


Ny model tilbyder fysik-inspireret rangeringsevaluering
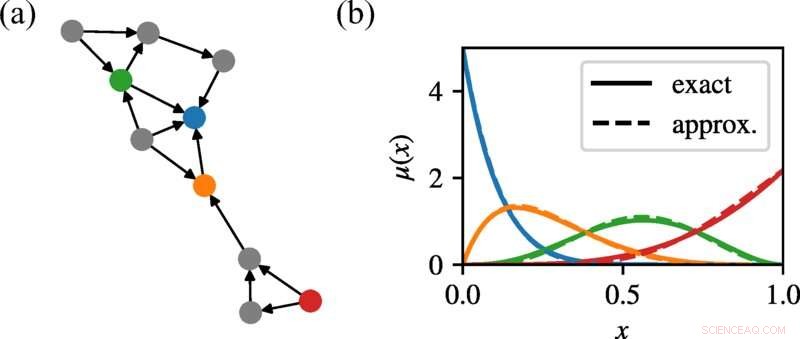
I (a) viser vi et tilfældigt vokset netværk med Poisson-out-grade. I (b) viser vi de bageste marginaler for fire repræsentative noder, farvet til at matche (a), og sammenligner dem, der er opnået med vores metode, med de nøjagtige resultater af udtømmende opregning. På trods af tilstedeværelsen af korte cyklusser, tilnærmer vores tilgang til trosudbredelse marginalerne ret tæt, og matcher ikke kun midlerne, men formerne af disse fordelinger. Kredit:Physical Review E (2022). DOI:10.1103/PhysRevE.105.L052303
Verden er fyldt med placeringer og rækkefølger. De dukker op i tennis - som i French Open, der ender med en endelig rangering af mesterspillere. De dukker op i pandemier - som når offentlige sundhedsembedsmænd kan registrere nye infektioner og bruge kontaktsporing til at skitsere netværk af COVID-19-spredning. Konkurrence-, konflikt- og smittesystemer kan alle give anledning til hierarkier.
Imidlertid observeres disse hierarkier efter kendsgerningen. Det gør det svært at kende systemets sande placeringer:Hvem var egentlig den bedste spiller? Hvem inficerede hvem? "Du kan ikke gå tilbage i tiden og lære præcis, hvordan denne ting skete," siger SFI Postdoc-stipendiat George Cantwell. Man kunne bygge en model af netværket og sammenligne alle mulige resultater, men sådan en brute-force tilgang bliver hurtigt uholdbar. Hvis du prøvede at rangere en gruppe med kun 60 deltagere, for eksempel, når antallet af mulige permutationer op på antallet af partikler i det kendte univers.
For et nyligt papir offentliggjort i Physical Review E , samarbejdede Cantwell med SFI-professor Cris Moore, en datalog og matematiker, for at beskrive en ny måde at evaluere ranglister på. Deres mål var ikke at finde ét sandt hierarki, men at beregne spredningen af alle mulige hierarkier, med hver enkelt vægtet af dets sandsynlighed.
"Vi var villige til ikke at være helt rigtige, men vi ønskede at få gode svar med en vis fornemmelse af, hvor gode de er," siger Cantwell. Den nye algoritme er inspireret af fysik:Ranger er modelleret som interagerende enheder, der kan bevæge sig op eller ned. Gennem den linse opfører systemet sig så som et fysisk system, der kan analyseres ved hjælp af metoder fra spinglasteori.
Kort efter starten af COVID-19-pandemien begyndte Cantwell og Moore at tænke på modeller for, hvordan sygdom spredes gennem et netværk. De anerkendte hurtigt situationen som et ordensproblem, der opstår over tid, ikke ulig spredningen af et meme på sociale medier eller fremkomsten af mesterskabsranglister i professionel sport. "Hvordan bestiller du ting, når du har ufuldstændige oplysninger?" spørger Cantwell.
De startede med at forestille sig en funktion, der kunne score en ranking på nøjagtighed. For eksempel:En god placering ville være en, der stemmer overens med resultaterne af matchups 98 % af tiden. En placering, der kun stemmer overens med resultaterne 10 % af tiden, ville være elendig - værre end en møntvending uden forudgående viden.
Et problem med placeringer er, at de typisk er diskrete, hvilket betyder, at de følger de hele tal:1, 2, 3 og så videre. Denne rækkefølge antyder, at "afstanden" mellem de første- og andenrangerede medlemmer er den samme som mellem den anden og tredje. Men det er ikke tilfældet, siger Cantwell. De bedste spillere i et spil, på verdensplan, kommer til at være tæt sammen med hensyn til færdigheder, så forskellen mellem toprangerede spillere kan være tættere på, end det ser ud til.
"Man ser ret ofte, at lavere rangerede spillere kan slå højere rangerede spillere, og den eneste måde, modellen kan give mening og passe til dataene, er ved at klemme alle rækkerne sammen," siger Cantwell.
Cantwell og Moore beskrev et system, der evaluerer rangeringer baseret på et kontinuerligt nummereringssystem. En rangordning kan tildele et hvilket som helst reelt tal – heltal, brøk, uendeligt gentagende decimal – til en spiller i netværket. "Kontinuerlige tal er nemmere at arbejde med," siger Cantwell, og disse kontinuerlige tal kan stadig oversættes tilbage til diskrete placeringer.
Derudover kan denne nye tilgang bruges til at forudsige noget om fremtiden, såsom resultatet af en tennisturnering, og også udlede noget om fortiden, såsom hvordan en sygdom har spredt sig. "Disse ranglister kunne fortælle os rækkefølgen af sportshold fra bedst til værst. Men de kunne også fortælle os, i hvilken rækkefølge folk i et samfund blev inficeret med en sygdom," siger Moore. "Selv før hans postdoc arbejdede George på dette problem som en måde at forbedre kontaktsporing i en epidemi. Ligesom vi kan forudsige, hvilket hold der vinder en kamp, kan vi udlede, hvilken af to personer, der inficerede den anden, da de kom i kontakt med hinanden."
I det fremtidige arbejde siger forskerne, at de planlægger at undersøge nogle af de dybere spørgsmål, der er dukket op. Mere end én rangering kan f.eks. være enig i data, men radikalt uenig med andre rangeringer. Eller en rangering, der virker forkert, kan have høj usikkerhed, men ikke være unøjagtig. Cantwell siger, at han også ønsker at sammenligne modellens forudsigelser med resultater fra konkurrencer i den virkelige verden. I sidste ende, siger han, kan modellen bruges til at forbedre forudsigelser i en bred vifte af systemer, der fører til placeringer, fra infektionssygdomsmodeller til sportsvæddemål.
Cantwell siger, at han vil holde på sine penge - indtil videre. "Jeg er ikke helt klar til at begynde at satse på det," siger han. + Udforsk yderligere
Kan 'belief propagation'-algoritmen nøjagtigt beskrive komplekse netværkssystemer?
 Varme artikler
Varme artikler
-
 Superopløsning på alle skalaer med aktiv termisk detektionScanningsbelysning, termisk respons og superopløsningsfaktor. (a) To objekter belyses af en scanningsfokuseret energikilde med en størrelse større end objekterne eller afstanden mellem dem. (b) Den te
Superopløsning på alle skalaer med aktiv termisk detektionScanningsbelysning, termisk respons og superopløsningsfaktor. (a) To objekter belyses af en scanningsfokuseret energikilde med en størrelse større end objekterne eller afstanden mellem dem. (b) Den te -
 Visualisering af områder med elektromagnetiske bølge-plasma-interaktioner, der omgiver JordenSkematisk illustration af koordineret observation ved hjælp af den videnskabelige satellit Arase og PWING, et jordbaseret observationsnetværk. Gennem detaljeret observation af den videnskabelige satel
Visualisering af områder med elektromagnetiske bølge-plasma-interaktioner, der omgiver JordenSkematisk illustration af koordineret observation ved hjælp af den videnskabelige satellit Arase og PWING, et jordbaseret observationsnetværk. Gennem detaljeret observation af den videnskabelige satel -
 Nyfundet superledermateriale kunne være silicium fra kvantecomputereVi har allerede fundet masser af superledere, men denne finurlige illustration viser, hvorfor en superleders nyfundne egenskaber kan gøre den særlig nyttig. De mest kendte superledere er spin-singlett
Nyfundet superledermateriale kunne være silicium fra kvantecomputereVi har allerede fundet masser af superledere, men denne finurlige illustration viser, hvorfor en superleders nyfundne egenskaber kan gøre den særlig nyttig. De mest kendte superledere er spin-singlett -
 Twisted 2-D materiale giver ny indsigt i stærkt korreleret 1-D fysikEndimensionelle korrelerede tilstande dukker op i snoet dobbeltlags germanium selenid. Figuren viser ladningstæthedsfordelingen af sådanne tilstande opnået ved beregninger af tæthedsfunktionsteori.
Twisted 2-D materiale giver ny indsigt i stærkt korreleret 1-D fysikEndimensionelle korrelerede tilstande dukker op i snoet dobbeltlags germanium selenid. Figuren viser ladningstæthedsfordelingen af sådanne tilstande opnået ved beregninger af tæthedsfunktionsteori.
- Forskere efterlyser mere forskning i, hvordan menneskelige aktiviteter påvirker havbunden
- Deep-sea Roombas vil kæmme havbunden til DDT affaldsfade nær Catalina Island
- Undersøgelse bruger neutroner til at skinne lys på lukning af kræftceller
- Brug af Spotify-data til at forudsige, hvilke sange der bliver hits
- Missouri standser solcelleskattefradrag, efterhånden som føderale incitamenter udvides
- Hvordan videnskabsmænd brugte NASA-data til at forudsige coronaen af den totale solformørkelse d…