


Brug af Spotify-data til at forudsige, hvilke sange der bliver hits
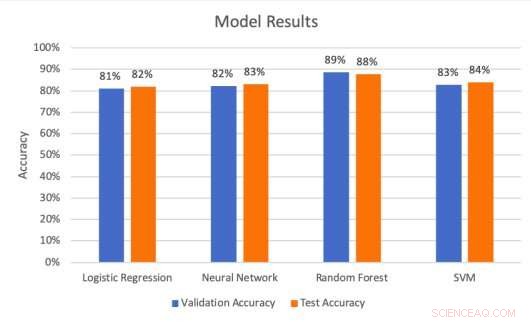
Modelresultater på validerings- og testsæt. Kredit:Middlebrook &Sheik.
To studerende og forskere ved University of San Francisco (USF) har for nylig forsøgt at forudsige billboard-hits ved hjælp af maskinlæringsmodeller. I deres undersøgelse, forudgivet på arXiv, de trænede fire modeller på sang-relaterede data udtrukket ved hjælp af Spotify Web API, og evaluerede derefter deres præstation i at forudsige, hvilke sange der ville blive hits.
"Jeg er en stor musikfan, og jeg lytter til musik hele dagen; under min pendling, på arbejde, og med venner, "Kai Middlebrook, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Sidste forår, Jeg begyndte et forskningsprojekt om automatisk musikgenreklassificering med professor David Guy Brizan ved University of San Francisco (USF). Projektet krævede en stor mængde musikdata, og populære musikstreamingtjenester har præcis den slags data, jeg havde brug for."
Mens han arbejdede på et projekt relateret til automatisk musikgenreklassificering, Middlebrook erfarede, at Spotify tillader udviklere at få adgang til dets musikdata. Dette tilskyndede ham til at begynde at eksperimentere med Spotify Web API for at indsamle data til sine studier. Da han havde afsluttet forskningen i forbindelse med genreklassificering, imidlertid, han satte API'en til side i nogen tid.
"Få måneder senere, min ven Kian, som også er dataforsker og elsker musik, og jeg havde en diskussion om musik, " sagde Middlebrook. "På et tidspunkt under samtalen, den almindeligt anerkendte idé om, at "alle hitsange lyder ens" blev fremført. Vi troede ikke nødvendigvis på, at det var sandt, men ideen fik os til at spekulere:Hvad hvis hitsange deler nogle ligheder? Det virkede muligt, så Kian og jeg besluttede at undersøge nærmere."
Middlebrook og Sheik, som tidligere havde samarbejdet om genreklassificeringsprojektet, besluttede at foretage en yderligere undersøgelse ved hjælp af data udtrukket fra Spotify. Dette nye projekt ville også være den sidste opgave for deres data mining-kursus på USF.
"Vi samarbejdede om flere andre projekter til forskellige kurser, så det gav mening at holde sammen, "Kian Sheik, en anden forsker involveret i undersøgelsen, fortalte TechXplore. "Lil Nas X's hit "Old Town Road" var lige kommet ud af ingenting, og var på toppen af Billboard Hot 100. Kai og jeg spekulerede på, om en computer kunne have forudsagt hans stigning, eller om det bare var en hitsingle, der kom ud af venstre felt. Det, der startede som et simpelt afsluttende projekt, endte med, at vi udtømte alle state-of-the-art overvågede læringsmodeller på et stort datasæt for at besvare et simpelt spørgsmål:Vil denne sang blive et hit?"
I deres undersøgelse, Middlebrook og Sheik brugte Spotify Web API til at indsamle data for 1,8 millioner sange, som inkluderede funktioner såsom en sangs tempo, nøgle, valens, osv. De indsamlede så også cirka 30 års data fra Billboard Hot 100-diagrammet.
"Vores mål var at se, om hitsange delte lignende funktioner, og i så fald om disse funktioner kunne bruges til at forudsige, hvilke sange der ville blive hits i fremtiden, " sagde Middlebrook.
Forskerne trænede og evaluerede fire forskellige modeller:en logistisk regression, et neuralt netværk, en støttevektormaskine (SVM) og en tilfældig skov (RF) arkitektur. Under træning, disse modeller analyserede en række sangfunktioner, inklusive tempo, nøgle, valens, energi, akustik, dansbarhed og lydstyrke.
"Når man får en sang, vores modeller ville mærke det med enten et et eller et nul, Middlebrook forklarede. "En sang mærket med et betyder, at modellen forudsiger, at sangen var et hit. En sang mærket med et nul betyder, at modellen forudsiger, at sangen ikke var et hit."
Den logistiske regressionsmodel, som forskerne trænede, antager, at sangdata lineært kan adskilles i to kategorier:hits og ikke-hits. Modellen tildeler en vægt til hver sangfunktion, og bruger derefter disse vægte til at forudsige, om en sang falder i kategorien "hit" eller "ikke-hit".
Logistiske regressionsmodeller har to vigtige fordele:fortolkning og hastighed. Med andre ord, denne type arkitektur gør det lettere at fortolke forholdet mellem forklarende variabler (dvs. sangens funktioner) og responsvariablen (dvs. hit eller ikke-hit), og det kan også trænes relativt hurtigt.
Den anden model, som forskerne trænede, var en RF-arkitektur. Denne model fungerer ved at kombinere en stor mængde byggeklodser kendt som beslutningstræer.
"I bund og grund, et beslutningstræ kan opfattes som en model, der bruger en række ja/nej-spørgsmål til at adskille dataene, " sagde Middlebrook. "De kan fortolkes, men tilbøjelig til at overtilpasse dataene. Overfitting betyder, at en model husker træningsdataene ved at passe dem for tæt. Problemet med overfitting er, at modellen måske ikke lærer det faktiske forhold mellem sangfunktioner og sangens popularitet, fordi dataene ofte indeholder irrelevant støj."
For at undgå problemet med overfitting, den tilfældige skovmodel brugt af Middlebrook og Sheik kombinerer hundredtusindvis af beslutningstræer, som hver er trænet på et andet undersæt af træningsdataene og et andet undersæt af sangfunktionerne. Modellen laver derefter en forudsigelse (dvs. bestemmer, om en sang er et hit eller ikke-hit) ved at beregne et gennemsnit af forudsigelsen for hvert træ og kombinere disse resultater.
"I vores brugssag, fordelen ved den tilfældige skovmodel er dens fleksibilitet, " sagde Middlebrook. "Den er mere fleksibel end en lineær model (f.eks. logistisk regression)."
Den tredje og fjerde model trænet af forskerne, nemlig SVM og neurale netværksarkitekturer, er begge ikke-lineære og er derfor sværere at fortolke. SVM-modellen fungerer ved at forsøge at finde det "hyperplan", der bedst adskiller dataene i de to kategorier (dvs. hits eller ikke-hits). Den neurale netværksarkitektur, på den anden side, bruger ét skjult lag med ti filtre til at lære af sangdataene.
Blandt de fire modeller brugt af Middlebrook og Sheik, den logistiske regressionsmodel er den nemmeste at fortolke, mens den neurale netværksbaserede er den sværeste. De to andre modeller falder et sted i midten.
"Generelt, disse modeller vil forudsige baseret på begrænsninger, som de udvikler gennem træning, "Sheik sagde. "Hver model er blevet trænet på det samme sæt af soniske klassifikatorer. Outputtet af modellerne er testet mod historisk sandhed fra Billboard API, om det givne nummer nogensinde har optrådt på Billboard Hot 100-listen. Vi brugte en flåde af computere hos USF til at lave tal, og efter et par ugers ren beregning, vi havde beregnet de optimale parametre for hver model."
Forskerne gennemførte en række evalueringer for at teste, hvor godt de fire modeller kunne forudsige billboard-hits. De fandt ud af, at SVM-arkitektur opnåede den højeste præcisionsrate (99,53 procent), mens den tilfældige skovmodel opnåede den bedste nøjagtighedsrate (88 procent) og tilbagekaldelsesprocent (85,51 procent).
"Recall udtrykker evnen til at finde alle relevante forekomster i et datasæt, mens præcision udtrykker, hvor stor en andel af data, som vores model siger, var relevant, faktisk var relevant, Middlebrook forklarede. "Med andre ord, husk, fortæl os, hvor sandsynligt vores model er til nøjagtigt at forudsige et faktisk hit som et hit. Præcision fortæller os andelen af forudsagte hits, der faktisk var hits."
Ifølge forskerne, hvis pladeselskaber skulle bruge nogen af disse modeller til at forudsige, hvilke sange der vil være mere succesfulde, de ville sandsynligvis vælge en model med en høj præcisionsrate end en med en høj nøjagtighedsrate. Dette skyldes, at en model, der opnår høj præcision, påtager sig mindre risiko, da det er mindre sandsynligt at forudsige, at en ikke-succesfuld sang bliver et hit.
"pladeselskaber har begrænsede ressourcer, " sagde Middlebrook. "Hvis de hælder disse ressourcer i en sang, som modellen forudser vil blive et hit, og den sang bliver aldrig en, så kan mærket miste mange penge. Så hvis et pladeselskab vil tage lidt større risiko med muligheden for at udgive flere hitplader, de kan vælge at bruge vores tilfældige skovmodel. På den anden side, hvis et pladeselskab ønsker at påtage sig mindre risiko, mens det stadig udgiver nogle hits, de skal bruge vores SVM-model."
Middlebrook og Sheik fandt ud af, at forudsigelse af et billboard-hit baseret på funktioner i en sangs lyd er, faktisk, muligt. I deres fremtidige forskning, forskerne planlægger at undersøge andre faktorer, der kan bidrage til sangsucces, såsom tilstedeværelse på sociale medier, kunstneroplevelse, og etiketpåvirkning.
"Vi kan forestille os en verden, hvor pladeselskaber, der konstant søger nyt talent, oversvømmes med mix-tapes og demoer fra de "næste hotte kunstnere, "" sagde Sheik. "Folk har kun så meget tid til at lytte til musik med menneskelige ører, så "kunstige ører, "såsom vores algoritmer, kan gøre det muligt for pladeselskaber at træne en model til den type lyd, de søger, og i høj grad reducere antallet af sange, de selv skal overveje."
Klassificeringsapparater som dem, der er udviklet af Middlebrook og Sheik, kunne i sidste ende hjælpe pladeselskaber med at beslutte, hvilke sange de skal investere i. Selvom ideen om at bruge maskinlæring til at skimme gennem demoer kan være interessant for musikindustrien, Sheik advarer om, at det også kan få uønskede konsekvenser.
"Selvom dette kan være en hensigtsmæssig fremtid, udsigten til en ordsproget "huggeklods", som kunstnere skal måle sig med, har potentialet til at blive et ekkokammer, eller en situation, hvor ny musik skal lyde som gammel musik for at blive udgivet i radioen, " sagde Sheik. "Indholdsskabere på platforme som YouTube, som også bruger algoritmer til at bestemme, hvilke videoer der skal vises til masserne, har fordømt faldgruberne ved at tvinge kunstnere til at arbejde for en maskine."
Ifølge Sheik, hvis virksomheder og producenter begynder at bruge algoritmer til at træffe kunstneriske beslutninger, disse modeller bør designes på en måde, der ikke hæmmer kunstens fremskridt. Arkitekturerne udviklet af de to forskere ved USF, imidlertid, er endnu ikke i stand til at opnå dette.
"Nyhedsbias og andre uortodokse træk vil skulle introduceres og opfindes, for at musikken som helhed ikke nærmer sig en kulturel singularitet i hænderne på egnethed, " konkluderede Sheik.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Boeing-papirer viser, at ansatte gled 737 Max-problemer forbi FAANyligt udgivne Boeing-dokumenter viser beskeder mellem ansatte, der håner amerikanske luftfartsmyndigheder Lovgivere på Capitol Hill slog ud mod Boeing i fredags efter udgivelsen af en række e-m
Boeing-papirer viser, at ansatte gled 737 Max-problemer forbi FAANyligt udgivne Boeing-dokumenter viser beskeder mellem ansatte, der håner amerikanske luftfartsmyndigheder Lovgivere på Capitol Hill slog ud mod Boeing i fredags efter udgivelsen af en række e-m -
 Hvad er trending inden for falske nyheder? Værktøjer viser, hvilke historier der bliver virale, og…En Hoaxy-søgning sporer spredningen af en nyhedshistorie, der hævder Syriens civile forsvar, en frivillig eftersøgnings- og redningsorganisation også kendt som White Helmets iscenesætter masseulykk
Hvad er trending inden for falske nyheder? Værktøjer viser, hvilke historier der bliver virale, og…En Hoaxy-søgning sporer spredningen af en nyhedshistorie, der hævder Syriens civile forsvar, en frivillig eftersøgnings- og redningsorganisation også kendt som White Helmets iscenesætter masseulykk -
 Canada til at vurdere Boeing 737 MAX luftdygtighed uden USAAir Canada annoncerede, at det vil jorden sine 24 737 MAX -fly indtil mindst 1. juli, 2019, forklarer, at den ikke ved, hvornår de vil blive certificeret til at flyve igen Canada sagde tirsdag, at
Canada til at vurdere Boeing 737 MAX luftdygtighed uden USAAir Canada annoncerede, at det vil jorden sine 24 737 MAX -fly indtil mindst 1. juli, 2019, forklarer, at den ikke ved, hvornår de vil blive certificeret til at flyve igen Canada sagde tirsdag, at -
 Forskere foreslår klimaanlæg som et middel til klimaforandringKredit:CC0 Public Domain Forskere har en idé, der kan få dig til at føle dig mere som en grøn borger end som en hedonist, hvis du køber et klimaanlæg til dit opholdsrum. Der er en måde, som kunne
Forskere foreslår klimaanlæg som et middel til klimaforandringKredit:CC0 Public Domain Forskere har en idé, der kan få dig til at føle dig mere som en grøn borger end som en hedonist, hvis du køber et klimaanlæg til dit opholdsrum. Der er en måde, som kunne
- Hurtigere, stærkere, lettere:Ny teknik fremmer kulfiberkompositter
- Data som materiale til produktdesign
- Apple siger, at det planlægger at gøre Seattle til et nøglecenter for ingeniørarbejde med 2, 000…
- Featherweight oxygen discovery åbner vindue om nuklear symmetri
- Sådan beregnes procentvis ionisering
- Den 120 år gamle kolde sag for Grignard-reaktionen er endelig løst