


Kemisk datahåndtering:En åben vej frem
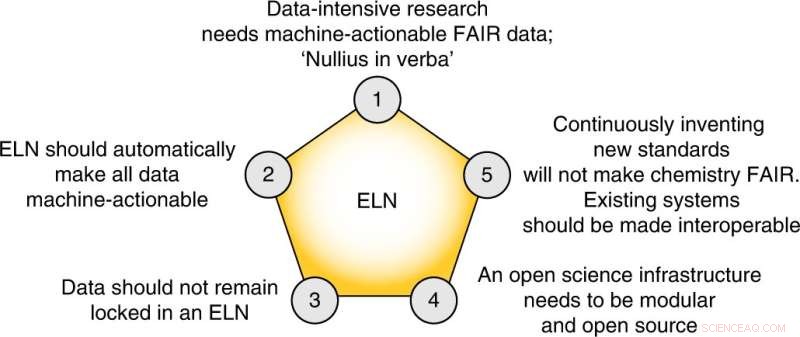
De fem kerneteser i dette perspektiv. Kredit:Nature Chemistry (2022). DOI:10.1038/s41557-022-00910-7
Et af de mest udfordrende aspekter af moderne kemi er håndtering af data. For eksempel, når de syntetiserer en ny forbindelse, vil forskere gennemgå flere forsøg med trial-and-error for at finde de rigtige betingelser for reaktionen, hvilket i processen genererer enorme mængder af rådata. Sådanne data er af utrolig værdi, da maskinlæringsalgoritmer ligesom mennesker kan lære meget af mislykkede og delvist vellykkede eksperimenter.
Den nuværende praksis er dog kun at offentliggøre de mest succesrige eksperimenter, da intet menneske på en meningsfuld måde kan behandle det enorme antal mislykkede eksperimenter. Men AI har ændret dette; det er præcis, hvad disse maskinlæringsmetoder kan gøre, forudsat at dataene er gemt i et format, der kan bruges på maskinen, så alle kan bruge det.
"I lang tid var vi nødt til at komprimere information på grund af det begrænsede sideantal i trykte tidsskriftsartikler," siger professor Berend Smit, der leder Laboratory of Molecular Simulation ved EPFL Valais Wallis. "I dag har mange tidsskrifter ikke engang trykte udgaver længere; kemikere kæmper dog stadig med reproducerbarhedsproblemer, fordi tidsskriftsartikler mangler afgørende detaljer. Forskere 'spilder' tid og ressourcer på at replikere 'mislykkede' eksperimenter af forfattere og kæmper for at bygge oven på offentliggjorte resultater, da rådata sjældent offentliggøres."
Men volumen er ikke det eneste problem her; datadiversitet er en anden:Forskergrupper bruger forskellige værktøjer som Electronic Lab Notebook-software, som gemmer data i proprietære formater, der nogle gange er inkompatible med hinanden. Denne mangel på standardisering gør det næsten umuligt for grupper at dele data.
Nu har Smit sammen med Luc Patiny og Kevin Jablonka på EPFL udgivet et perspektiv i Nature Chemistry præsenterer en åben platform for hele kemi-workflowet:fra starten af et projekt til dets udgivelse.
Forskerne forestiller sig, at platformen "sømtløst" integrerer tre afgørende trin:dataindsamling, databehandling og datapublicering - alt sammen med minimale omkostninger for forskerne. Det vejledende princip er, at data skal være FAIR:let at finde, tilgængelige, interoperable og genbrugelige. "På tidspunktet for dataindsamlingen vil dataene automatisk blive konverteret til et standard FAIR-format, hvilket gør det muligt automatisk at publicere alle 'mislykkede' og delvist vellykkede eksperimenter sammen med det mest succesfulde eksperiment," siger Smit.
Men forfatterne går et skridt videre og foreslår, at data også skal være maskinelt anvendelige. "Vi ser flere og flere datavidenskabelige studier i kemi," siger Jablonka. "Faktisk forsøger de seneste resultater inden for maskinlæring at tackle nogle af de problemer, kemikere mener er uløselige. For eksempel har vores gruppe gjort enorme fremskridt med at forudsige optimale reaktionsforhold ved hjælp af maskinlæringsmodeller. Men disse modeller ville være meget mere værdifulde, hvis de kunne også lære reaktionsbetingelser, der fejler, men ellers forbliver de partiske, fordi kun de vellykkede betingelser offentliggøres."
Endelig foreslår forfatterne fem konkrete trin, som feltet skal tage for at skabe en FAIR-datahåndteringsplan:
- Kemisamfundet bør omfavne sine egne eksisterende standarder og løsninger.
- Tidsskrifter skal gøre deponering af genanvendelige rådata, hvor der findes fællesskabsstandarder, obligatorisk.
- Vi er nødt til at omfavne offentliggørelsen af "mislykkede" eksperimenter.
- Electronic Lab Notebooks, der ikke tillader eksport af alle data til en åben maskine-handlingsform, bør undgås.
- Data-intensiv forskning skal indgå i vores læseplaner.
"Vi mener, at der ikke er behov for at opfinde nye filformater eller teknologier," siger Patiny. "I princippet er al teknologien der, og vi er nødt til at omfavne eksisterende teknologier og gøre dem interoperable."
Forfatterne påpeger også, at blot at gemme data i enhver elektronisk laboratorie-notesbog - den nuværende tendens - ikke nødvendigvis betyder, at mennesker og maskiner kan genbruge dataene. Dataene skal snarere struktureres og offentliggøres i et standardiseret format, og de skal også indeholde tilstrækkelig kontekst til at muliggøre datadrevne handlinger.
"Vores perspektiv giver en vision om, hvad vi mener er nøglekomponenterne til at bygge bro mellem data og maskinlæring til kerneproblemer i kemi," siger Smit. "Vi leverer også en åben videnskabelig løsning, hvor EPFL kan tage føringen." + Udforsk yderligere
Maskinlæring knækker oxidationstilstandene af krystalstrukturer
Sidste artikelUdforsker monoatomiske platinkatalysatorer
Næste artikelSolbrint:Bedre fotoelektroder gennem flashopvarmning
 Varme artikler
Varme artikler
-
 Intelligens, der kommer fra tilfældige polymernetværkStemmegenkendelse ved hjælp af sulfoneret polyanilin. Kredit:Creative Commons CC-BY, kredit:2021, Yuki Usami et al., Avancerede materialer Reservoir computing (RC) tackler komplekse problemer ved
Intelligens, der kommer fra tilfældige polymernetværkStemmegenkendelse ved hjælp af sulfoneret polyanilin. Kredit:Creative Commons CC-BY, kredit:2021, Yuki Usami et al., Avancerede materialer Reservoir computing (RC) tackler komplekse problemer ved -
 Undersøgelse finder beviser for eksistensen af undvigende metabolonKredit:CC0 Public Domain I mere end 40 år, videnskabsmænd har antaget eksistensen af enzymklynger, eller metaboloner, ved at lette forskellige processer i celler. Ved hjælp af en ny billedtekno
Undersøgelse finder beviser for eksistensen af undvigende metabolonKredit:CC0 Public Domain I mere end 40 år, videnskabsmænd har antaget eksistensen af enzymklynger, eller metaboloner, ved at lette forskellige processer i celler. Ved hjælp af en ny billedtekno -
 Sådan replikeres havvand hjemmeHvis du ikke bor i nærheden af havet og vil lave forsøg med havvand, kan du nemt replikere havvand derhjemme. Undertiden bruges havvand til holistiske behandlinger, landbrug og aircondition. Havv
Sådan replikeres havvand hjemmeHvis du ikke bor i nærheden af havet og vil lave forsøg med havvand, kan du nemt replikere havvand derhjemme. Undertiden bruges havvand til holistiske behandlinger, landbrug og aircondition. Havv -
 Luftstabile iboende strækbare farvekonverteringslag til strækbare skærmeKredit:CC0 Public Domain Udviklingen af et strækbart display, der kan bøjes, strakt, og knyttet til huden som en fritstående film optrådte i science fiction-film forventes at være et skridt nærm
Luftstabile iboende strækbare farvekonverteringslag til strækbare skærmeKredit:CC0 Public Domain Udviklingen af et strækbart display, der kan bøjes, strakt, og knyttet til huden som en fritstående film optrådte i science fiction-film forventes at være et skridt nærm
- Hvordan at ændre verdens fødevaresystemer kan hjælpe med at beskytte planeten
- Hvordan er Royal Jelly Harvested?
- Svovlåndning hos pattedyr
- NASAs mineralstøvdetektor begynder at indsamle data
- Nanoforskere udvikler sig sikrere, hurtigere måde at fjerne forurenende stoffer fra vandet
- Autonome køretøjer kan narre til at se ikke-eksisterende forhindringer