


TACC COVID-19 Twitter-datasæt muliggør samfundsvidenskabelig forskning om pandemi
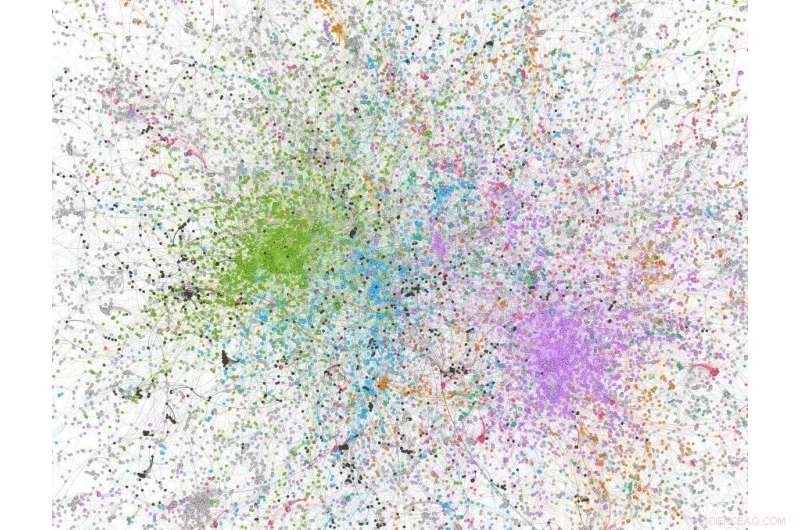
Netværksanalysetal udledt af en stikprøve på 100, 000 tweets med 'covid' i tweetet; noder farvet med grønt er alt-højre/stærkt konservative Twitter-brugere/-organisationer. Kredit:Dhiraj Murthy, UT Austin
Af de utallige måder, forskere bekæmper spredningen af coronavirus, at studere Tweets er måske ikke det første, der kommer til at tænke på. Men nu, som i tidligere kriser, at benytte sig af en af verdens førende meddelelsestjenester i realtid kan hjælpe med at identificere nye pandemiske hotspots, fremhæve nye symptomer, eller fortolke, hvordan mennesker og samfund reagerer på ordrer om at praktisere social distancering.
Texas Advanced Computing Center (TACC)'s ekspertdatavidenskabsteam har tidligere faciliteret analyse af sociale medier, og har udviklet maskinlæringsværktøjer til bedre at trække nåle af indsigt ud af de enorme høstakke i Twitterverse.
Fra marts, TACC begyndte at indtage store mængder tweets dagligt - omkring 40 millioner beskeder, hvoraf en million er unikke. Ved at kombinere deres samling med lignende indsats fra grupper på UT Austin, University of Southern California, og George State University, de har udvidet deres samling af COVID-19-relaterede tweets tilbage til januar. (Sidste uge, Twitter annoncerede, at det ville frigive nye API-endepunkter til sin egen COVID-19-relaterede tweets-samling til godkendte udviklere og forskere.)
"Der er stor interesse for disse typer af samlinger. Det er meget nyttigt inden for datavidenskab, " sagde Weijia Xu, der leder Scalable Computational Intelligence-gruppen hos TACC.
I dag, TACC annoncerede et nyt GitHub-lager, hvor interesserede forskere kan få adgang til både pointere til rå Twitter-data relateret til COVID-19 og storskalaanalyser faciliteret af TACC's supercomputere.
Den første af de analyser, der er tilgængelige for forskere, er et sæt af n-gram:sammenhængende sekvenser af ord fra en given prøve af tweets. Top 1, 000 en-, to-, og sekvenser på tre ord er blevet samlet for hver dag af pandemien. At samle selv et enkelt 1 gram fra flere millioner tweets kan tage op til en time på en bærbar computer på grund af mængden af databehandling involveret, men kan klares på få minutter på TACC's supercomputere.
TACC-forskerholdet, ledet af Xu, har også arbejdet med emnemodelleringsanalyser, identificere termer, der ofte optræder i forbindelse med hinanden, dog ikke nødvendigvis i orden. Disse vil blive tilføjet til GitHub-lageret i de kommende uger.
Begge metoder til klyngedannelse kan være nyttige til at identificere tendenser i, hvordan pandemien, og folks reaktion på det, udvikler sig.
Fremtidige projekter, der bruger dataene, omfatter en søgbar offentlig database; enhedsanalyse – inspicering af tweets for kendte enheder såsom offentlige personer eller organisationer og returnering af oplysninger om disse enheder; og hændelsesdetektering – registrerer automatisk forekomsten af hændelser og kategoriserer dem.
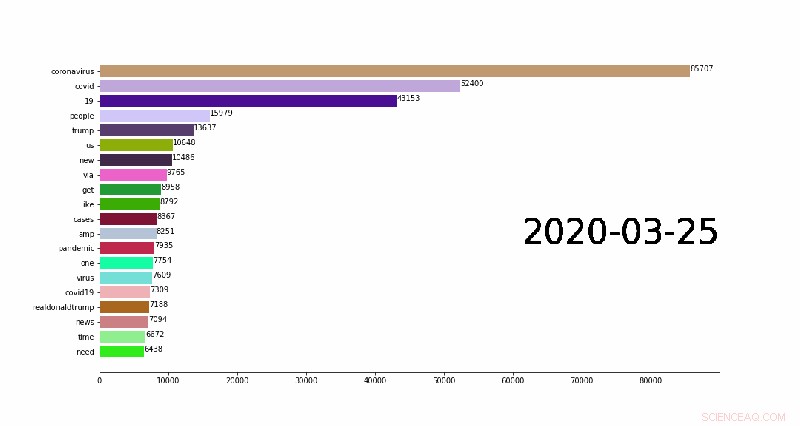
En animation, der viser de 20 bedste daglige n-gram (almindelige ord i Twitter-indlæg), der skifter overarbejde. Kredit:Weijia Xu, TACC
Disse bestræbelser vil blive faciliteret af værktøjer udviklet hos TACC, ligesom Domain Information &Vocabulary Extraction-projektet, en National Science Foundation-finansieret indsats for at udvinde biologiske enheder fra publikationer og andre tekstdokumenter ved hjælp af maskinlæring, som er tilpasset til andre former for udsugning.
TACC's hovedmål - her, som i de fleste ting - er at lette andres forskning og magtopdagelser. "Vi er mest interesserede i at give folk adgang til kuraterede datasæt og hjælpe dem med at lave research, " sagde Xu. "Vi samler ind, gøre rent, og behandler data, så det er klar til andre at bruge."
Forskere fra University of Texas i Austin (UT Austin) er blandt de første til at udtrykke interesse for at bruge TACC COVID-19 Twitter-datasættene til målrettet forskning.
"The TACC COVID-19 Twitter collection will be invaluable in enabling us to model communication patterns and topics that emerge across stages of the disease, " said Sharon Stover, a professor in the Moody College of Communications. "We may be able to compare the timeline to similar data from other countries such as China that experienced the epidemic earlier. This may lead us toward understanding when typical responses occur and help us to characterize how populations make sense of health pandemics at certain stages in an epidemic's process."
Strover is particularly interested in learning how one might segment tweets by certain population features to learn more about sub-networks that pass along certain information—or ignore it.
Dhiraj Murthy, an associate professor of Journalism and Sociology at UT Austin and author of the first scholarly book about Twitter, plans to use the dataset for his academic work.
"My lab is in the very initial stages of using these data to study two research questions:To what extent is fake news, misinformation, and disinformation regarding COVID-19 present on social media platforms? And:Are social media platforms being used as venues for racist messaging against people of Chinese/Asian origin within COVID-19-related posts?"
Matt Lease, from the UT School of Information, has been using the database to research misinformation in collaboration with Murthy, and also to identify incidents of racist messaging. "The large dataset TACC is collecting, along with its computing and storage services, plus excellent researchers and staff, makes it a fantastic resource for researchers interested in studying and combatting the spread of racist messaging on Twitter."
Both in the moment, and for retrospective analyses, Twitter data can be an incredible resource.
Said TACC research associate Ruizhu Huang:"The large volume of tweets collected at TACC provides a valuable date source to explore various perspectives on COVID-19. And the storage and supercomputing power at TACC will tremendously speed up the data analysis process."
 Varme artikler
Varme artikler
-
 Cigaretter væver en kompleks vej gennem det sidste århundrede, historiker fundHistorikeren Sarah Milov sagde, at hun var overrasket over græsrodsnaturen i anti-rygebevægelsen i 1970erne og 80erne. Kredit:Billede til højre af Dan Addison, Universitetets kommunikation Tobak e
Cigaretter væver en kompleks vej gennem det sidste århundrede, historiker fundHistorikeren Sarah Milov sagde, at hun var overrasket over græsrodsnaturen i anti-rygebevægelsen i 1970erne og 80erne. Kredit:Billede til højre af Dan Addison, Universitetets kommunikation Tobak e -
 Hvad er en fejlmargin? Dette statistiske værktøj kan hjælpe dig med at forstå vaccineforsøg og …Jo større stikprøvestørrelsen er, jo mere nøjagtig forudsigelsen er og jo mindre fejlmargin. Kredit:Fadethree via Wikimedia Commons I det sidste år, statistikker har været usædvanligt vigtige i ny
Hvad er en fejlmargin? Dette statistiske værktøj kan hjælpe dig med at forstå vaccineforsøg og …Jo større stikprøvestørrelsen er, jo mere nøjagtig forudsigelsen er og jo mindre fejlmargin. Kredit:Fadethree via Wikimedia Commons I det sidste år, statistikker har været usædvanligt vigtige i ny -
 Udforskning af 3-D-teknologi i keramikstudier:Det er fremtidenKredit:Leiden Universitet I det arkæologiske fakultets depoter, mange artefakter, akkumuleret efter årtiers feltarbejde i hele Europa og Mellemøsten, er gemt. Et nyt projekt, Leiden Inventory Depo
Udforskning af 3-D-teknologi i keramikstudier:Det er fremtidenKredit:Leiden Universitet I det arkæologiske fakultets depoter, mange artefakter, akkumuleret efter årtiers feltarbejde i hele Europa og Mellemøsten, er gemt. Et nyt projekt, Leiden Inventory Depo -
 Virtuel virkelighed i uddannelse er emnet for tidsskriftets specialudgaveKredit:CC0 Public Domain Teknologien giver undervisere ufattelige værktøjer, der hurtigt kommer i forgrunden, især på grund af restriktioner på grund af den igangværende COVID-19-pandemi. At skriv
Virtuel virkelighed i uddannelse er emnet for tidsskriftets specialudgaveKredit:CC0 Public Domain Teknologien giver undervisere ufattelige værktøjer, der hurtigt kommer i forgrunden, især på grund af restriktioner på grund af den igangværende COVID-19-pandemi. At skriv
- Kløvervækst i Mars-lignende jordbund boostet af bakteriel symbiose
- Grønlands istabshastighed
- Nye undersøgelser afslører dyb historie om arkaiske mennesker i det sydlige Sibirien
- Avanceret teknologi kan indikere, hvordan hjernen lærer ansigter
- Top 5 gadgets til den højteknologiske soldat
- Sådan finder du området med trekanter og trapezoider