


Hvad er en fejlmargin? Dette statistiske værktøj kan hjælpe dig med at forstå vaccineforsøg og politiske meningsmålinger
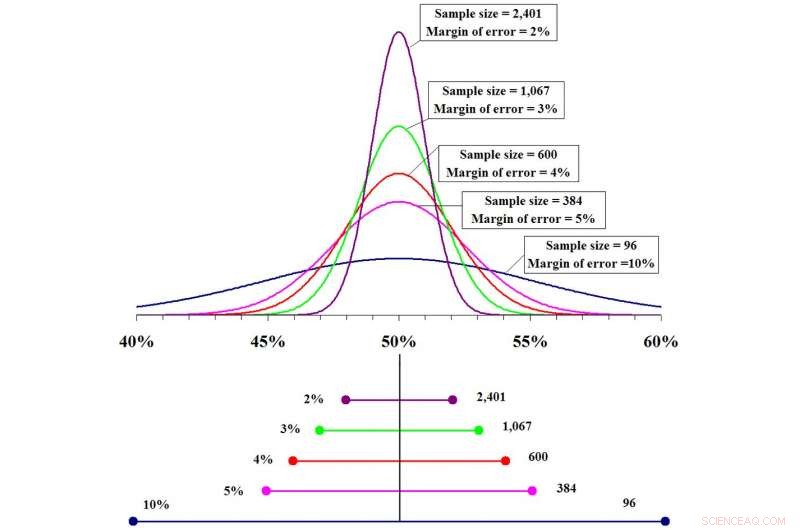
Jo større stikprøvestørrelsen er, jo mere nøjagtig forudsigelsen er og jo mindre fejlmargin. Kredit:Fadethree via Wikimedia Commons
I det sidste år, statistikker har været usædvanligt vigtige i nyhederne. Hvor nøjagtig er den COVID-19-test, du eller andre bruger? Hvordan kender forskerne effektiviteten af nye terapier til COVID-19-patienter? Hvordan kan tv-netværk forudsige valgresultatet længe før alle stemmesedler er talt op?
Hvert af disse spørgsmål indebærer en vis usikkerhed, men det er stadig muligt at lave præcise forudsigelser, så længe denne usikkerhed er forstået. Et værktøj statistikere bruger til at kvantificere usikkerhed kaldes fejlmarginen.
Begrænsede data
Jeg er statistiker, og en del af mit job er at komme med slutninger og forudsigelser. Med ubegrænset tid og penge, Jeg kunne simpelthen teste eller undersøge hele gruppen af mennesker, jeg er interesseret i, for at vurdere spørgsmålet i tankerne og finde det nøjagtige svar. For eksempel, for at finde ud af COVID-19-infektionsraten i USA, Jeg kunne simpelthen teste hele den amerikanske befolkning. Imidlertid, i den virkelige verden, du kan aldrig få adgang til 100 % af en befolkning.
I stedet, statistikere prøver en lille del af befolkningen og bygger en model til at lave en forudsigelse. Ved hjælp af statistisk teori, at resultatet fra stikprøven ekstrapoleres til at repræsentere hele populationen.
Ideelt set, en god stikprøve skal være repræsentativ for den samlede population, herunder køn, racemæssig mangfoldighed, socioøkonomisk mangfoldighed, livsstilsmønstre og andre demografiske mål. Jo større stikprøven er, jo mere ligner den den sande befolkning, og med en større prøve, jo mere sikre bliver statistikerne i deres forudsigelser. Men der vil altid være en vis usikkerhed.
Kvantificering af usikkerhed
Tag lægemiddeludvikling, for eksempel. Det er altid sandt at forudsige, at en ny medicin vil være et sted mellem 0% og 100% effektiv for alle på Jorden. Men det er ikke en særlig brugbar forudsigelse. Det er en statistikers opgave at indsnævre dette område til noget mere nyttigt. Statistikere kalder normalt dette interval for et konfidensinterval, og det er rækken af forudsigelser, inden for hvilken statistikere er meget sikre på, at det sande antal vil blive fundet.
Hvis en medicin blev testet på 10 personer, og syv af dem fandt det effektivt, den anslåede lægemiddeleffektivitet er 70 %. Men da målet er at forudsige effekten i hele befolkningen, statistikere skal tage højde for usikkerheden ved kun at teste 10 personer.
Konfidensintervaller beregnes ved hjælp af en matematisk formel, der omfatter stikprøvestørrelsen, rækken af svar og sandsynlighedslovene. I dette eksempel, konfidensintervallet vil være mellem 42 % og 98 % – et interval på 56 procentpoint. Efter kun at have testet 10 personer, man kan med stor sikkerhed sige, at stoffet er effektivt for mellem 42 % og 98 % af befolkningen i hele befolkningen.
Hvis du deler konfidensintervallet i to, du får fejlmarginen - i dette tilfælde, 28 %. Jo større fejlmarginen er, jo mindre præcis er forudsigelsen. Jo mindre fejlmarginen er, jo mere præcis er forudsigelsen. En fejlmargin på næsten 30 % er stadig en ret bred vifte.
Imidlertid, Forestil dig, at forskerne testede dette nye lægemiddel den 1. 000 mennesker i stedet for 10, og det var effektivt i 700 af dem. Den anslåede lægemiddeleffektivitet vil stadig være omkring 70 %, alligevel er denne forudsigelse meget mere nøjagtig. Konfidensintervallet for den større stikprøve vil være mellem 67 % og 73 % med en fejlmargin på 3 %. Man kan sige, at dette lægemiddel forventes at være 70 % effektivt, plus eller minus 3 %, for hele befolkningen.
Statistikere ville elske at kunne forudsige med 100 % nøjagtighed succes eller fiasko for en ny medicin eller de nøjagtige resultater af et valg. Imidlertid, dette er ikke muligt. Der er altid en vis usikkerhed, og fejlmarginen er det, der kvantificerer denne usikkerhed; det skal tages i betragtning, når man ser på resultater. I særdeleshed, fejlmarginen definerer rækken af forudsigelser, inden for hvilke statistikere er meget sikre på, at det sande antal vil blive fundet. En acceptabel fejlmargin er et spørgsmål om vurdering baseret på den grad af nøjagtighed, der kræves i de konklusioner, der skal drages.
Denne artikel er genudgivet fra The Conversation under en Creative Commons -licens. Læs den originale artikel. 
 Varme artikler
Varme artikler
-
 Ny tre fod høj slægtning til Tyrannosaurus rexRekonstruktion af tyrannosauroiden Suskityrannus hazelae fra den sene kridttid (~92 millioner år siden) i det nuværende New Mexico. Kredit:Andrey Atuchin En ny slægtning til Tyrannosaurus rex -
Ny tre fod høj slægtning til Tyrannosaurus rexRekonstruktion af tyrannosauroiden Suskityrannus hazelae fra den sene kridttid (~92 millioner år siden) i det nuværende New Mexico. Kredit:Andrey Atuchin En ny slægtning til Tyrannosaurus rex - -
 Forskere afslører mønstre for seksuelt misbrug i religiøse omgivelserKredit:CC0 Public Domain En nylig litteraturgennemgang af en kultekspert fra University of Alberta og hans tidligere kandidatstuderende tegner et overraskende og konsekvent billede af institutione
Forskere afslører mønstre for seksuelt misbrug i religiøse omgivelserKredit:CC0 Public Domain En nylig litteraturgennemgang af en kultekspert fra University of Alberta og hans tidligere kandidatstuderende tegner et overraskende og konsekvent billede af institutione -
 Valget i 2020 vil afgøre, hvilke stemmer der dominerer debatter om offentlige jorderUtahs Cottonwood Canyon er en populær vandredestination på føderalt land. Kredit:BLM Præsidentvalg er ængstelige tider for føderale jordagenturer og de mennesker, de tjener. Bureau of Land Managem
Valget i 2020 vil afgøre, hvilke stemmer der dominerer debatter om offentlige jorderUtahs Cottonwood Canyon er en populær vandredestination på føderalt land. Kredit:BLM Præsidentvalg er ængstelige tider for føderale jordagenturer og de mennesker, de tjener. Bureau of Land Managem -
 Bekæmpelse af tilbagefald i fængsler med planterFanger passer planter på Oregons Coffee Creek Correctional Facility. Kredit:John Vallis En undersøgelse fra Texas State University forsøgte at bestemme antallet af tilgængelige gartnerisamfundstje
Bekæmpelse af tilbagefald i fængsler med planterFanger passer planter på Oregons Coffee Creek Correctional Facility. Kredit:John Vallis En undersøgelse fra Texas State University forsøgte at bestemme antallet af tilgængelige gartnerisamfundstje
- Teamet finder Wigner-krystal - ikke Mott-isolator - i grafen med magisk vinkel
- Sådan identificeres vilde psilocybinsvampe
- En ny tilgang til forebyggelse af våbenrelateret vold på skoler i Californien
- Sådan beregnes Mmol
- Hvad er tre hovedelementer, der omfatter strukturen af organiske molekyler?
- Brasiliens politi anholder 4 for påstået hacking af myndigheder