


Maskinlæringsalgoritme hjælper med at søge efter nye lægemidler

Kredit:CC0 Public Domain
Forskere har designet en maskinlæringsalgoritme til lægemiddelopdagelse, som har vist sig at være dobbelt så effektiv som industristandarden, som kunne fremskynde processen med at udvikle nye behandlinger for sygdom.
Forskerne, ledet af University of Cambridge, brugt deres algoritme til at identificere fire nye molekyler, der aktiverer et protein, som menes at være relevant for symptomer på Alzheimers sygdom og skizofreni. Resultaterne er rapporteret i journalen PNAS .
Et nøgleproblem i lægemiddelopdagelsen er at forudsige, om et molekyle vil aktivere en bestemt fysiologisk proces. Det er muligt at bygge en statistisk model ved at søge efter kemiske mønstre, der deles mellem molekyler, der vides at aktivere den proces, men dataene til at bygge disse modeller er begrænsede, fordi eksperimenter er dyre, og det er uklart, hvilke kemiske mønstre der er statistisk signifikante.
"Maskinlæring har gjort betydelige fremskridt inden for områder som computersyn, hvor data er rigeligt, " sagde Dr. Alpha Lee fra Cambridges Cavendish Laboratory, og undersøgelsens hovedforfatter. "Den næste grænse er videnskabelige anvendelser såsom lægemiddelopdagelse, hvor mængden af data er relativt begrænset, men vi har fysisk indsigt om problemet, og spørgsmålet bliver, hvordan man kombinerer data med grundlæggende kemi og fysik."
Algoritmen udviklet af Lee og hans kolleger, i samarbejde med biofarmaceutiske firma Pfizer, bruger matematik til at adskille farmakologisk relevante kemiske mønstre fra irrelevante.
Vigtigt, Algoritmen ser på både molekyler, der vides at være aktive, og molekyler, der vides at være inaktive, og lærer at genkende, hvilke dele af molekylerne der er vigtige for lægemiddelvirkningen, og hvilke dele der ikke er. Et matematisk princip kendt som tilfældig matrixteori giver forudsigelser om de statistiske egenskaber af et tilfældigt og støjende datasæt, som derefter sammenlignes med statistikken over kemiske træk ved aktive/inaktive molekyler for at destillere, hvilke kemiske mønstre der virkelig er vigtige for binding i modsætning til blot at opstå tilfældigt.
Denne metode gør det muligt for forskerne at udfiske vigtige kemiske mønstre, ikke kun fra aktive molekyler, men også fra molekyler, der er inaktive – med andre ord, mislykkede eksperimenter kan nu udnyttes med denne teknik.
Forskerne byggede en model, der startede med 222 aktive molekyler, og var i stand til beregningsmæssigt at screene yderligere seks millioner molekyler. Fra dette, forskerne købte og screenede de 100 mest relevante molekyler. Fra disse, de identificerede fire nye molekyler, der aktiverer CHRM1-receptoren, et protein, der kan være relevant for Alzheimers sygdom og skizofreni.
"Evnen til at fiske fire aktive molekyler ud fra seks millioner er som at finde en nål i en høstak, " sagde Lee. "En head-to-head sammenligning viser, at vores algoritme er dobbelt så effektiv som industristandarden."
At lave komplekse organiske molekyler er en betydelig udfordring i kemi, og potentielle lægemidler bugner i rummet af endnu ikke-fremstillelige molekyler. Cambridge-forskerne udvikler i øjeblikket algoritmer, der forudsiger måder at syntetisere komplekse organiske molekyler på, samt udvidelse af maskinlæringsmetoden til materialeopdagelse.
Forskningen blev støttet af Winton Program for the Physics of Sustainability.
Sidste artikelArbejdsproteiner gør god brug af frustration
Næste artikelAnti-træthedsbrud hydrogeler
 Varme artikler
Varme artikler
-
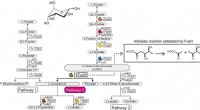 En ny L-fucose metabolisk vej fra strengt anaerobe og patogene bakterierL-Fucose metaboliske veje. Kredit:Ehime University Den genetiske kontekst i bakterielle genomer og screening for potentielle substrater kan hjælpe med at identificere de biokemiske funktioner af b
En ny L-fucose metabolisk vej fra strengt anaerobe og patogene bakterierL-Fucose metaboliske veje. Kredit:Ehime University Den genetiske kontekst i bakterielle genomer og screening for potentielle substrater kan hjælpe med at identificere de biokemiske funktioner af b -
 Forskere udvikler et pengeskab, billig teknologi til desinfektion af emballerede ægOmkostningerne ved bestråling af plastemballage (10 æg) vil ikke overstige 1,2 eurocent. Kredit:UrFU / Ilya Safarov Russiske forskere har udviklet en billig, sikker, og pålidelig overflade desinfe
Forskere udvikler et pengeskab, billig teknologi til desinfektion af emballerede ægOmkostningerne ved bestråling af plastemballage (10 æg) vil ikke overstige 1,2 eurocent. Kredit:UrFU / Ilya Safarov Russiske forskere har udviklet en billig, sikker, og pålidelig overflade desinfe -
 Identifikation af designermedicin taget af overdosispatienterLægemidler frigivet fra testpatronen (i midten) identificeres af et massespektrometer (venstre). Kredit:Greta Ren Overdosering af stoffer tager en enorm vejafgift på folkesundheden, med potente sy
Identifikation af designermedicin taget af overdosispatienterLægemidler frigivet fra testpatronen (i midten) identificeres af et massespektrometer (venstre). Kredit:Greta Ren Overdosering af stoffer tager en enorm vejafgift på folkesundheden, med potente sy -
 Classic Science at Home: Elephant ToothpasteElefanttandepasta er et klassisk reaktionseksperiment elsket af naturfaglærere overalt i verden, men du behøver ikke vente på, at dine børn oplever det i skolen. Med blot et par enkle ingredienser
Classic Science at Home: Elephant ToothpasteElefanttandepasta er et klassisk reaktionseksperiment elsket af naturfaglærere overalt i verden, men du behøver ikke vente på, at dine børn oplever det i skolen. Med blot et par enkle ingredienser
- Sådan beregnes Heat Index Formula
- Apple har en meget uteknologisk tilgang til at løse falske nyheder:menneskelige redaktører
- Coda 1.0:Wowza, en doc, borde, faner, knapper, og gå team
- Satellitter, der analyserer udviklende golfpotentiale Tropical Cyclone Two
- Brug af højopløste satellitter til at måle afrikanske landbrugsudbytter
- Barrierer for at stemme ved valg er forbundet med øgede chancer for at være uforsikret