


Big data-algoritmer kan diskriminere, og det er ikke klart, hvad man skal gøre ved det
En måde, hvorpå big data-algoritmer kan diskriminere, er ved at bruge data, der er forudindtaget i sig selv. For eksempel, hvis en algoritme er trænet på data, der er mere tilbøjelige til at omfatte oplysninger om mennesker fra bestemte racemæssige eller etniske grupper, så kan algoritmen være mere tilbøjelig til at træffe beslutninger, der favoriserer disse grupper.
En anden måde, hvorpå big data-algoritmer kan diskriminere, er ved at bruge funktioner, der er korreleret med beskyttede karakteristika. For eksempel, hvis en algoritme bruger en persons postnummer til at forudsige deres kreditværdighed, så kan algoritmen være mere tilbøjelige til at nægte kredit til folk, der bor i områder med lav indkomst, som er mere tilbøjelige til at være befolket af farvede mennesker.
Det er vigtigt at være opmærksom på potentialet for bias i big data-algoritmer, og at tage skridt til at afbøde denne bias. En måde at afbøde bias på er at bruge data, der er repræsentative for befolkningen som helhed. En anden måde at afbøde skævhed på er at bruge funktioner, der ikke er korreleret med beskyttede egenskaber.
Det er også vigtigt at være gennemsigtig omkring den måde, big data-algoritmer bruges på. Dette giver folk mulighed for at forstå, hvordan beslutninger bliver truffet, og at holde dem, der træffer beslutninger, ansvarlige.
Potentialet for bias i big data-algoritmer er et alvorligt problem, men det er et, der kan løses. Ved at tage skridt til at afbøde bias kan vi sikre, at big data-algoritmer bruges til at træffe retfærdige og retfærdige beslutninger.
Hvad skal man gøre ved bias i big data-algoritmer
Der er en række ting, der kan gøres for at imødegå bias i big data-algoritmer. Disse omfatter:
* Brug af repræsentative data: En af de vigtigste måder at reducere bias i big data-algoritmer er at bruge data, der er repræsentative for befolkningen som helhed. Det betyder, at dataene skal omfatte personer fra alle race-, etniske og kønsgrupper, såvel som personer med forskellig socioøkonomisk baggrund.
* Brug af funktioner, der ikke er korreleret med beskyttede egenskaber: En anden måde at reducere bias i big data-algoritmer er at bruge funktioner, der ikke er korreleret med beskyttede karakteristika. For eksempel, hvis en algoritme bruges til at forudsige recidiv, bør den ikke bruge funktioner som race eller køn, da disse ikke er korreleret med recidiv.
* Revision af algoritmer regelmæssigt for bias: Det er også vigtigt regelmæssigt at revidere algoritmer for bias. Dette kan gøres ved at kontrollere nøjagtigheden af algoritmen på forskellige undergrupper af befolkningen og ved at lede efter biasmønstre.
* Sikring af gennemsigtighed: Endelig er det vigtigt at sikre gennemsigtighed omkring den måde, big data-algoritmer bruges på. Dette giver folk mulighed for at forstå, hvordan beslutninger bliver truffet, og at holde dem, der træffer beslutninger, ansvarlige.
Ved at tage disse trin kan vi hjælpe med at reducere bias i big data-algoritmer og sikre, at de bruges til at træffe retfærdige og retfærdige beslutninger.
 Varme artikler
Varme artikler
-
 Forskere opdager, hvordan planter reagerer på ændringer i lys på molekylært niveauForskere ved UC Riverside har identificeret den molekylære mekanisme, hvorved fotoreceptorer kaldet phytochromes styrer planters vækst og udvikling. Resultaterne har betydning for landbruget, hvor lan
Forskere opdager, hvordan planter reagerer på ændringer i lys på molekylært niveauForskere ved UC Riverside har identificeret den molekylære mekanisme, hvorved fotoreceptorer kaldet phytochromes styrer planters vækst og udvikling. Resultaterne har betydning for landbruget, hvor lan -
 Et våbenkapløb om madspild:Sydney kakaduer åbner stadig skraldespande ved kantstenen, på trods a…Kredit:Barbara Klump, Forfatter leveret Hold da kæft! Kakaduen har lige åbnet min skraldespand, og den spiser min resterende pizza. Det kan vi ikke have, jeg sætter en sten på låget for at forhindr
Et våbenkapløb om madspild:Sydney kakaduer åbner stadig skraldespande ved kantstenen, på trods a…Kredit:Barbara Klump, Forfatter leveret Hold da kæft! Kakaduen har lige åbnet min skraldespand, og den spiser min resterende pizza. Det kan vi ikke have, jeg sætter en sten på låget for at forhindr -
 Får jackfruit til at hoppe ned fra hylderneKredit:Unsplash/CC0 Public Domain Australsk jackfruit er en tropisk skat:en frugt rig på vitaminer, mineraler og mange fytokemikalier, der er kendt for at have positive sundhedsmæssige fordele, og
Får jackfruit til at hoppe ned fra hylderneKredit:Unsplash/CC0 Public Domain Australsk jackfruit er en tropisk skat:en frugt rig på vitaminer, mineraler og mange fytokemikalier, der er kendt for at have positive sundhedsmæssige fordele, og -
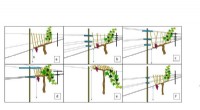 Undersøgelse viser, at cabernet-druer kan overleve klimaændringerAmy Quinton Illustrationer af de forskellige typer af vinrankespalier, der blev testet. A til C er lodrette skudpositionssystemer, der dyrkes traditionelt og ved 60 og 80 grader. D er et højfirkantet
Undersøgelse viser, at cabernet-druer kan overleve klimaændringerAmy Quinton Illustrationer af de forskellige typer af vinrankespalier, der blev testet. A til C er lodrette skudpositionssystemer, der dyrkes traditionelt og ved 60 og 80 grader. D er et højfirkantet
- Hårsensor afdækker skjulte signaler
- De 10 fod høje mikroskoper hjælper med at bekæmpe verdens værste sygdomme
- Kunstig intelligens registrerer automatisk forstyrrelser i strømforsyningsnettene
- Større er anderledes - den usædvanlige fysik af mekaniske metamaterialer udsat
- Hvad hvis mennesker kunne trække vejret under vandet?
- Glem, hvad du tror, du ved om viral marketing, undersøgelse tyder på