


Nyt AI-system efterligner, hvordan mennesker visualiserer og identificerer objekter

Et "computersyn" -system udviklet på UCLA kan identificere objekter baseret på kun delvise glimt, som ved at bruge disse fotofremvisninger af en motorcykel. Kredit:University of California, Los Angeles
Ingeniører fra UCLA og Stanford University har demonstreret et computersystem, der kan opdage og identificere de objekter i den virkelige verden, det "ser", baseret på den samme metode til visuel læring, som mennesker bruger.
Systemet er et fremskridt inden for en type teknologi kaldet "computersyn, " som gør det muligt for computere at læse og identificere visuelle billeder. Det kunne være et vigtigt skridt hen imod generelle kunstig intelligens-systemer - computere, der lærer på egen hånd, er intuitive, tage beslutninger baseret på ræsonnementer og interagere med mennesker på en meget mere menneskelignende måde. Selvom de nuværende AI -computersyn systemer bliver stadig mere kraftfulde og i stand, de er opgavespecifikke, hvilket betyder, at deres evne til at identificere, hvad de ser, er begrænset af, hvor meget de er blevet trænet og programmeret af mennesker.
Selv nutidens bedste computervisionssystemer kan ikke skabe et fuldstændigt billede af et objekt efter kun at have set visse dele af det - og systemerne kan narre ved at se objektet i ukendte omgivelser. Ingeniører sigter efter at lave computersystemer med disse evner – ligesom mennesker kan forstå, at de ser på en hund, også selvom dyret gemmer sig bag en stol og kun poter og hale er synlige. mennesker, selvfølgelig, kan også let intuitere, hvor hundens hoved og resten af kroppen er, men den evne undgår stadig de fleste kunstige intelligenssystemer.
Nuværende computersynssystemer er ikke designet til at lære på egen hånd. De skal trænes i præcis, hvad de skal lære, normalt ved at gennemgå tusindvis af billeder, hvor de objekter, de forsøger at identificere, er mærket til dem. computere, selvfølgelig, kan heller ikke forklare deres begrundelse for at bestemme, hvad objektet på et foto repræsenterer:AI-baserede systemer bygger ikke et internt billede eller en sund fornuftsmodel af lærde objekter, som mennesker gør.
Ingeniørernes nye metode, beskrevet i Proceedings of the National Academy of Sciences , viser en vej rundt om disse mangler.
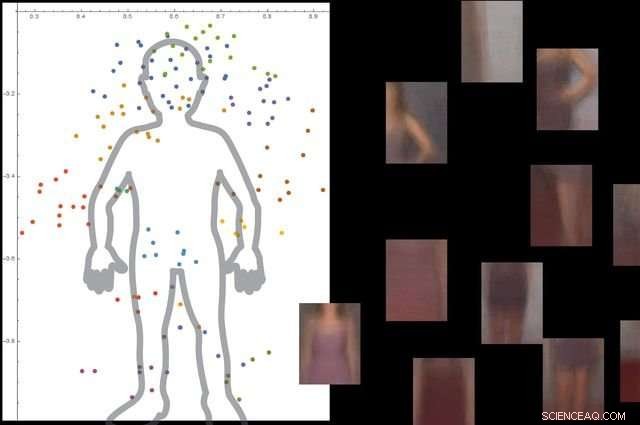
Systemet forstår, hvad en menneskelig krop er ved at se på tusindvis af billeder med mennesker i dem, og derefter ignorere ikke -væsentlige baggrundsobjekter. Kredit:University of California, Los Angeles
Tilgangen består af tre brede trin. Først, systemet opdeler et billede i små bidder, som forskerne kalder "viewlets". Sekund, computeren lærer, hvordan disse viewlets passer sammen for at danne det pågældende objekt. Og endelig, den ser på, hvilke andre objekter der er i det omkringliggende område, og hvorvidt oplysninger om disse objekter er relevante for at beskrive og identificere det primære objekt.
For at hjælpe det nye system med at "lære" mere ligesom mennesker, ingeniørerne besluttede at fordybe den i en internetkopi af det miljø, mennesker lever i.
"Heldigvis, Internettet giver to ting, der hjælper et hjerne-inspireret computersynssystem med at lære på samme måde, som mennesker gør, " sagde Vwani Roychowdhury, en UCLA-professor i elektro- og computerteknik og undersøgelsens hovedefterforsker. "Det ene er et væld af billeder og videoer, der skildrer de samme typer objekter. Det andet er, at disse objekter vises fra mange perspektiver - sløret, fugleperspektiv, tæt på-og de er placeret i alle forskellige slags miljøer. "
For at udvikle rammerne, forskerne hentede indsigt fra kognitiv psykologi og neurovidenskab.
"Startende som spædbørn, vi lærer, hvad noget er, fordi vi ser mange eksempler på det, i mange sammenhænge, " sagde Roychowdhury. "At kontekstuel læring er en nøglefunktion i vores hjerner, og det hjælper os med at bygge robuste modeller af objekter, der er en del af et integreret verdensbillede, hvor alt er funktionelt forbundet. "
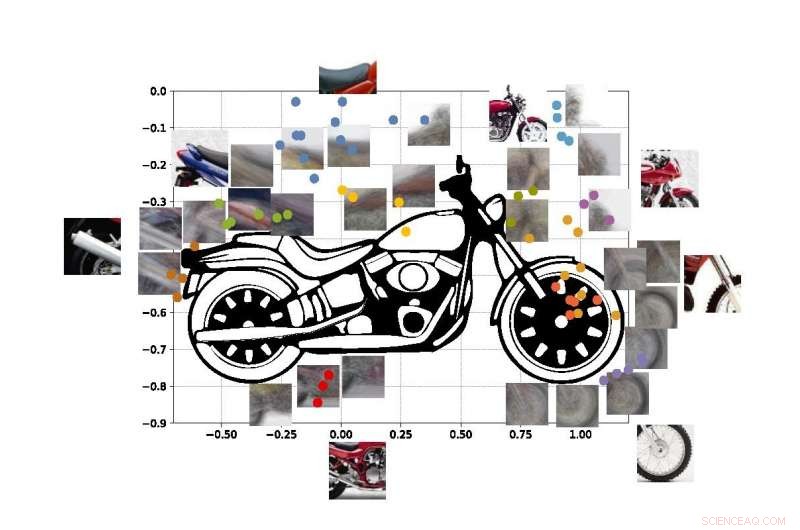
De farvede prikker i figuren viser estimerede koordinater for centrene for nogle af udsigterne i vores motorcykel SUVM. Hver viewlet -repræsentation er en sammensætning af eksempelvisninger/patches, der har lignende udseende. Kredit:Lichao Chen, Tianyi Wang, og Vwani Roychowdhury (University of California, Los Angeles).
Forskerne testede systemet med omkring 9, 000 billeder, hver viser mennesker og andre genstande. Platformen var i stand til at bygge en detaljeret model af den menneskelige krop uden ekstern vejledning og uden at billederne blev mærket.
Ingeniørerne kørte lignende tests ved hjælp af billeder af motorcykler, biler og fly. I alle tilfælde, deres system klarede sig bedre eller mindst lige så godt som traditionelle computervisionssystemer, der er udviklet med mange års træning.
Studiets co-senior forfatter er Thomas Kailath, en professor emeritus i elektroteknik ved Stanford, som var Roychowdhurys doktorgradsrådgiver i 1980'erne. Andre forfattere er tidligere UCLA -doktorander Lichao Chen (nu forskningsingeniør hos Google) og Sudhir Singh (der grundlagde en virksomhed, der bygger robotundervisningskammerater til børn).
Singh, Roychowdhury og Kailath arbejdede tidligere sammen om at udvikle en af de første automatiserede visuelle søgemaskiner til mode, det nu lukkede StileEye, hvilket gav anledning til nogle af grundtankerne bag den nye forskning.
 Varme artikler
Varme artikler
-
 Detroit show har SUV'er, hestekræfter, men elbiler er fåI denne 14. januar, 2018, filfoto Fords præsident og administrerende direktør Jim Hackett forbereder sig på at tale til medierne på den nordamerikanske internationale biludstilling i Detroit. En ny ve
Detroit show har SUV'er, hestekræfter, men elbiler er fåI denne 14. januar, 2018, filfoto Fords præsident og administrerende direktør Jim Hackett forbereder sig på at tale til medierne på den nordamerikanske internationale biludstilling i Detroit. En ny ve -
 Sammenlægning af antenne og elektronik øger energi- og spektrumeffektivitetenGeorgia Tech-forskere er vist med elektronikudstyr og antenneopsætning, der bruges til at måle fjernfeltudstrålet udgangssignal fra millimeterbølgesendere. Vist er kandidatforsker Huy Thong Nguyen, Ud
Sammenlægning af antenne og elektronik øger energi- og spektrumeffektivitetenGeorgia Tech-forskere er vist med elektronikudstyr og antenneopsætning, der bruges til at måle fjernfeltudstrålet udgangssignal fra millimeterbølgesendere. Vist er kandidatforsker Huy Thong Nguyen, Ud -
 Snapchat er her for dig med en ny funktion til mental sundhedKredit:CC0 Public Domain I en tid, hvor cybermobning og usunde beskeder florerer på nettet, sociale netværkssider kæmper med, hvordan man adresserer det. Den seneste sociale app til at hjælpe bru
Snapchat er her for dig med en ny funktion til mental sundhedKredit:CC0 Public Domain I en tid, hvor cybermobning og usunde beskeder florerer på nettet, sociale netværkssider kæmper med, hvordan man adresserer det. Den seneste sociale app til at hjælpe bru -
 Oppustelige rumrobotter med integrerede dielektriske elastomertransducere (DET'er)Kredit:Ashby et al. Forskere ved Auckland Bioengineering Institute og Technische Universität Dresden har for nylig designet en ny type oppustelig robot til rumnavigation. Disse robotter, præsenter
Oppustelige rumrobotter med integrerede dielektriske elastomertransducere (DET'er)Kredit:Ashby et al. Forskere ved Auckland Bioengineering Institute og Technische Universität Dresden har for nylig designet en ny type oppustelig robot til rumnavigation. Disse robotter, præsenter
- Billede:Hubble ser en stjerneovn
- Ny tilgang kan øge litiumbatteriers energikapacitet
- Ingen kunst eller træpaneler – nogle advokatfirmaer arbejder i skyen
- Sporing af tropernes bevægelse 800 år tilbage i fortiden
- Meteoritter afslører magnetisk registrering af protoplanet-krumning
- De fire kræfter, der påvirker vindhastighed og vindretning