


Domæneviden driver datadrevet kunstig intelligens i brøndlogning
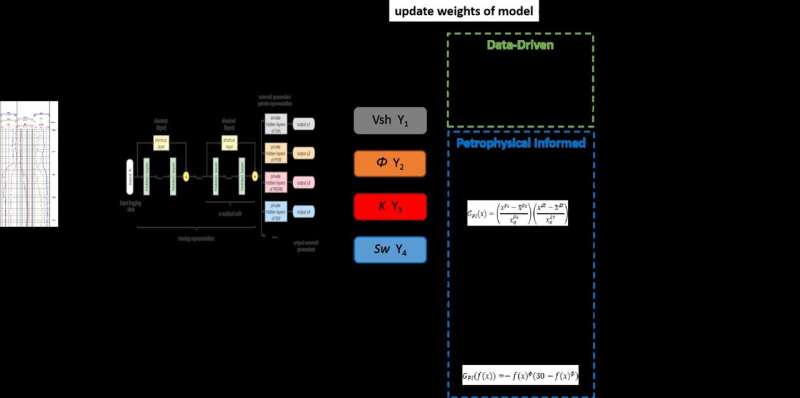
Datadrevet kunstig intelligens, såsom deep learning og forstærkende læring, besidder kraftfulde dataanalysemuligheder. Disse teknikker muliggør statistisk og probabilistisk analyse af data, hvilket letter kortlægningen af relationer mellem input og output uden at være afhængig af forudbestemte fysiske antagelser.
Centralt i processen med at træne datadrevne modeller er udnyttelsen af en tabsfunktion, som beregner forskellen mellem modellens output og de ønskede målresultater (labels). Optimizeren justerer derefter modellens parametre baseret på tabsfunktionen for at minimere forskellen mellem output og labels.
I mellemtiden involverer geofysisk logning et væld af domæneviden, matematiske modeller og fysiske modeller. Afhængigheden af udelukkende datadrevne modeller kan nogle gange give resultater, der modsiger etableret viden. Derudover kan træningsdata med ujævn fordeling og subjektive etiketter også påvirke ydeevnen af datadrevne modeller.
En nylig undersøgelse offentliggjort i Artificial Intelligence in Geoscience rapporterede implementeringen af begrænsninger på træningen af datadrevne maskinlæringsmodeller ved hjælp af logningsresponsfunktioner i brøndlogning af reservoirparameterforudsigelsesopgaver.
"Vores model, kaldet Petrophysics Informed Neural Network (PINN), integrerer petrofysiske begrænsninger i tabsfunktionen for at vejlede træning," siger undersøgelsens første forfatter, Rongbo Shao, en Ph.D. kandidat fra China University of Petroleum-Beijing. "Under modeltræning, hvis modeloutputtet adskiller sig fra petrofysisk viden, straffes tabsfunktionen af petrofysiske begrænsninger. Dette bringer output tættere på den teoretiske værdi og reducerer virkningen af mærkningsfejl på modeltræning."
Derudover hjælper denne tilgang med at skelne de korrekte relationer fra træningsdata, især når der er tale om små stikprøvestørrelser.
"Vi introducerer tilladte fejl og petrofysiske begrænsningsvægte for at gøre indflydelsen af mekanismemodeller i maskinlæringsmodellen mere fleksibel," uddyber Shao. "Vi evaluerede PINN-modellens evne til at forudsige reservoirparametre ved hjælp af målte data."
Shao og hans kolleger fandt ud af, at modellen har forbedret nøjagtighed og robusthed sammenlignet med rene datadrevne modeller. Ikke desto mindre bemærkede forskerne, at valg af petrofysiske begrænsningsvægte og tilladte fejl forbliver subjektivt og kræver derfor yderligere udforskning.
Tilsvarende forfatter Prof Lizhi Xiao fra China University of Petroleum understreger betydningen af denne forskning, "Integration af datadrevne AI-modeller med videndrevne mekanismemodeller er et lovende forskningsområde. Succesen med PINN-modellen inden for brøndlogning er et væsentligt skridt fremad. for geovidenskab i denne retning."
Xiao understreger behovet for fortsat forfining, "Udvælgelsen af petrofysiske begrænsningsvægte og tilladte fejl, samt tilpasningsevnen af domæneviden til forskellige geologiske lag, giver løbende udfordringer. Derudover er kvaliteten af datasæt afgørende for anvendelsen af AI i geofysisk logning Der er behov for omfattende, offentligt tilgængelige brøndlogningsdatasæt med høj kvalitet og kvantitet."
Flere oplysninger: Rongbo Shao et al., Reservoir-evaluering ved hjælp af petrofysik-informeret maskinlæring:Et casestudie, Artificial Intelligence in Geosciences (2024). DOI:10.1016/j.aiig.2024.100070
Leveret af KeAi Communications Co.
 Varme artikler
Varme artikler
-
 Forskere bygger kanoner til test af sæler i kulminerMissouri S&T lektor i sprængstofteknik, Dr. Kyle Perry, overvåger eleverne, Frank Schott (midten) og Ethan Steward (højre), lastning af en kanon med projektiler til test af betonkulminesætninger. Kred
Forskere bygger kanoner til test af sæler i kulminerMissouri S&T lektor i sprængstofteknik, Dr. Kyle Perry, overvåger eleverne, Frank Schott (midten) og Ethan Steward (højre), lastning af en kanon med projektiler til test af betonkulminesætninger. Kred -
 Hurtig opvarmning i Maine-bugten vender 900 års afkølingEn Arctica islandica-skal sætter sig på gelænderet af ESS Pursuit under et forskningstogt i Mid-Atlantic Bight, syd for Maine-bugten. En ny WHOI co-ledet undersøgelse finder, at hurtig opvarmning af M
Hurtig opvarmning i Maine-bugten vender 900 års afkølingEn Arctica islandica-skal sætter sig på gelænderet af ESS Pursuit under et forskningstogt i Mid-Atlantic Bight, syd for Maine-bugten. En ny WHOI co-ledet undersøgelse finder, at hurtig opvarmning af M -
 Det Indiske Ocean forårsager tørke og hedebølger i SydamerikaDen marine hedebølge, der ledsagede den sydamerikanske tørke i 2013/14, var en af de stærkeste, der nogensinde er registreret for området. Tendenser viser, at disse marine hedebølger bliver længere,
Det Indiske Ocean forårsager tørke og hedebølger i SydamerikaDen marine hedebølge, der ledsagede den sydamerikanske tørke i 2013/14, var en af de stærkeste, der nogensinde er registreret for området. Tendenser viser, at disse marine hedebølger bliver længere, -
 Debunker befolkningsbombenDe frygtelige advarsler er overalt i disse dage om katastrofale klimaændringer, især farerne ved overbefolkning og afbrænding af fossile brændstoffer. UTMs Pierre Desrochers og Joanna Szurmak ser det
Debunker befolkningsbombenDe frygtelige advarsler er overalt i disse dage om katastrofale klimaændringer, især farerne ved overbefolkning og afbrænding af fossile brændstoffer. UTMs Pierre Desrochers og Joanna Szurmak ser det
- For moratorium for at sende kommandoer til Mars, give Solen skylden
- Kunstig intelligens bruges til bedre at overvåge Maines skove
- Sætter et spin på Heusler-legeringer
- Mystisk geomagnetisk spike 3, 000 år siden udfordrer vores forståelse af Jordens indre
- Test viser, at droner kan bruge autonom teknologi til at undvige anden lufttrafik
- Stor Hadron Collider presser computeren til det yderste