


Dataforskere bygger mere ærlige forudsigelsesmodeller

Kredit:CC0 Public Domain
Den 3. nov. 2020 – og i mange dage efter – holdt millioner af mennesker et varsomt øje med modellerne til forudsigelse af præsidentvalget, der blev drevet af forskellige nyhedsmedier. Med så høje indsatser i spil, hvert flueben i en oversigt og et ryk i en graf kunne sende chokbølger af overfortolkning.
Et problem med rå opgørelser af præsidentvalget er, at de skaber en falsk fortælling om, at de endelige resultater stadig udvikler sig på drastiske måder. I virkeligheden, på valgaftenen er der ingen "at indhente bagfra" eller "at miste føringen", fordi stemmerne allerede er afgivet; vinderen har allerede vundet – vi ved det bare ikke endnu. Mere end blot at være upræcis, disse medrivende beskrivelser af afstemningsprocessen kan få resultaterne til at virke overdrevent mistænkelige eller overraskende.
"Forudsigelsesmodeller bruges til at træffe beslutninger, der kan have enorme konsekvenser for menneskers liv, " sagde Emmanuel Candès, Barnum-Simons-lærestolen i matematik og statistik på School of Humanities and Sciences ved Stanford University. "Det er ekstremt vigtigt at forstå usikkerheden omkring disse forudsigelser, så folk ikke træffer beslutninger baseret på falsk overbevisning."
En sådan usikkerhed var præcis hvad Washington Post dataforsker Lenny Bronner havde til formål at fremhæve i en ny forudsigelsesmodel, som han begyndte at udvikle til lokale Virginia-valg i 2019 og yderligere forfinet til præsidentvalget, med hjælp fra John Cherian, en aktuel ph.d. studerende i statistik på Stanford, som Bronner kendte fra deres bachelorstudier.
"Modellen handlede i virkeligheden om at tilføje kontekst til de resultater, der blev vist, " sagde Bronner. "Det handlede ikke om at forudsige valget. Det handlede om at fortælle læserne, at de resultater, de så, ikke afspejlede, hvor vi troede, valget ville ende."
Denne model er den første virkelige anvendelse af en eksisterende statistisk teknik udviklet på Stanford af Candès, tidligere postdoktor Yaniv Romano og tidligere kandidatstuderende Evan Patterson. Teknikken er anvendelig til en række forskellige problemer og, som i Postens prædikationsmodel, kunne bidrage til at højne betydningen af ærlig usikkerhed i prognoser. Mens Post fortsætter med at finjustere deres model til fremtidige valg, Candès anvender den underliggende teknik andre steder, herunder til data om COVID-19.
Undgå antagelser
For at skabe denne statistiske teknik, Candès, Romano og Evan Patterson kombinerede to forskningsområder - kvantilregression og konform forudsigelse - for at skabe det, Candès kaldte "det mest informative, velkalibreret række af forudsagte værdier, som jeg ved, hvordan man bygger."
Mens de fleste forudsigelsesmodeller forsøger at forudsige en enkelt værdi, ofte gennemsnittet (gennemsnittet) af et datasæt, kvantilregression estimerer en række plausible udfald. For eksempel, en person ønsker måske at finde den 90. kvantil, som er den tærskel, under hvilken den observerede værdi forventes at falde 90 procent af tiden. Når føjet til kvantilregression, konform forudsigelse - udviklet af computerforsker Vladimir Vovk - kalibrerer de estimerede kvantiler, så de er gyldige uden for en prøve, såsom for hidtil usete data. Til Postens valgmodel, det betød at bruge afstemningsresultater fra demografisk lignende områder til at hjælpe med at kalibrere forudsigelser om stemmer, der var udestående.
Det særlige ved denne teknik er, at den begynder med minimale forudsætninger indbygget i ligningerne. For at arbejde, imidlertid, det skal starte med et repræsentativt udsnit af data. Det er et problem for valgaftenen, fordi det første stemmetal - normalt fra små samfund med mere personlig afstemning - sjældent afspejler det endelige resultat.
Uden adgang til et repræsentativt udsnit af aktuelle stemmer, Bronner og Cherian måtte tilføje en antagelse. De kalibrerede deres model ved hjælp af stemmetal fra præsidentvalget i 2016, så når et område rapporterede 100 procent af deres stemmer, Postens model ville antage, at enhver ændring mellem det pågældende områdes 2020-stemmer og dets 2016-stemmer ville afspejles i tilsvarende amter. (Modellen vil derefter justere yderligere - hvilket reducerer indflydelsen af antagelsen - efterhånden som flere områder rapporterede 100 procent af deres stemmer.) For at kontrollere gyldigheden af denne metode, de testede modellen ved hvert præsidentvalg, begyndende med 1992, og fandt ud af, at dets forudsigelser nøje matchede resultaterne i den virkelige verden.
"Det, der er rart ved at bruge Emmanuels tilgang til dette, er, at fejlbjælkerne omkring vores forudsigelser er meget mere realistiske, og vi kan opretholde minimale antagelser, " sagde Cherian.
Visualisering af usikkerhed
I aktion, visualiseringen af Postens live-model var omhyggeligt designet til at fremtrædende vise disse fejlbjælker og den usikkerhed, de repræsenterede. The Post kørte modellen for at forudsige rækken af sandsynlige valgresultater i forskellige stater og amtstyper; amter blev kategoriseret efter deres demografi. I alle tilfælde, hver nominerede havde deres egen vandrette bjælke, der udfyldte fast - blå for Joe Biden, rødt for Donald Trump - for at vise kendte stemmer. Derefter, resten af søjlen indeholdt en gradient, der repræsenterede de mest sandsynlige udfald for de udestående stemmer, ifølge modellen. Det mørkeste område af gradienten var det mest sandsynlige resultat.
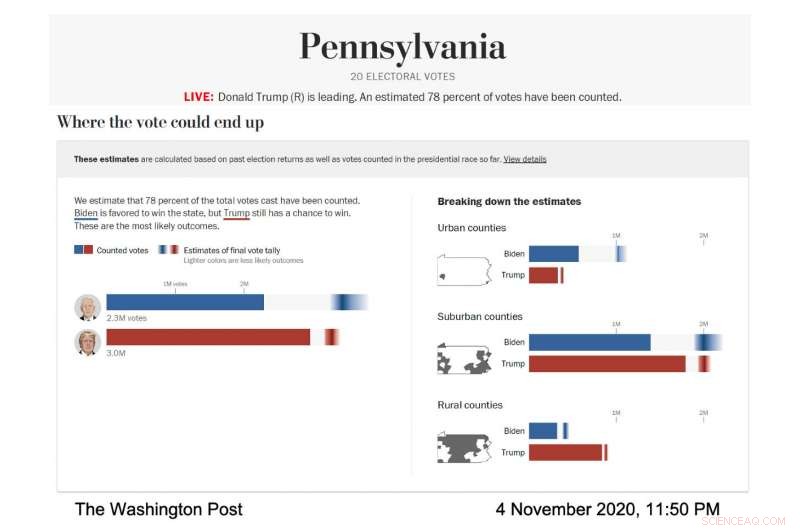
Skærmbillede af Washington Post valgmodel, viser stemmeforudsigelsen for Pennsylvania den 4. november, 2020. (Billedkredit:Courtesy of The Washington Post)
"Vi talte med forskere om visualisering af usikkerhed, og vi lærte, at hvis du giver nogen en gennemsnitlig forudsigelse, og så fortæller du dem, hvor meget usikkerhed der er involveret, de har en tendens til at ignorere usikkerheden, " sagde Bronner. "Så vi lavede en visualisering, der er meget "usikkerhed fremad." Vi ønskede at vise, dette er usikkerheden, og vi vil ikke engang fortælle dig, hvad vores gennemsnitlige forudsigelse er."
Mens valgaftenen skred frem, den mørkeste del af Bidens gradient i den samlede stemmevisualisering var længere til højre side af bjælken, hvilket betød, at modellen forudsagde, at han ville ende med flere stemmer. Hans gradient var også bredere og spredt asymmetrisk mod den højere stemmeside af bjælken, hvilket betød, at modellen forudsagde, at der var mange scenarier, med rimelige odds, hvor han ville vinde flere stemmer end det sandsynlige antal.
"På valgaftenen vi bemærkede, at fejlstængerne var meget korte på venstre side af Bidens bar og meget lange på højre side, " sagde Cherian. "Dette skyldtes, at Biden havde en masse opside til potentielt at udkonkurrere vores fremskrivning på en væsentlig måde, og han havde ikke så mange ulemper." Denne asymmetriske forudsigelse var en konsekvens af den særlige modelleringstilgang, der blev brugt af Cherian og Bronner . Fordi modellens prognoser blev kalibreret ved hjælp af resultater fra demografisk lignende amter, der var færdige med at rapportere deres stemmer, det blev klart, at Biden havde en god chance for at klare sig markant bedre end den demokratiske afstemning i 2016 i forstæder, mens det var yderst usandsynligt, at han ville klare sig værre.
Selvfølgelig, da stemmeoptællingen gik mod mål, gradienterne krympede, og Postens usikre forudsigelser så stadig mere sikre ud - en nervepirrende situation for dataforskere, der er bekymret for at overdrive sådanne vigtige konklusioner.
"Jeg var især bekymret for, at løbet ville komme ned til én stat, og vi ville have en forudsigelse på vores side i dagevis, som endte med ikke at gå i opfyldelse, sagde Bronner.
And that worry was well founded because the model did strongly and stubbornly predict a Biden win for several days as the final vote tallies crept in from not one state, but three:Wisconsin, Michigan and Pennsylvania.
"He ended up winning those states, so that ended up working well for the model, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, after all, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. Faktisk, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, imidlertid, is that the conclusions suffer if there isn't enough data. For eksempel, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, selvom, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."
 Varme artikler
Varme artikler
-
 Næsten halvdelen af lejerne i L.A. skylder tilbage huslejeUCLA Lewis Center for Regional Policy Studies I en ny undersøgelse blandt lejere i Los Angeles County, 49 % af husstandene rapporterede, at de ikke var i stand til at betale hele deres husleje und
Næsten halvdelen af lejerne i L.A. skylder tilbage huslejeUCLA Lewis Center for Regional Policy Studies I en ny undersøgelse blandt lejere i Los Angeles County, 49 % af husstandene rapporterede, at de ikke var i stand til at betale hele deres husleje und -
 Tager blommen fra hviden:Nyt filter adskiller trend og cyklus i makroøkonomiske dataKredit:CC0 Public Domain I forskning offentliggjort i International Journal of Computational Economics and Econometrics , Peng Zhou fra Cardiff University foreslår en ny filterteknik, der kan ad
Tager blommen fra hviden:Nyt filter adskiller trend og cyklus i makroøkonomiske dataKredit:CC0 Public Domain I forskning offentliggjort i International Journal of Computational Economics and Econometrics , Peng Zhou fra Cardiff University foreslår en ny filterteknik, der kan ad -
 Skal veganisme modtage den samme juridiske beskyttelse som en religion? En ekspert forklarerKredit:Shutterstock Veganisme er i fremmarch globalt – men det kan være omstridt. Først for nylig, redaktøren af et madmagasin jokede med, at veganere skulle tvangsfodres med kød, mens en bankme
Skal veganisme modtage den samme juridiske beskyttelse som en religion? En ekspert forklarerKredit:Shutterstock Veganisme er i fremmarch globalt – men det kan være omstridt. Først for nylig, redaktøren af et madmagasin jokede med, at veganere skulle tvangsfodres med kød, mens en bankme -
 Ny undersøgelse forbedrer skøn over skare visdomAaron Leventman vurderer, hvor mange perler der er i krukken. Kredit:Scott Wagner via Santa Fe Institute I 1907, en statistiker ved navn Francis Galton registrerede bidragene fra en vægtbedømmelse
Ny undersøgelse forbedrer skøn over skare visdomAaron Leventman vurderer, hvor mange perler der er i krukken. Kredit:Scott Wagner via Santa Fe Institute I 1907, en statistiker ved navn Francis Galton registrerede bidragene fra en vægtbedømmelse
- Polymer nanotråde, der samles i vinkelrette lag, kunne tilbyde vej til mindre chipkomponenter
- Alle måleenheder er nu knyttet til definerede konstanter frem for fysiske objekter
- Kinesisk hold sender kvantenøgler til jordstationer og teleporterer jord til satellitsignaler
- Hvad er en Fossil Imprint?
- "List of Fungi Benefits
- Hvordan fungerer skove i vedvarende organisk forurenende cykling?