


Sigter guld fra datafloden
Næste generations DNA-sekventeringsteknologier har oversvømmet databaser og harddiske verden over med store datasæt, men får forskerne mest muligt ud af denne syndflod af data? I en ny undersøgelse i oktobernummeret af Ansøgninger inden for plantevidenskab , Dr. Brent Berger og kolleger foreslår en måde at sigte det resterende guld ud af store sekvensdatasæt. Forfatterne viser, at en ny dataminingteknik kan bruges til at indsamle værdifuld information fra eksisterende datasæt, og bevise konceptet ved at hente sekvens fra gener, der påvirker de ejendommelige blomsterstrukturer, der ses i plantefamilien Goodeniaceae.
DNA -sekventering er blevet så billig, at selvom en forsker kun virkelig er interesseret i sekvensen af få gener, det er ofte mest praktisk at bare sekvensere hele genomet. Bioinformatiske teknikker kan udvælge den ønskede gensekvens senere, med mindre besvær end at målrette specifikke gener til sekvens. denne praksis, kendt som "genomskimming, "er blevet en stadig mere populær måde at besvare spørgsmål om forholdet mellem plantearter.
Præmissen for genomskimming er at bruge lavdækkende haglgeværsekventering til at hente DNA-sekvensen fra fraktioner af genomet med høj kopi. I haglgeværsekventering, genomet er opdelt i små bidder til sekventering, og derefter syet sammen igen ved hjælp af overlapningerne mellem bidderne, en proces kaldet montering. Mængden af "dækning" svarer til, hvor mange af disse små bidder er sekvenseret; jo højere dækning, jo nemmere er det at sy genomet sammen igen, resulterer i en mere komplet genomsekvens.
Men højere dækning er dyrere, og nogle spørgsmål kan besvares med en billigere, lavdækkende sekventeringskørsel. "Højkopierede fraktioner" af totalt genomisk DNA, såsom chloroplast -genomer eller nuklear ribosomalt DNA, er i større overflod i sekvenspuljen, og kan derfor sekvenseres fuldt ud selv i billige, kørsler med lav dækning. Sekvens fra disse genomiske fraktioner med høj kopi bruges typisk til at løse evolutionære forhold mellem forskellige arter og grupper. Men i processen med genomskimming, forskere producerer og kasserer derefter enorme mængder af potentielt værdifulde sekvensdata. "Mange genomskum-datasæt bruges til at samle chloroplastgenomet, som i vores tilfælde brugte kun 3% af de sekvenserede data, " bemærkede Dr. Dianella Howarth, en medforfatter på undersøgelsen.
I dette studie, forfatterne tog endnu et kig på et genom-skimming datasæt, der tidligere blev brugt til at løse evolutionære forhold i Goodeniaceae, en familie af planter, der almindeligvis kaldes "fanblomster" eller "halve blomster" på grund af deres spændende blomsterform, som ligner, at nogen har skåret blomsten i to. Forfatterne ønskede at se, om dette genom-skimming datasæt kunne loddes for mere information om genetikken bag denne unikke blomsterstruktur. De brugte adskillige softwarepakker til at samle tidligere ubrugte sekvensfragmenter fra den lave kopifraktion af det originale genom-skimming datasæt. De søgte derefter den resulterende samling efter sekvens fra et sæt gener kaldet CYCLOIDEA gener, som er involveret i blomsterstruktur og symmetri.
Forfatterne var i stand til at hente nok dele af generne, fra flere arter, for at skabe fulde justeringer af alle fire CYCLOIDEA gener i kernen Goodeniaceae. Disse data kan vise sig nyttige for fremtidige undersøgelser af udviklingen af den bizarre blomsterstruktur, der ses i denne gruppe. "Sammenligning af sekvenser fra CYCLOIDEA -lignende gener på tværs af denne klade kunne give fingerpeg om de præcise sekvensændringer, der resulterer i ændringer i blomstermorfologi, "forklarede Dr. Howarth.
Mere generelt, Dr. Howarth fortsatte, "Stykker af ethvert gen af interesse kan potentielt udvindes fra genom-skimming datasæt, der allerede er blevet afsluttet." Et stykke af et gen lyder måske ikke af meget, men der er et overraskende antal anvendelser til disse fragmenter. "Disse data kunne give tilstrækkelig information til at bestemme nyttige nukleare områder til fylogenetiske analyser eller lokalisere mulige gentubblinger af hændelser. Derudover kan prober til målberigelsessekventering kunne genereres hurtigt på tværs af en klade for at undersøge kandidatgener og deres regulatoriske regioner i evo-devo undersøgelser."
Data mining-tilgange som disse giver mulighed for meget mere fyldig brug af genom-skimming datasæt. Dette giver mulighed for at besvare vigtige spørgsmål med eksisterende data, og åbner døren for videnskabsmænd uden adgang til ressourcerne til at producere datasæt i stor skala - f.eks. forskere på mindre gymnasier eller lande uden store bevillingsgivende organer. Da DNA-sekvensdata fortsætter med at strømme ind, undersøgelser som denne peger på måder, hvorpå vi kan sikre, at vi ikke lader værdifuld information flyde forbi.
Sidste artikelZombiemyrehjerner efterladt intakte af svampeparasit
Næste artikelBestræbelser på at fange, redde Mexicos truede marsvin ende
 Varme artikler
Varme artikler
-
 Hvordan måler du lykke?Danmark er et af de lykkeligste lande i verden. Se flere følelsesbilleder. © iStockphoto.com/RichVintage Danskerne skal gøre noget rigtigt. I 2008, Danmark rangeret som den lykkeligste nation på plan
Hvordan måler du lykke?Danmark er et af de lykkeligste lande i verden. Se flere følelsesbilleder. © iStockphoto.com/RichVintage Danskerne skal gøre noget rigtigt. I 2008, Danmark rangeret som den lykkeligste nation på plan -
 "Fysiologisk"Mens fysiske og fysiologiske begge henviser til kroppe, betyder fysisk kroppen selv, mens fysiologisk henviser til kroppens funktioner. At forstå forskellene mellem fysisk og fysiologisk hjælper forsk
"Fysiologisk"Mens fysiske og fysiologiske begge henviser til kroppe, betyder fysisk kroppen selv, mens fysiologisk henviser til kroppens funktioner. At forstå forskellene mellem fysisk og fysiologisk hjælper forsk -
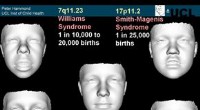 DysmorfologiBillede høflighed UCL Institute of Child Health Forældre, der har mistanke om, at deres barn kan have en genetisk lidelse, har et nyt værktøj i deres læges diagnostiske arsenal. En britisk læge har f
DysmorfologiBillede høflighed UCL Institute of Child Health Forældre, der har mistanke om, at deres barn kan have en genetisk lidelse, har et nyt værktøj i deres læges diagnostiske arsenal. En britisk læge har f -
 Ny undersøgelse forudsiger verdensomspændende ændringer i lavvandede rev-økosystemer, når vande…Reef Life Survey-dykker vurderer koralrevssamfund, Australien. Kredit:Graham Edgar/Reef Life Survey En ny undersøgelse baseret på den første globale undersøgelse af livet i havet af dykkere har gi
Ny undersøgelse forudsiger verdensomspændende ændringer i lavvandede rev-økosystemer, når vande…Reef Life Survey-dykker vurderer koralrevssamfund, Australien. Kredit:Graham Edgar/Reef Life Survey En ny undersøgelse baseret på den første globale undersøgelse af livet i havet af dykkere har gi
- Volkswagen fortjeneste springer, men store udfordringer forude
- Video:Isolation i Antarktis
- En enkel metode udviklet til 3-D biofabrikation baseret på bakteriel cellulose
- North Louisiana Snakes, der giver levende fødsel
- Forventninger om forudsigelighed:Hvorfor folk bliver stødt
- Eksperter:Stort undervandsarkæologisk område truet i Mexico