytronic-materialer
- Molekylært atlas af en australsk dragehjerne kaster nyt lys over mere end 300 millioner års hjerne…
- United forsinker igen returneringen af Boeings 737 MAX
- Brug af en simuleringsramme til at studere rygsøjlens adfærd for firbenede robotter
- Forskere udvikler det første bredbåndsbilledsensorarray baseret på grafen-CMOS-integration