


AI til kode tilskynder til samarbejde, åben videnskabelig opdagelse
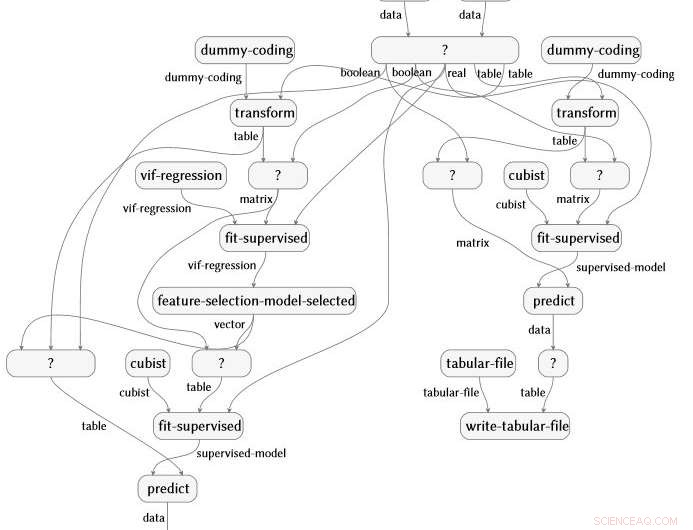
Semantisk flowgrafrepræsentation produceret automatisk ud fra en analyse af reumatoid arthritisdata. Kredit:IBM
Vi har set betydelige nylige fremskridt inden for mønsteranalyse og maskinintelligens anvendt på billeder, lyd- og videosignaler, og naturlig sprogtekst, men ikke så meget anvendt på en anden artefakt produceret af mennesker:computerprogramkildekode. I et papir, der skal præsenteres på FEED Workshop på KDD 2018, vi fremviser et system, der gør fremskridt hen imod den semantiske analyse af kode. Ved at gøre det, vi danner grundlaget for maskiner til virkelig at ræsonnere om programkode og lære af det.
Arbejdet, også for nylig demonstreret ved IJCAI 2018, er udtænkt og ledet af IBM Science for Social Good-stipendiat Evan Patterson og fokuserer specifikt på datavidenskabssoftware. Datavidenskabsprogrammer er en særlig form for computerkode, ofte ret kort, men fuld af semantisk rigt indhold, der specificerer en sekvens af datatransformation, analyse, modellering, og tolkningsoperationer. Vores teknik udfører en dataanalyse (forestil dig et R- eller Python-script) og fanger alle de funktioner, der kaldes i analysen. Det forbinder derefter disse funktioner til en datavidenskabsontologi, vi har skabt, udfører flere forenklingstrin, og producerer en semantisk flowgraf repræsentation af programmet. Som et eksempel, flowgrafen nedenfor er produceret automatisk ud fra en analyse af reumatoid arthritis data.
Teknikken er anvendelig på tværs af valg af programmeringssprog og pakke. De tre kodestykker herunder er skrevet i R, Python med NumPy- og SciPy-pakkerne, og Python med Pandas og Scikit-learn-pakkerne. Alle producerer nøjagtig den samme semantiske flowgraf.
-
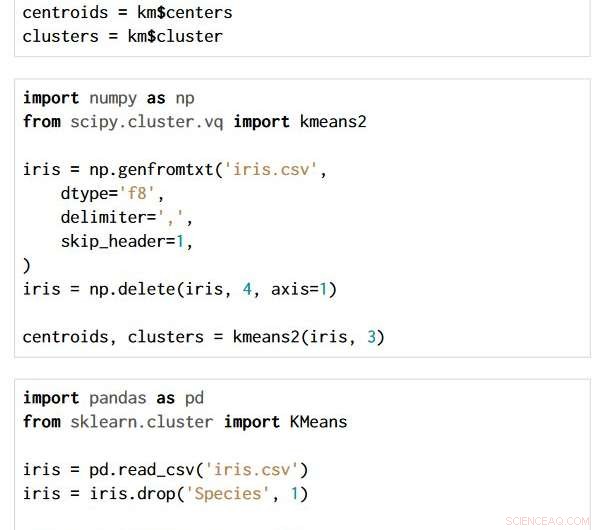
Kredit:IBM
-
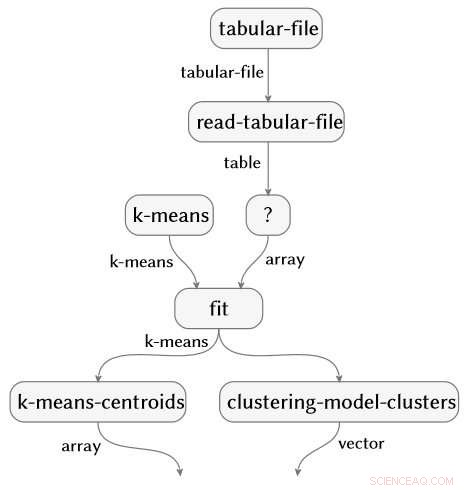
Kredit:IBM
Vi kan tænke på den semantiske flowgraf, vi udtrækker som et enkelt datapunkt, ligesom et billede eller et tekstafsnit, til at udføre yderligere opgaver på højere niveau. Med den repræsentation vi har udviklet, vi kan aktivere flere nyttige funktioner for praktiserende dataforskere, herunder intelligent søgning og autofuldførelse af analyser, anbefaling af lignende eller supplerende analyser, visualisering af rummet af alle analyser udført på et bestemt problem eller datasæt, oversættelse eller stiloverførsel, og endda maskingenerering af nye dataanalyser (dvs. beregningsmæssig kreativitet) – alt sammen baseret på den virkelig semantiske forståelse af, hvad koden gør.
Data Science Ontology er skrevet i et nyt ontologisprog, vi har udviklet, kaldet Monoidal Ontology and Computing Language (Monocl). Denne arbejdslinje blev indledt i 2016 i partnerskab med Accelerated Cure Project for Multiple Sclerosis.
Denne historie er genudgivet med tilladelse fra IBM Research. Læs den originale historie her.
Sidste artikelHvordan verden blev til i computeren
Næste artikelVideo-on-demand og myten om endeløse valgmuligheder
 Varme artikler
Varme artikler
-
 Mugshots fremkalder stemning i galleriet, druer og bægreKredit:AI Portraits Kald dem skøre, men der er et tværsnit af menneskelivet, der ikke ønsker at dukke op i sociale chatgrupper, der ligner søde søde med røde kaninnæser eller kaninører. Synes godt
Mugshots fremkalder stemning i galleriet, druer og bægreKredit:AI Portraits Kald dem skøre, men der er et tværsnit af menneskelivet, der ikke ønsker at dukke op i sociale chatgrupper, der ligner søde søde med røde kaninnæser eller kaninører. Synes godt -
 NYC -drivere til Uber, andre apps for at få dækning af synsplejeI denne 15. marts, 2017, fil foto, en Uber-bil kører gennem LaGuardia Lufthavn i New York. Fra søndag d. 1. juli kl. 2018, chauffører til biltjenester og ride-hailing apps som Uber og Lyft i New York
NYC -drivere til Uber, andre apps for at få dækning af synsplejeI denne 15. marts, 2017, fil foto, en Uber-bil kører gennem LaGuardia Lufthavn i New York. Fra søndag d. 1. juli kl. 2018, chauffører til biltjenester og ride-hailing apps som Uber og Lyft i New York -
 Air Force certificerer de første 3-D-printede ikke-strukturelle flydeleEn flydel udskrives på Stratasys F900 tredimensionelle printer 15. august, 2019, ved Travis Air Force Base, Californien. Travis AFB er den første feltenhedsplacering i luftvåbnet, der har Stratays F90
Air Force certificerer de første 3-D-printede ikke-strukturelle flydeleEn flydel udskrives på Stratasys F900 tredimensionelle printer 15. august, 2019, ved Travis Air Force Base, Californien. Travis AFB er den første feltenhedsplacering i luftvåbnet, der har Stratays F90 -
 Hvorfor bruger folk stadig faxmaskiner?Gammel teknologi, men ikke forældet. Kredit:suksawad/Shutterstock.com Faxmaskinen er et symbol på forældet teknologi, der længe er afløst af computernetværk - men fax er faktisk stigende i popular
Hvorfor bruger folk stadig faxmaskiner?Gammel teknologi, men ikke forældet. Kredit:suksawad/Shutterstock.com Faxmaskinen er et symbol på forældet teknologi, der længe er afløst af computernetværk - men fax er faktisk stigende i popular
- Forskere opdager verdens mindste superleder
- Hvordan gør Blue Jays Mate?
- Brug af vandmolekyler til at aflæse elektrisk aktivitet i lipidmembraner
- Relikvier fra Shakespeares hjem deles i ny virtuel udstilling
- Forskning afslører chokerende svaghed ved laboratoriekurser
- Forskere er pionerer i mikrofluidik-aktiveret fremstilling af makroskopiske grafenfibre