


Udvikling af pålidelige kvantecomputere
Kvanteoptik og statistik. Kredit:University of Freiburg
Kvantecomputere kan en dag løse algoritmiske problemer, som selv de største supercomputere i dag ikke kan klare. Men hvordan tester du en kvantecomputer for at sikre, at den fungerer pålideligt? Afhængigt af den algoritmiske opgave, dette kan være et let eller et meget vanskeligt certificeringsproblem. Et internationalt team af forskere har taget et vigtigt skridt i retning af at løse en vanskelig variation af dette problem, ved hjælp af en statistisk tilgang udviklet ved universitetet i Freiburg. Resultaterne af deres undersøgelse er offentliggjort i den seneste udgave af Natur fotonik .
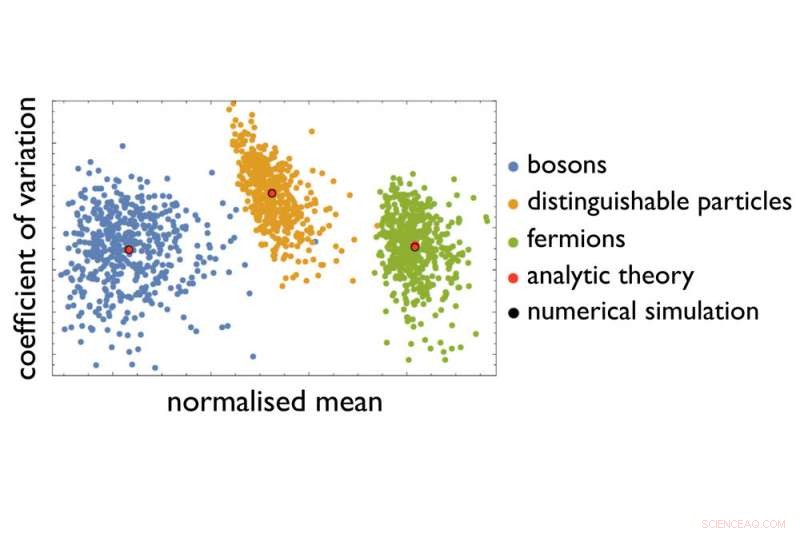
Deres eksempel på et vanskeligt certificeringsproblem er at sortere et defineret antal fotoner, efter at de har gennemgået et defineret arrangement af flere optiske elementer. Arrangementet giver hver foton et antal transmissionsveje - afhængigt af om fotonet reflekteres eller transmitteres af et optisk element. Opgaven er at forudsige sandsynligheden for, at fotoner forlader arrangementet på definerede punkter, for en given positionering af fotoner ved indgangen til arrangementet. Med stigende størrelse på det optiske arrangement og stigende antal fotoner sendt på vej, antallet af mulige veje og fordelinger af fotoner i slutningen stiger stejlt som følge af det usikkerhedsprincip, der ligger til grund for kvantemekanikken - så der ikke kan forudsiges den nøjagtige sandsynlighed ved hjælp af de computere, vi har til rådighed i dag. Fysiske principper siger, at forskellige typer partikler - såsom fotoner eller elektroner - bør give forskellige sandsynlighedsfordelinger. Men hvordan kan forskere se disse fordelinger og forskellige optiske arrangementer fra hinanden, når der ikke er nogen måde at foretage nøjagtige beregninger?
En fremgangsmåde udviklet i den nuværende undersøgelse gør det nu muligt for første gang at identificere karakteristiske statistiske signaturer på tværs af umålelige sandsynlighedsfordelinger. I stedet for et fuldstændigt "fingeraftryk, "de var i stand til at destillere oplysningerne fra datasæt, som blev reduceret for at gøre dem brugbare. Ved hjælp af disse oplysninger, de var i stand til at skelne mellem forskellige partikeltyper og særpræg ved optiske arrangementer. Teamet viste også, at denne destillationsproces kan forbedres, trækker på etablerede teknikker til maskinlæring, hvorved fysikken giver de vigtigste oplysninger om, hvilket datasæt der skal bruges til at søge de relevante mønstre. Og fordi denne tilgang bliver mere præcis for et større antal partikler, forskerne håber, at deres resultater tager os et vigtigt skridt tættere på at løse certificeringsproblemet.
 Varme artikler
Varme artikler
-
 Et kvantespring til ultrapræcis måling og informationskodning?Kredit:CC0 Public Domain Et EU -projekt, der arbejder med ultrahurtig optik, fremmer kontrollen over de rumlig-tidsmæssige kvantetilstande af lys, fremme kvanteinformationsvidenskab. Quantum Info
Et kvantespring til ultrapræcis måling og informationskodning?Kredit:CC0 Public Domain Et EU -projekt, der arbejder med ultrahurtig optik, fremmer kontrollen over de rumlig-tidsmæssige kvantetilstande af lys, fremme kvanteinformationsvidenskab. Quantum Info -
 Verdens første detektor designet af forskere i mørkt stof registrerer sjældne hændelserEn akustisk bølgeresonator af kvartsglas. En banebrydende detektor, der har til formål at bruge kvarts til at fange højfrekvente gravitationsbølger, er blevet bygget af forskere ved ARC Center of
Verdens første detektor designet af forskere i mørkt stof registrerer sjældne hændelserEn akustisk bølgeresonator af kvartsglas. En banebrydende detektor, der har til formål at bruge kvarts til at fange højfrekvente gravitationsbølger, er blevet bygget af forskere ved ARC Center of -
 Foreslået metode til at få et atom til at udsende det samme lys som et andet atomKontrolfelterne Ea (t), Eb (t), Ec (t), Ed (t) og Ee (t) fremkalder det samme ikke -lineære optiske respons Y (t) på:lukkede kvantesystemer (a) og (b), c) et åbent kvantesystem d) et lukket klassisk s
Foreslået metode til at få et atom til at udsende det samme lys som et andet atomKontrolfelterne Ea (t), Eb (t), Ec (t), Ed (t) og Ee (t) fremkalder det samme ikke -lineære optiske respons Y (t) på:lukkede kvantesystemer (a) og (b), c) et åbent kvantesystem d) et lukket klassisk s -
 En ny måde at plotte turbulente luftbevægelser på illustrerer skønheden i væskedynamikDisse parrede billeder viser en computersimulering af turbulens inden for 100 kubikmeter luft. På billedet til venstre, det sorte mellemrum repræsenterer luftbevægelse, og farven er det stille mellemr
En ny måde at plotte turbulente luftbevægelser på illustrerer skønheden i væskedynamikDisse parrede billeder viser en computersimulering af turbulens inden for 100 kubikmeter luft. På billedet til venstre, det sorte mellemrum repræsenterer luftbevægelse, og farven er det stille mellemr
- Opdagelsen af den første aktive nedsivning i Antarktis giver ny forståelse af metans cyklus
- Blå svampefarvestof bruges til at udvikle nyt fluorescerende værktøj til cellebiologer
- Tiden brugt med New Musical Express falder med 72 %, efter at magasinet kun skifter online
- Klimaændringer er skyld i orkanen Marias ekstreme nedbørsmængder
- Ny videnskabelig tilgang vurderer landindvinding efter olie- og gasboring
- Model identificerer en høj grad af udsving i gluoner som afgørende for at forklare protonstrukture…