


At spille videospil kan hjælpe forskere med at finde personlig medicinsk behandling for sepsis

En agent-baseret model af medfødt immunrespons simulerer mekanisk sepsis i 2-D. Kredit:Lawrence Livermore National Laboratory
En dyb læringstilgang, der oprindeligt var designet til at lære computere at spille videospil bedre end mennesker, kunne hjælpe med at udvikle personlig medicinsk behandling for sepsis, en sygdom, der forårsager omkring 300, 000 dødsfald om året, og som der ikke er nogen kendt kur mod.
Lawrence Livermore National Laboratory (LLNL), i samarbejde med forskere ved University of Vermont, undersøger, hvordan dyb forstærkningslæring kan opdage terapeutiske lægemiddelstrategier for sepsis ved at bruge en simulering af en patients medfødte immunsystem som en platform for virtuelle eksperimenter. Deep reinforcement learning er en state-of-the-art maskinlæringstilgang, der oprindeligt blev udviklet af Google DeepMind for at lære et neuralt netværk at spille videospil, kun givet pixels som input og spillets score som et læringssignal. Algoritmerne overstiger ofte menneskelig præstation, på trods af ikke at blive givet nogen viden om spillets mekanik.
LLNLs dybe læringstilgang behandler immunsystemets simulering udviklet af deres samarbejdspartnere som et videospil. Ved at bruge output fra simuleringen, en "score" baseret på patientens helbred og en optimeringsalgoritme, det neurale netværk lærer, hvordan man manipulerer 12 forskellige cytokinmediatorer – immunsystemregulatorer – for at drive immunresponset på infektion tilbage til normale niveauer. Forskningen vises i et papir udgivet af International Conference on Machine Learning.
"Det er et komplekst system, " sagde LLNL-forsker Dan Faissol, hovedefterforsker af projektet. "Tidligere undersøgelser har hidtil været baseret på at manipulere en enkelt mediator/cytokin, generelt indgivet med enten en enkelt dosis eller over et meget kort forløb. Vi mener, at vores tilgang har et stort potentiale, fordi den udforsker meget mere kompleks, out-of-the-box terapeutiske strategier, der behandler hver patient forskelligt baseret på patientens målinger over tid."
Den behandlingsstrategi, som forskerne foreslår, er adaptiv og personlig, forbedre sig selv på en feedback-loop ved løbende at observere cytokinniveauer og ordinere lægemidler, der er specifikke for den enkelte patient. Hver kørsel af simuleringen repræsenterer en anden patienttype og forskellige initiale infektionsbetingelser.
"Udfordringen var at holde tingene klinisk relevante, " forklarede LLNL-forsker Brenden Petersen, den tekniske leder for projektet. "Vi var nødt til at sikre, at alle aspekter af det simulerede problem var relevante i den virkelige verden - at computeren ikke brugte nogen information, der ikke ville være tilgængelig på et hospital. Så, vi forsynede kun det neurale netværk med information, der rent faktisk kan måles klinisk, som cytokinniveauer og celletal fra en blodprøve."
Ved at bruge den agentbaserede model med dyb forstærkende læring, forskere identificerede en behandlingspolitik, der opnår en 100 procents overlevelsesrate for de patienter, som den blev trænet i, og en dødelighed på mindre end 1 procent på 500 tilfældigt udvalgte patienter.
"Simuleringen er mekanistisk af natur, hvilket betyder, at vi praktisk talt kan eksperimentere med lægemidler og lægemiddelkombinationer, der ikke er blevet testet før, for at se, om de kan være lovende, " sagde Faissol. "Antallet af mulige behandlingsstrategier er enormt, især når man overvejer multi-drug strategier, der varierer over tid. Uden at bruge simulering, der er ingen måde at evaluere dem alle på. Det svære er at finde en strategi, der virker for alle patienttyper. Alles infektion er forskellig, og alles krop er forskellig."
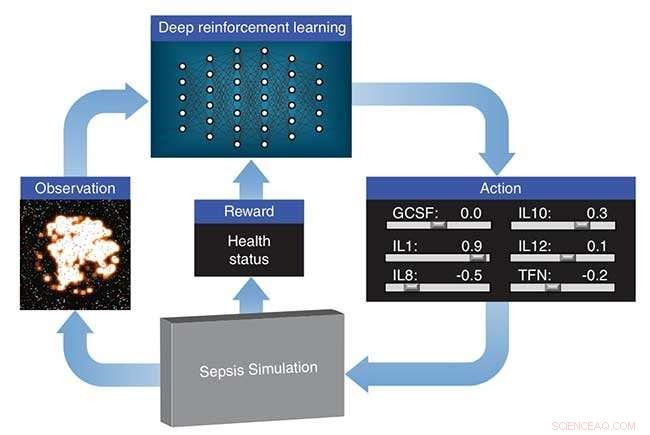
LLNLs dybe læringstilgang behandler immunsystemets simulering udviklet af deres samarbejdspartnere som et videospil. Ved at bruge output fra simuleringen, en "score" baseret på patientens helbred og en optimeringsalgoritme, det neurale netværk lærer, hvordan man manipulerer 12 forskellige cytokinmediatorer - immunsystemregulatorer - for at drive immunresponset på infektion tilbage til normale niveauer. Kredit:Lawrence Livermore National Laboratory
Holdets forskning har vist, at denne adaptive tilgang kan føre til ny indsigt, og forskerne håber at overbevise andre om at tage tilgangen til sepsis og andre sygdomme.
"Vores store, langsigtet syn er et 'lukket sløjfe' sengesystem, hvor målinger fra en patient føres ind i et beslutningsstøtteværktøj, som derefter administrerer de korrekte lægemidler i de rigtige doser på de rigtige tidspunkter, " sagde Petersen. "Sådanne behandlingsstrategier skal først undersøges og finjusteres i våde laboratorie- og dyremodeller, til sidst informerer reelle behandlinger."
Petersen sagde, at det meste af hardwaren til at udføre et sådant lukket kredsløb allerede eksisterer, som med enklere systemer som insulinpumper, der konstant overvåger blodet og administrerer insulin på det rigtige tidspunkt.
Laboratoriets dybe forstærkende læringstilgang er endnu ikke testet i den virkelige verden, men baseret på succesen ved at bruge simuleringen, National Institutes of Health tildelte forskere fra LLNL og University of Vermont en femårig bevilling til at fortsætte arbejdet, primært på sepsis men også på cancer.
"Dette er et spændende projekt, " sagde Gary An, en kritisk plejelæge ved University of Vermont og beregningsforsker, der udviklede den originale version af sepsis-simuleringen. "Dette er et utroligt nyt projekt, der samler tre banebrydende områder inden for beregningsforskning:højopløsnings multi-skala simuleringer af biologiske processer, udvidelse af dyb forstærkende læring til biomedicinsk forskning og brugen af højtydende computing for at bringe det hele sammen."
LLNLs direktør for Bioengineering Shankar Sundaram beskrev tilgangen som "et illustrativt eksempel på laboratoriet, der bidrager til udviklingen af en potentiel terapeutisk løsning på et komplekst sundhedsproblem, der er afgørende for vores biosikkerhedsmission, at anvende og fremme vores avancerede evner inden for videnskabelig maskinlæring og målrette mod forbedrede årsagssammenhænge, mekanistisk forståelse."
LLNL-forskere har også indledt et samarbejde med Moffitt Cancer Center i Florida for at se, om en lignende tilgang kunne lære effektive lægemiddelterapistrategier ved hjælp af en simulering af kræft. Moffitt udgav en videospilversion af deres simulering kaldet "Cancer Crusade", der kører på mobiltelefoner.
"En strategi er at crowdsource læringen ved at analysere behandlinger optaget fra topscorende spillere rundt om i verden, " Petersen said. "We applied our deep learning approach and want to see how our computed treatments stack up against the top players—a 'man vs. machine' showdown."
The sepsis project also has led to a new effort at LLNL researching adaptive and autonomous cyberdefense strategies using simulation and deep reinforcement learning.
Sidste artikelLokal embedsmand sagsøger Facebook for misbrug af data
Næste artikelElon Musk borer en tunnel for at revolutionere bykørsel
 Varme artikler
Varme artikler
-
 Bag MAX -krisen:Lax -regulator, top-down virksomhedskulturBoeing-embedsmænd erfarede, at anti-stall-systemet i midten af to større nedbrud oplevede problemer under flyvetests Selv før Lion Air og Ethiopian Airlines styrtede ned krævede 346 liv, Boeing
Bag MAX -krisen:Lax -regulator, top-down virksomhedskulturBoeing-embedsmænd erfarede, at anti-stall-systemet i midten af to større nedbrud oplevede problemer under flyvetests Selv før Lion Air og Ethiopian Airlines styrtede ned krævede 346 liv, Boeing -
 Hadhændelser er notorisk underrapporteret; nu, der er en app til detDen første af sin slags, appen giver ofre mulighed for at rapportere hadhændelser ud over dem, der er fanget af politiet. Kredit:Hate Incident Reporting System Group Federal Bureau of Investigatio
Hadhændelser er notorisk underrapporteret; nu, der er en app til detDen første af sin slags, appen giver ofre mulighed for at rapportere hadhændelser ud over dem, der er fanget af politiet. Kredit:Hate Incident Reporting System Group Federal Bureau of Investigatio -
 USGS og DOE frigiver landsdækkende kort over vindmøller og databaseUS Wind Turbine Database viewer, der indeholder oplysninger om mere end 57, 000 individuelle vindmøller på tværs af 43 stater, Puerto Rico, og Guam. Kredit:USGS I dag, U.S. Geological Survey (USGS
USGS og DOE frigiver landsdækkende kort over vindmøller og databaseUS Wind Turbine Database viewer, der indeholder oplysninger om mere end 57, 000 individuelle vindmøller på tværs af 43 stater, Puerto Rico, og Guam. Kredit:USGS I dag, U.S. Geological Survey (USGS -
 Algoritmer hjælper med at finde minimale energibaner og sadelpunkter mere effektivtKredit:J. Chem. Fys. 147, 152720 (2017), AIP Publishing Olli-Pekka Koistinen, doktorand ved Aalto University, udviklet maskinlæringsalgoritmer baseret på gaussisk procesregression for at forbedre
Algoritmer hjælper med at finde minimale energibaner og sadelpunkter mere effektivtKredit:J. Chem. Fys. 147, 152720 (2017), AIP Publishing Olli-Pekka Koistinen, doktorand ved Aalto University, udviklet maskinlæringsalgoritmer baseret på gaussisk procesregression for at forbedre
- Udseende, sociale normer holder eleverne væk fra Zoom-kameraer
- Diffusion: Hvad er det? & Hvordan sker det?
- Forsker dokumenterer nøjagtige placeringer, gange af Ansel Adams Alaska billeder
- Sådan integreres firkantede rodfunktioner
- Teknik fordobler omdannelse af CO2 til plastkomponent
- Små landbrug producerer mere mad end statistik viser