


Hvorfor er det stadig så svært at optimere dem i en verden drevet af katalysatorer?
Vi er afhængige af katalysatorer for at omdanne vores mælk til yoghurt, til at producere Post-It-sedler fra papirmasse og for at låse op for vedvarende energikilder som biobrændstoffer. At finde optimale katalysatormaterialer til specifikke reaktioner kræver besværlige eksperimenter og beregningsintensive kvantekemiberegninger.
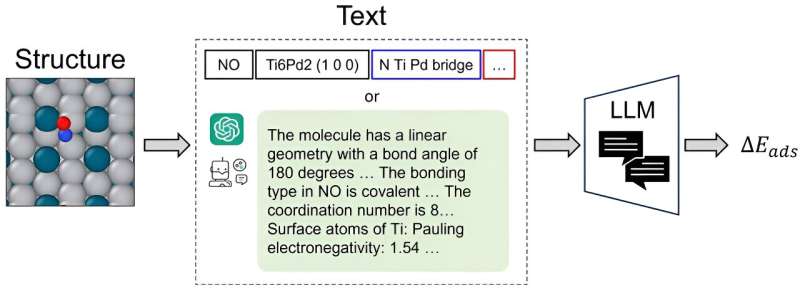
Ofte henvender videnskabsmænd sig til grafiske neurale netværk (GNN'er) for at fange og forudsige den strukturelle forvikling af atomare systemer, et effektivt system først efter den omhyggelige konvertering af 3D-atomstrukturer til præcise rumlige koordinater på grafen er fuldført.
CatBERTa, en transformatormodel for energiforudsigelse, blev udviklet af forskere ved Carnegie Mellon University's College of Engineering som en tilgang til at tackle forudsigelse af molekylære egenskaber ved hjælp af maskinlæring.
"Dette er den første tilgang, der bruger en stor sprogmodel (LLM) til denne opgave, så vi åbner en ny vej til modellering," sagde Janghoon Ock, Ph.D. kandidat i Amir Barati Farimanis laboratorium.
En vigtig differentiator er modellens evne til direkte at anvende tekst (naturligt sprog) uden nogen forbehandling til at forudsige egenskaberne af adsorbat-katalysatorsystemet. Denne metode er især gavnlig, da den forbliver let fortolkelig af mennesker, hvilket giver forskere mulighed for problemfrit at integrere observerbare funktioner i deres data.
Derudover giver anvendelsen af transformermodellen i deres forskning betydelig indsigt. Især selvopmærksomhedsscorerne er afgørende for at forbedre deres forståelse af fortolkning inden for denne ramme.
"Jeg kan ikke sige, at det vil være et alternativ til state-of-the-art GNN'er, men måske kan vi bruge dette som en komplementær tilgang," sagde Ock. "Som man siger:'Jo flere, jo bedre'."
Modellen leverer prædiktiv nøjagtighed, der kan sammenlignes med den, der er opnået med tidligere versioner af GNN'er. Navnlig var CatBERTa mere succesfuld, når den blev trænet på datasæt i begrænset størrelse. Derudover har CatBERTa overgået fejlannulleringsevnerne for eksisterende GNN'er.
Holdet fokuserede på adsorptionsenergi, men sagde, at tilgangen kan udvides til andre egenskaber, såsom HOMO-LUMO-gabet og stabiliteter relateret til adsorbat-katalysatorsystemer, givet et passende datasæt.
Ved at integrere mulighederne i omfattende sprogmodeller med kravene til katalysatoropdagelse, sigter teamet mod at strømline processen med effektiv katalysatorscreening. Ock arbejder på at forbedre modellens nøjagtighed.
Resultaterne er offentliggjort i tidsskriftet ACS Catalysis .
Flere oplysninger: Janghoon Ock et al, Catalyst Energy Prediction with CatBERTa:Afsløring af Feature Exploration Strategies through Large Language Models, ACS Catalysis (2023). DOI:10.1021/acscatal.3c04956
Journaloplysninger: ACS-katalyse
Leveret af Carnegie Mellon University Mechanical Engineering
 Varme artikler
Varme artikler
-
 Molekylære fabrikker:Kombinationen mellem natur og kemi er funktionelPå molekylære fabrikker injiceret i zebrafiskembryoner, en farvereaktion opstår, når det fangede enzym (peroxidase) virker. Forskerne beviser således, at kombinationen af syntetiske organeller og na
Molekylære fabrikker:Kombinationen mellem natur og kemi er funktionelPå molekylære fabrikker injiceret i zebrafiskembryoner, en farvereaktion opstår, når det fangede enzym (peroxidase) virker. Forskerne beviser således, at kombinationen af syntetiske organeller og na -
 Neutroner gør strukturelle ændringer i molekylære børster synligeDr. Lester Barnsley, instrumentforsker ved Forschungszentrum Juelich, ved det lillevinklede neutronspredningssystem KWS-1 i Heinz Maier-Leibnitz Zentrum ved Heinz Maier-Leibnitz Research Neutron Sourc
Neutroner gør strukturelle ændringer i molekylære børster synligeDr. Lester Barnsley, instrumentforsker ved Forschungszentrum Juelich, ved det lillevinklede neutronspredningssystem KWS-1 i Heinz Maier-Leibnitz Zentrum ved Heinz Maier-Leibnitz Research Neutron Sourc -
 Teknik muliggør udskrivning og omskrivning af farvebillederDisse strukturelle farver blev trykt på det samme ark papir belagt med copolymerer ved anvendelse af ammoniumpersulfat og ethanol. Hydrogenbromid blev brugt til at neutralisere opløsningsmidlerne og o
Teknik muliggør udskrivning og omskrivning af farvebillederDisse strukturelle farver blev trykt på det samme ark papir belagt med copolymerer ved anvendelse af ammoniumpersulfat og ethanol. Hydrogenbromid blev brugt til at neutralisere opløsningsmidlerne og o -
 Kemikere udnytter kunstig intelligens for at forudsige fremtiden (af kemiske reaktioner)Kredit:CC0 Public Domain Til fremstilling af medicin, kemikere skal finde de rigtige kombinationer af kemikalier for at lave de nødvendige kemiske strukturer. Dette er mere kompliceret end det lyd
Kemikere udnytter kunstig intelligens for at forudsige fremtiden (af kemiske reaktioner)Kredit:CC0 Public Domain Til fremstilling af medicin, kemikere skal finde de rigtige kombinationer af kemikalier for at lave de nødvendige kemiske strukturer. Dette er mere kompliceret end det lyd
- Hvad er nogle interessante fakta om Stratus Clouds?
- Billede:Cheops solceller
- Porsche trodser uroligheder, og Porsche går for fuld gas med stor succes-børsnotering
- I Indonesien, unge og gamle deler falske nyheder på sociale medier
- USA inviterer verdens luftfartsmyndigheder til møde om Boeings 737 MAX
- Deep-time Digital Earth-programmet:Datadrevet opdagelse i geovidenskab