


Den tid, der er nødvendig for at sekvensere nøglemolekyler, kan reduceres fra år til minutter
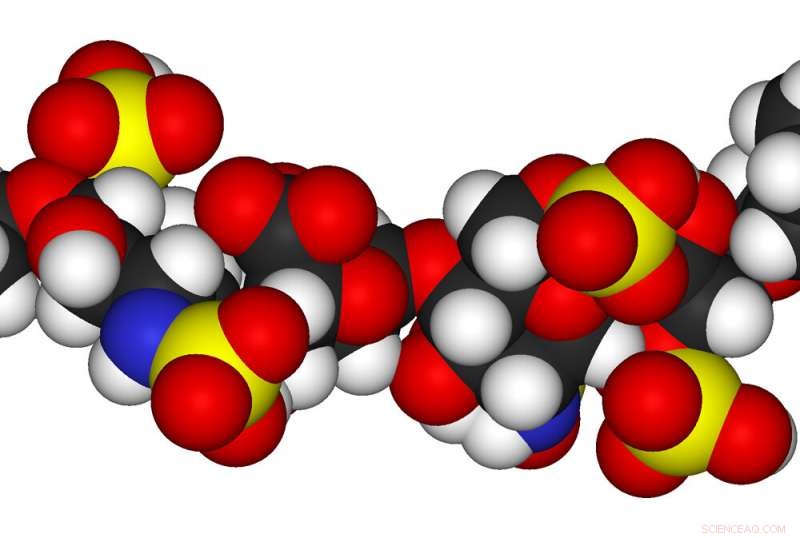
En nanopore og billedgenkendelsessoftware kan sekvensere en sulfateret glycosaminoglycan i realtid. Kredit:Rensselaer Polytekniske Institut
Ved at bruge en nanopore, forskere har demonstreret potentialet til at reducere den tid, der kræves for at sekventere en glycosaminoglycan - en klasse af langkædede sukkermolekyler, der er lige så vigtige for vores biologi som DNA - fra år til minutter.
Som offentliggjort i denne uge i Proceedings of the National Academy of Sciences , et hold fra Rensselaer Polytechnic Institute viste, at software til maskinlæring og billedgenkendelse kunne bruges til hurtigt og præcist at identificere sukkerkæder – specifikt, fire syntetiske heparansulfater - baseret på de elektriske signaler, der genereres, da de passerede gennem et lille hul i en krystalwafer.
"Glycosaminoglycaner er et komplekst repertoire af sekvenser, da Shakespeares værk eller et digt af Yates er en kompleks samling af breve. Det kræver en ekspert at skrive dem og en ekspert til at læse dem, " sagde Robert Linhardt, ledende forsker og professor i kemi og kemisk biologi ved Rensselaer Polytekniske Institut. "Vi har trænet en maskine til hurtigt at læse, hvad der svarer til ord med fire bogstaver som 'ababab' eller 'bcbcbc'. Disse er simple sekvenser, der ikke har nogen betydning, men de viser os, at maskinen kan læres at læse. Hvis vi udvider og udvikler denne teknologi, det har potentialet til at sekvensere glykanerne eller endda proteiner i realtid, eliminerer mange års indsats."
Kommercielle nanopore-sekventeringsenheder bruges til at sekventere DNA, som er sammensat af fire nukleinsyreenheder, kendt under bogstaverne A, C, G, og T, spændt sammen i en endeløs række af konfigurationer. Enheden er afhængig af en ionstrøm, der løber gennem et hul, der kun er få milliardtedele meter bredt i en membran. DNA-strenge er placeret på den ene side af hullet, og trækkes igennem med strømmens flow. Hver nukleinsyre blokerer hullet noget, når det passerer igennem, afbryde strømmen og give et bestemt signal forbundet med den nukleinsyre. Enheder, bruges i øjeblikket til feltarbejde, er kun en af flere relativt hurtige og automatiserede teknikker til sekventering af DNA.
Glycosaminoglycaner, eller GAG'er, er en strukturelt kompleks klasse af glykaner - de essentielle sukkerarter, der findes i levende organismer - som findes på celleoverflader og ekstracellulær matrix hos alle dyr og udfører mange funktioner i cellevækst og -signalering, antikoagulering og sårreparation, og opretholdelse af celleadhæsion. GAG'er, i øjeblikket udvundet fra slagtede dyr, bruges som lægemidler og nutraceuticals.
Ligesom DNA, GAG'er kan underopdeles i deres konstituerende disaccharidsukkerenheder. Men hvor DNA kun er lavet af fire bogstaver i en lineær streng, disse glykaner har snesevis af grundlæggende enheder, nogle med tilknyttede sulfatgrupper, syregrupper, og amidgrupper. For eksempel, selv et relativt lille naturligt forekommende heparansulfatmolekyle på seks sukkerenheder kunne have 32, 768 mulige sekvenser. På grund af udfordringen, glykan-sekventering forbliver besværlig, afhængig af omhyggeligt laboratoriearbejde og sofistikeret analyse, involverer teknikker med navne som væskekromatografi-tandem massespektrometri og kernemagnetisk resonansspektroskopi.
Som en del af hans arbejde, Linhardt, en glykanekspert, der udviklede en syntetisk variant af det almindelige blodfortyndende heparin, sekvenser GAG'er for at forstå naturligt forekommende former og udvikle syntetiske varianter.
"Ved brug af standard analytiske metoder, det tog os to år at sekvensere den første simple GAG, sagde Linhardt, medlem af Rensselaer Center for Bioteknologi og Tværfaglige Studier. "Vi har en anden, som vi har arbejdet ud af det meste af sekvensen, og det har taget os fem-plus år – og det vil sandsynligvis tage os yderligere fem år at afslutte det, "
Begrundelse for, at nanopore-sekventering kunne bruges til at identificere disaccharidenhederne i en GAG, forskerholdet byggede sin egen nanopore-enhed og syntetiserede fire heparansulfat GAG-kæder ved hjælp af den kemoenzymatiske proces udviklet af Linhardt Lab. Vigtigt, disse fire heparansulfater var meget enkle – lavet med kombinationer af kun fire forskellige typer sukkerenheder, samlet i en kæde på omkring 40 enheder lang, og med en nøje styret sammensætning og rækkefølge.
Holdet førte hver heparansulfat gennem nanoporen og producerede en graf, der viser spændingen over tid output af enheden. Hver af de fire varianter blev kørt gennem enheden mere end 2, 000 gange, øger den statistiske sandsynlighed for en nøjagtig læsning givet det rudimentære design af den eksperimentelle nanopore.
"Enheden sekventerede det enkleste heparansulfat i realtid og producerede et mønster, som vores øjne nemt kunne genkende med det samme for hver af de fire prøver, " sagde Linhardt. "Du kan straks se, at de er forskellige."
For at sikre en objektiv analyse, holdet leverede resultaterne ind i gratis software til maskinlæring og billedgenkendelse ved hjælp af Googles dybe neurale netværk, træning af softwaren til at skelne mellem de fire forskellige mønstre og identificere hver variant af heparansulfat. Den mest succesfulde maskinlæringsmodel producerede en analyse, der var næsten 97 % nøjagtig.
"Informationsindholdet i en GAG-sekvens kan langt overgå indholdet af en tilsvarende mængde DNA eller RNA, hvilket betyder, at evnen til hurtigt at læse GAG-sekvenser åbner et nyt vindue til forståelse af livets komplekse biokemi," sagde Curt Breneman, dekan for Rensselaer School of Science. "Denne proof of concept-undersøgelse forbinder innovative nano-detektionsmetoder med avancerede maskinlæringsværktøjer, og viser magten ved tværfaglig tænkning til at udvide grænserne for viden."
At reducere hastigheden, hvormed GAG'erne passerer gennem nanoporen, kan øge nøjagtigheden, og enheden kan trænes på yderligere sukkerenheder, og mere komplekse sekvenser, som alle er fremtidige forskningsmål. Linhardt sagde, at maskinen skulle lære et sted fra 10 til 20 sukkerenheder for fuldt ud at sekvensere en GAG.
"Dette er et proof of concept; vi har fået det til at læse ord på to bogstaver, " sagde Linhardt. "Når vi lærer det hele alfabetet, den vil være i stand til at læse hver anden sekvens. Den vil være i stand til at læse alle ordene."
 Varme artikler
Varme artikler
-
 Bæredygtige 3D-printede supermagneterPå Graz teknologiske universitet, miniaturiserede supermagneter blev produceret for første gang ved hjælp af laserbaseret 3D-print. Kredit:IMAT – TU Graz Fra vindmøller og elektriske motorer til s
Bæredygtige 3D-printede supermagneterPå Graz teknologiske universitet, miniaturiserede supermagneter blev produceret for første gang ved hjælp af laserbaseret 3D-print. Kredit:IMAT – TU Graz Fra vindmøller og elektriske motorer til s -
 Forskere klokke DNAs restitutionstid efter kemoterapiDNA, som har en dobbelt helix struktur, kan have mange genetiske mutationer og variationer. Kredit:NIH I den tid det tager for en Amazon Prime-levering at ankomme, celler beskadiget af kemoterapi
Forskere klokke DNAs restitutionstid efter kemoterapiDNA, som har en dobbelt helix struktur, kan have mange genetiske mutationer og variationer. Kredit:NIH I den tid det tager for en Amazon Prime-levering at ankomme, celler beskadiget af kemoterapi -
 Træfilter fjerner giftigt farvestof fra vandetKredit:ACS Ingeniører ved University of Maryland har udviklet en ny anvendelse af træ:at filtrere vand. Liangbing Hu fra Energy Research Center og hans kolleger tilføjede nanopartikler til træ, br
Træfilter fjerner giftigt farvestof fra vandetKredit:ACS Ingeniører ved University of Maryland har udviklet en ny anvendelse af træ:at filtrere vand. Liangbing Hu fra Energy Research Center og hans kolleger tilføjede nanopartikler til træ, br -
 Kunne ungt blod holde hemmeligheder længere, sundere liv?Kredit:offentligt domæne I det der lyder som en scene fra en science fiction -film, forskere i 2005 syede gamle og unge mus sammen, så de delte et kredsløbssystem. Ungdommeligt blod foryngede tils
Kunne ungt blod holde hemmeligheder længere, sundere liv?Kredit:offentligt domæne I det der lyder som en scene fra en science fiction -film, forskere i 2005 syede gamle og unge mus sammen, så de delte et kredsløbssystem. Ungdommeligt blod foryngede tils
- Hvad ved vi om nano?
- Robo-journalistik vinder indpas i skiftende medielandskab
- Chokoladeindustrien driver skovrydning af Elfenbenskysten:rapport
- Hvad er tilpasningerne af Hibiscus Plant?
- Ville en ændring af betalingen af arbejdsindkomstskattefradraget hjælpe kæmpende familier?
- Et 4,4 millioner år gammelt skelet kunne afsløre, hvor tidligt mennesker begyndte at gå oprejst