


En ny metode til at indgyde nysgerrighed hos forstærkende læringsagenter
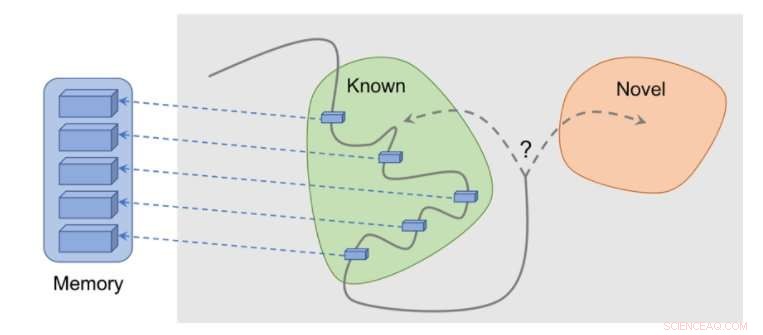
Sådan fungerer metoden:observationer føjes til hukommelsen, belønning beregnes ud fra, hvor langt vores aktuelle observation er fra den mest lignende observation i hukommelsen. Agenten modtager mere belønning for at se observationer, som endnu ikke er repræsenteret i hukommelsen. Kredit:Savinov et al.
Adskillige opgaver i den virkelige verden har sparsomme belønninger, og dette giver udfordringer for udviklingen af forstærkende læring (RL) algoritmer. En løsning på dette problem er at give en agent mulighed for selvstændigt at skabe en belønning til sig selv, gør belønninger tættere og mere egnede til læring.
For eksempel, inspireret af den nysgerrige adfærd, hvormed dyr udforsker deres miljø, en RL-algoritmes observation af noget nyt kunne belønnes med en bonus. Denne bonus, opsummeret med den rigtige opgavebelønning, ville så tillade RL-algoritmer at lære af en kombineret belønning.
Forskere ved DeepMind, Google Brain og ETH Zurich har for nylig udtænkt en ny nysgerrighedsmetode, der bruger episodisk hukommelse til at danne denne nyhedsbonus. Denne bonus bestemmes ved at sammenligne aktuelle observationer og observationer gemt i hukommelsen.
"Hovedformålet med vores arbejde var at undersøge nye hukommelsesbaserede måder at tilføre agenter for forstærkningslæring (RL) 'nysgerrighed,' ' hvormed vi mener en drivkraft til at udforske miljøet selv i fuldstændig fravær af belønninger, Tim Lillicrap hos DeepMind og Nikolay Savinov hos Google Brain fortalte TechXplore i en e-mail. men vi følte, at flere ideer kunne drage fordel af yderligere udforskning."
Nøgleideerne, der er udforsket i dette nye papir, er baseret på en tidligere undersøgelse udført af Savinov, som foreslog en ny hukommelsesarkitektur inspireret af pattedyrnavigation. Denne arkitektur gør det muligt for agenter at gentage en rute gennem et miljø ved kun at bruge en visuel gennemgang. Den nye metode udviklet af forskerne tager dette et skridt videre, forsøger at opnå god udforskning drevet af nysgerrighed.
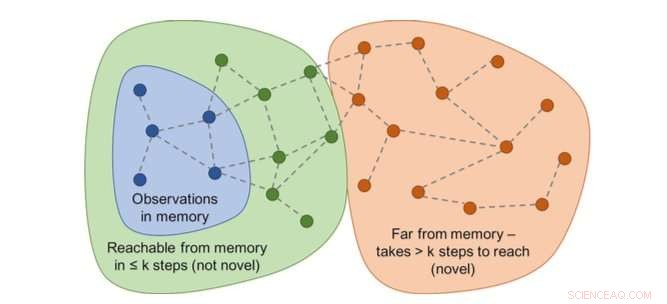
Graf over tilgængelighed vil bestemme nyheden. I praksis, denne graf er ikke tilgængelig - så en neural netværkstilnærmer er trænet til at estimere et antal trin mellem observationerne. Kredit:Savinov et al.
"Mens man handler, agenten gemmer forekomster af observationsrepræsentationer i sin episodiske hukommelse, " sagde Lillicrap og Savinov. "For at afgøre, om den aktuelle observation er ny eller ej, det sammenlignes med dem i hukommelsen. Hvis der ikke findes noget lignende, den aktuelle observation anses for at være ny, og agenten belønnes, ellers får den en negativ belønning. Dette tilskynder agenten til at udforske ukendt territorium, som at være nysgerrig."
Forskerne fandt ud af, at det kunne være vanskeligt at sammenligne par af observationer, da det i sidste ende er meningsløst at tjekke for et nøjagtigt match i realistiske miljøer. Dette skyldes, at i situationer i den virkelige verden, en agent observerer sjældent det samme to gange.
"I stedet, vi trænede et neuralt netværk til at forudsige, om agenten kan nå den aktuelle observation fra dem i hukommelsen ved at foretage færre handlinger end en fast tærskel; sige, fem handlinger, Lillicrap og Savinov forklarede. "Observationer inden for disse fem handlinger betragtes som ens, mens de, der kræver flere handlinger for at foretage en overgang, anses for at være forskellige."
Lillicrap, Savinov og deres kolleger testede deres tilgang i VizDoom og DMLab, to visuelt rige 3D-miljøer. I VizDoom, agenten lærte at navigere til et fjernt mål mindst to gange hurtigere end den nyeste nysgerrighedsmetode ICM. I DMLab, algoritmen generaliseret godt til ny, proceduremæssigt genererede niveauer af spillet, at nå sit ønskede mål mindst to gange hyppigere end ICM på testlabyrinter med meget sparsomme belønninger.

En overraskelsesbaseret metode (ICM) er vedholdende at mærke vægge med en laserlignende science fiction-gadget i stedet for at udforske labyrinten. Denne adfærd ligner kanalskiftet beskrevet før:selvom resultatet af tagging er teoretisk forudsigeligt, det er ikke let og kræver tilsyneladende et dybt kendskab til fysik, som ikke er ligetil at erhverve for en generel agent. Kredit:Savinov et al.
"Vi bemærkede en interessant ulempe ved en af de mest populære metoder til at præge agenter med nysgerrighed, " sagde Lillicrap og Savinov. "Vi fandt ud af, at denne metode, baseret på overraskelsen, der er beregnet af en langsomt skiftende model, der forsøger at forudsige, hvad der vil ske næste gang, kan resultere i et øjeblikkeligt tilfredsstillelsessvar fra agenten:i stedet for at løse den aktuelle opgave, det vil udnytte handlinger, der fører til uforudsigelige konsekvenser for at få øjeblikkelig belønning."
Denne ejendommelige begivenhed, også kendt som "sofa-kartoffel"-problemer, indebærer, at en agent finder måder til øjeblikkeligt at tilfredsstille sig selv ved at udnytte handlinger, der fører til uforudsigelige konsekvenser. For eksempel, når du får en fjernbetjening til tv, agenten gør måske ikke andet end at skifte kanal, selvom dens oprindelige opgave var helt anderledes, såsom at søge efter et mål i en labyrint.
"Denne mangel kan afhjælpes ved hjælp af episodisk hukommelse sammen med et rimeligt mål for observationslighed, som er vores bidrag, " sagde Lillicrap og Savinov. "Dette åbner en vej til mere intelligent udforskning."

Vores metode viser en fornuftig udforskning. Kredit:Savinov et al.
Den nye nysgerrighedsmetode udviklet af Lillicrap, Savinov, og deres kolleger kunne hjælpe med at kopiere nysgerrighed-lignende færdigheder i RL-algoritmer, giver dem mulighed for selvstændigt at skabe belønninger til sig selv. I fremtiden, forskerne vil gerne bruge episodisk hukommelse ikke kun til at give belønninger, men også til planlægning af handlinger.
"For eksempel, kan indhold hentet fra hukommelsen bruges til at tænke over, hvor de skal hen?" sagde Lillicrap og Savinov. "Dette er i øjeblikket en stor videnskabelig udfordring:hvis det løses, agenter ville være i stand til hurtigt at tilpasse udforskningsstrategier til nye miljøer, lader læring ske i et meget hurtigere tempo."
© 2018 Tech Xplore
 Varme artikler
Varme artikler
-
 For at stoppe falske nyheder, forskere opfordrer internetplatforme til at vælge kvalitet frem for k…Kredit:Northeastern University Falske nyheder har skabt overskrifter og domineret snak på sociale medier siden præsidentvalget i 2016. Det ser ud til at være overalt, og forskere er stadig ved at
For at stoppe falske nyheder, forskere opfordrer internetplatforme til at vælge kvalitet frem for k…Kredit:Northeastern University Falske nyheder har skabt overskrifter og domineret snak på sociale medier siden præsidentvalget i 2016. Det ser ud til at være overalt, og forskere er stadig ved at -
 Kort Facebook -afbrydelse efter netværksproblemerKredit:CC0 Public Domain Facebook -brugere rundt om i verden rapporterede, at det sociale netværk kortvarigt var utilgængeligt mandag, hvor mange tager til Twitter for at give udtryk for deres frus
Kort Facebook -afbrydelse efter netværksproblemerKredit:CC0 Public Domain Facebook -brugere rundt om i verden rapporterede, at det sociale netværk kortvarigt var utilgængeligt mandag, hvor mange tager til Twitter for at give udtryk for deres frus -
 Projektet vil udforske spilpotentialet for at reducere mental nødDen retfærdige overgivelseslinje i den uendelige debat om videospil som dårlige eller gode for mennesker er den linje, hvor folk er enige om at være uenige, hvor folk undersøger alle undersøgelser for
Projektet vil udforske spilpotentialet for at reducere mental nødDen retfærdige overgivelseslinje i den uendelige debat om videospil som dårlige eller gode for mennesker er den linje, hvor folk er enige om at være uenige, hvor folk undersøger alle undersøgelser for -
 Kampen mod desinformation er globalKredit:CC0 Public Domain Desinformation-udspyende online-bots og -trolde fra halvvejs rundt om i verden fortsætter med at forme lokale og nationale debatter ved at sprede løgne online i massiv ska
Kampen mod desinformation er globalKredit:CC0 Public Domain Desinformation-udspyende online-bots og -trolde fra halvvejs rundt om i verden fortsætter med at forme lokale og nationale debatter ved at sprede løgne online i massiv ska
- Undersøgelse viser, at flere aktive politibetjente døde af COVID-19 i 2020 end alle andre årsager…
- NASA holder øje med tyfonen Noru
- Tecumseh Carburetor Identification
- Ny økonomisk model kan forhindre problemer med kapitalstrømmen
- Forskere går ind for lighed i STEM-adgang
- Tværbundne hultransportlag til højeffektive perovskit tandem solceller