


Indsigtsfuld forskning belyser det nye mulige inden for naturlige og syntetiske billeder

Kredit:Microsoft
Et par banebrydende artikler inden for computervision åbner nye perspektiver på muligheder i rigerne for at skabe meget virkeligt udseende naturlige billeder og syntetisere realistiske, identitetsbevarende ansigtsbilleder. I CVAE-GAN:Finkornet billedgenerering gennem asymmetrisk træning, præsenteret i oktober sidste år på ICCV 2017 i Venedig, teamet af forskere fra Microsoft og University of Science and Technology i Kina kom med en model til billedgenerering baseret på et variationsrigt autoencoder-generativt modstandsnetværk, der er i stand til at syntetisere naturlige billeder i såkaldte finkornede kategorier. Finkornede kategorier vil omfatte ansigter af specifikke individer, sige om berømtheder, eller objekter fra den virkelige verden såsom bestemte typer blomster eller fugle.
Forskerne - Dong Chen, Fang Wen og Gang Hua fra Microsoft, Jianmin Bao, praktikant hos Microsoft Research, sammen med Houqiang Li fra Kinas Universitet for Videnskab og Teknologi – ved at se på, hvordan man bedre kunne bygge effektive generative modeller af naturlige billeder, kæmpede man med et nøgleproblem i computersyn:hvordan man genererer meget forskellige og alligevel realistiske billeder ved at variere et begrænset antal latente parametre relateret til den naturlige fordeling af ethvert billede i verden. Udfordringen lå i at komme med en generativ model til at fange disse data. De valgte en tilgang ved hjælp af generative kontradiktoriske netværk kombineret med en varierende auto-encoder for at komme med deres læringsramme. Fremgangsmåden modellerer ethvert billede som en sammensætning af etiket og latente attributter i en probabilistisk model. Ved at variere den finkornede kategorietikett (f.eks. "oriole" eller "stær" for specifikke fugletyper, eller navnene på bestemte berømtheder), der ville blive ført ind i den generative model, holdet var i stand til at syntetisere billeder i specifikke kategorier ved hjælp af tilfældigt tegnede værdier med hensyn til de latente attributter. Det er først for nylig, at denne form for dyb læring muliggør modellering af fordelingen af billeder af bestemte objekter ude i verden, giver os mulighed for at trække fra den model til grundlæggende at syntetisere billedet, forklarede Gang Hua, hovedforsker hos Microsoft Research i Redmond, Washington.
"Vores tilgang har to nye aspekter, " sagde Hua. "Først, vi vedtog et krydsentropitab for det diskriminerende og klassificerende netværk, men valgte et gennemsnitligt uoverensstemmelsesmål for det generative netværk." Den resulterende asymmetriske tabsfunktion og dens effekt på maskinlæringsaspekterne af rammeværket var opmuntrende. "Asymmetrisk tab gør faktisk uddannelsen af GAN'erne mere stabil, " sagde Hua. "Vi designede et asymmetrisk tab for at løse ustabilitetsproblemet i træning af vanilje GAN'er, der specifikt adresserer numeriske vanskeligheder ved at matche to ikke-overlappende distributioner."
Den anden nyskabelse var at vedtage et indkodernetværk, der kunne lære forholdet mellem det latente rum og bruge parvis funktionsmatchning for at bevare strukturen af de syntetiserede billeder.
Eksperimenter med naturlige billeder – ægte fotografier af virkelige ting fundet i naturen, såsom ansigter, blomster og fugle, forskerne var i stand til at vise, at deres maskinlæringsmodeller kunne syntetisere genkendelige billeder med en imponerende variation inden for meget specifikke kategorier. De potentielle applikationer dækker alt fra billedmaling, til dataforøgelse og bedre ansigtsgenkendelsesmodeller.
"Vores teknologi adresserede en grundlæggende udfordring i billedgenerering, det om kontrollerbarheden af identitetsfaktorer. Dette giver os mulighed for at generere billeder, som vi ønsker, at de skal se ud. sagde Hua."
Syntetiserer ansigter
Hvordan tager du magten til at syntetisere realistiske billeder af blomster eller fugle et skridt videre? Du ser på menneskelige ansigter. Menneskelige ansigter, når det tages i sammenhæng med identitet, er blandt de mest sofistikerede billeder, der kan tages i naturen. I Mod åben-sæt identitetsbevarende ansigtssyntese, præsenteret denne måned på CVPR 2018 i Salt Lake City, forskerne udviklede en GAN-baseret ramme, der kan adskille ansigternes identitet og egenskaber, med egenskaber, herunder sådanne iboende egenskaber som formen på næse og mund eller endda alder, samt miljømæssige faktorer, såsom belysning eller om der blev lagt makeup på ansigtet. Mens tidligere identitetsbevarende ansigtssynteseprocesser stort set var begrænset til syntetisering af ansigter med kendte identiteter, som allerede var indeholdt i træningsdatasættet, forskerne udviklede en metode til at opnå identitetsbevarende ansigtssyntese i åbne domæner – dvs. for et ansigt, der faldt uden for ethvert træningsdatasæt. At gøre dette, de landede på en unik metode til at bruge et inputbillede af et emne, der ville producere en identitetsvektor og kombinerede det med ethvert andet input -ansigtsbillede (ikke af den samme person) for at udtrække en attributvektor, såsom positur, følelser eller lys. Identitetsvektoren og attributvektoren rekombineres derefter for at syntetisere et nyt ansigt for emnet med den ekstraherede attribut. Især rammen behøver ikke at kommentere og kategorisere attributterne for nogen af ansigterne på nogen måde. Det er trænet med en asymmetrisk tabsfunktion for bedre at bevare identiteten og stabilisere maskinlæringsaspekterne. Imponerende nok, det kan også effektivt udnytte enorme mængder af umærkede trænings-ansigtsbilleder (tænk tilfældige ansigtsbilleder) for yderligere at forbedre troskaben eller nøjagtigheden af de syntetiserede ansigter.
En oplagt forbrugerapplikation er det klassiske eksempel på fotografens udfordring med at tage et gruppebillede, der inkluderer snesevis af motiver; det fælles mål er det undvigende ideelle skud, hvor alle motiver fanges med øjnene åbne og endda smilende. "Med vores teknologi, det fantastiske er, at jeg bogstaveligt talt kunne gengive et smilende ansigt for hver af deltagerne i optagelsen!" udbryder Hua. Hvad gør dette fuldstændig anderledes end ren billedredigering, siger Hua, er, at ansigtets egentlige identitet bevares. Med andre ord, selvom billedet af en smilende deltager syntetiseres - et "øjeblik", der faktisk ikke fandt sted i virkeligheden, ansigtet er umiskendeligt individets; hans eller hendes identitet er blevet bevaret i processen med at ændre billedet.
Hua ser mange nyttige applikationer, der vil gavne samfundet og ser konstante forbedringer i billedgenkendelse, videoforståelse og endda kunst.
 Varme artikler
Varme artikler
-
 Flydende vindmøller stigerKredit:CC0 Public Domain Over 26, 000 megawatt (MW) af planlagt offshore vindkapacitet findes i havvindudviklingsrørledningen. Hurtigt faldende teknologiomkostninger til havvind, herunder flydende
Flydende vindmøller stigerKredit:CC0 Public Domain Over 26, 000 megawatt (MW) af planlagt offshore vindkapacitet findes i havvindudviklingsrørledningen. Hurtigt faldende teknologiomkostninger til havvind, herunder flydende -
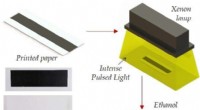 Ny aftrykningsmetode kan hjælpe med at genbruge papir og begrænse miljøomkostningerneEn ny måde at afprinte papir ved hjælp af intenst pulserende lys fra en xenonlampe. Kredit:Rajiv Malhotra/Rutgers University-New Brunswick Forestil dig, hvis din printer havde en unprint-knap, der
Ny aftrykningsmetode kan hjælpe med at genbruge papir og begrænse miljøomkostningerneEn ny måde at afprinte papir ved hjælp af intenst pulserende lys fra en xenonlampe. Kredit:Rajiv Malhotra/Rutgers University-New Brunswick Forestil dig, hvis din printer havde en unprint-knap, der -
 Apple-telefoner sælges stadig i Kina trods forbudKina er et afgørende marked for Apple, men den er blevet overhalet af kinesiske konkurrenter i de senere år Apple-butikker i Kina fortsatte med business as usual tirsdag på trods af et domstolsbeo
Apple-telefoner sælges stadig i Kina trods forbudKina er et afgørende marked for Apple, men den er blevet overhalet af kinesiske konkurrenter i de senere år Apple-butikker i Kina fortsatte med business as usual tirsdag på trods af et domstolsbeo -
 Elbilmarkedet sætter gang i koboltpriserneKoboltpriserne stiger, da investorerne satser på en enorm efterspørgsel fra bilindustrien Kobolt rammer historisk høje priser drevet af bilindustrien, som har brug for det sjældne metal til at lav
Elbilmarkedet sætter gang i koboltpriserneKoboltpriserne stiger, da investorerne satser på en enorm efterspørgsel fra bilindustrien Kobolt rammer historisk høje priser drevet af bilindustrien, som har brug for det sjældne metal til at lav
- Forskydningskraft:Hvor gode materialer bliver gjort bedre
- Hvordan man forklarer Helligånden til fem år Olds
- Ny undersøgelse tyder på, at Shroud of Turin er en falsk, støttestudie trukket tilbage
- Hvordan gennemsnitlig to procentdele
- EU's luftkvalitet forbedres langsomt, men stadig dødbringende:rapport
- Da dinosaurerne døde, det samme gjorde skove - og trælevende fugle