


Et netværk med to visninger til at forudsige dybde og ego-bevægelse fra monokulære sekvenser
Kredit:Prasad, Das &Bhowmick.
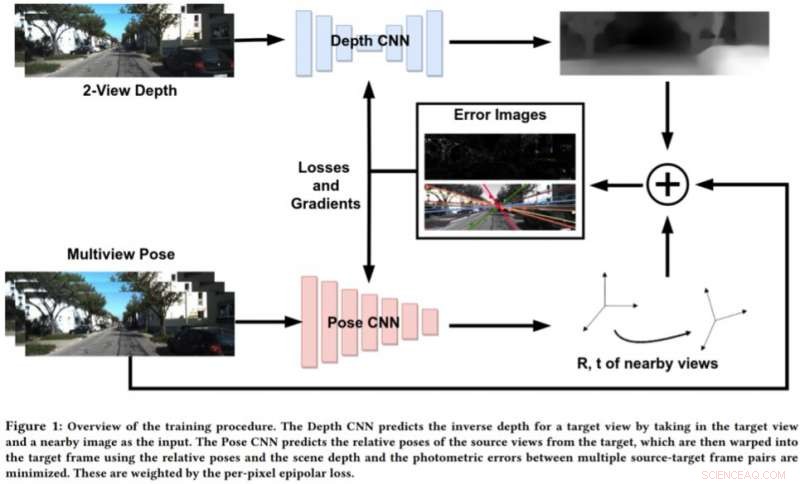
Forskere fra Embedded Systems and Robotics-gruppen hos TCS Research &Innovation har for nylig udviklet et to-view-dybdenetværk for at udlede dybde og ego-bevægelse fra på hinanden følgende monokulære sekvenser. Deres tilgang, præsenteret i et papir, der er forududgivet på arXiv, inkorporerer også epipolære begrænsninger, som forbedrer netværkets geometriske forståelse.
"Vores hovedidé var at forsøge at forudsige pixelmæssig dybde og kamerabevægelse direkte fra enkelte billedsekvenser, "Dr. Brojeshwar Bhowmick, en af de forskere, der har udført undersøgelsen, fortalte TechXplore. "Traditionelt struktur fra bevægelsesbaserede rekonstruktionsalgoritmer giver sparsomme dybdeoutput for fremtrædende interessepunkter i billedet, som spores over flere billeder ved hjælp af multi-view geometri. Da dyb læring vinder popularitet inden for computer vision -opgaver, vi tænkte på at udnytte eksisterende metoder til at hjælpe vores sag ved at nærme os problemet på en mere fundamental måde ved at bruge en kombination af begreber fra epipolær geometri og dyb læring."
De fleste eksisterende deep learning-tilgange til at forudsige monokulær dybde og ego-bevægelse optimerer den fotometriske konsistens i billedsekvenser ved at fordreje en visning til en anden. Ved at udlede dybde fra en enkelt visning, imidlertid, disse metoder kan muligvis ikke fange forholdet mellem pixels og dermed give korrekte pixel-korrespondancer.
For at imødegå begrænsningerne ved disse tilgange, Bhowmick og hans kolleger udviklede en ny tilgang, der kombinerer geometrisk computersyn og dybe indlæringsparadigmer. Deres tilgang bruger to neurale netværk, en til at forudsige dybden af en enkelt referencevisning og en til at forudsige de relative stillinger af et sæt af visninger i forhold til referencevisningen.

Kredit:Prasad, Das &Bhowmick.
"Målbilledscenen kan rekonstrueres fra enhver af de givne positurer ved at fordreje dem baseret på dybden og relative positurer, " Bhowmick forklarede. "I betragtning af dette rekonstruerede billede og referencebilledet, vi beregner fejlen i pixelintensiteterne, som fungerer som vores største tab. Vi tilføjer nyheden ved at bruge det per-pixel epipolære tab, et koncept fra multi-view geometri, i det samlede tab, som sikrer bedre korrespondancer og har den ekstra fordel at rabatter på bevægelige objekter i scenen, der ellers kan forringe læringen. "
I stedet for at forudsige dybde ved at analysere et enkelt billede, denne nye tilgang fungerer ved at analysere et par billeder fra en video og lære inter-pixel relationer for at forudsige dybde. Det minder lidt om traditionelle SLAM/SfM-algoritmer, som kan observere pixelbevægelser over tid.
"De mest meningsfulde resultater af vores undersøgelse er, at brug af to visninger til at forudsige dybden fungerer bedre end et enkelt billede, og at selv svag håndhævelse af pixelniveaukorrespondancer via epipolære begrænsninger fungerer fint, " Bhowmick sagde. "Når sådanne metoder modnes og forbedres i generaliserbarhed, vi kunne anvende dem til perception på droner, hvor man ønsker at udtrække maksimal sensorisk information ved at forbruge så lidt strøm som muligt, hvilket kan opnås ved at bruge et enkelt kamera."
I foreløbige evalueringer, forskerne fandt ud af, at deres metode kunne forudsige dybde med højere nøjagtighed end eksisterende tilgange, producere skarpere dybdeestimater og forbedrede poseestimater. Imidlertid, i øjeblikket, deres tilgang kan kun udføre slutninger på pixelniveau. Fremtidigt arbejde kunne løse denne begrænsning ved at integrere scenens semantik i modellen, hvilket kan føre til bedre korrelationer mellem objekter i scenen og både dybde- og ego-motion estimater.
"Vi undersøger yderligere i generaliserbarheden af denne metode og andre lignende metoder på forskellige scener, både indendørs og udendørs, " sagde Bhowmick. "I øjeblikket, de fleste værker fungerer godt på udendørs data, såsom køredata, men præsterer meget dårligt på indendørs sekvenser med vilkårlige bevægelser."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Telegram skal give FSB-krypteringsnøgler:Russisk domstolTelegram har kæmpet en juridisk kamp for at holde den russiske sikkerhedstjeneste FSB fra at kunne læse brugernes beskeder Ruslands højesteret afgjorde tirsdag, at den populære Telegram messenger-
Telegram skal give FSB-krypteringsnøgler:Russisk domstolTelegram har kæmpet en juridisk kamp for at holde den russiske sikkerhedstjeneste FSB fra at kunne læse brugernes beskeder Ruslands højesteret afgjorde tirsdag, at den populære Telegram messenger- -
 Efterhånden som kontantløse butikker vokser, det samme gør modreaktionenI denne 22. januar, 2018, filbillede en shopper scanner en Amazon Go-app på en mobiltelefon, mens han går ind i en Amazon Go-butik i Seattle. Et lille antal restauranter og butikker bliver kontantfrie
Efterhånden som kontantløse butikker vokser, det samme gør modreaktionenI denne 22. januar, 2018, filbillede en shopper scanner en Amazon Go-app på en mobiltelefon, mens han går ind i en Amazon Go-butik i Seattle. Et lille antal restauranter og butikker bliver kontantfrie -
 For blinde spillere, lige adgang til racervideospilColumbia Engineering datalog Brian A. Smith har udviklet RAD - et racing auditivt display - for at gøre det muligt for synshandicappede spillere at spille de samme typer racerspil, som seende spillere
For blinde spillere, lige adgang til racervideospilColumbia Engineering datalog Brian A. Smith har udviklet RAD - et racing auditivt display - for at gøre det muligt for synshandicappede spillere at spille de samme typer racerspil, som seende spillere -
 Amazon og Google slår CES med digitale assistenter på slæbKredit:CC0 Public Domain Verdens største teknologivirksomheder er på vej til Las Vegas til den årlige CES -messe i næste uge, med selv Apple Inc., der gør en sjælden officiel optræden. Men forvent
Amazon og Google slår CES med digitale assistenter på slæbKredit:CC0 Public Domain Verdens største teknologivirksomheder er på vej til Las Vegas til den årlige CES -messe i næste uge, med selv Apple Inc., der gør en sjælden officiel optræden. Men forvent
- De yderste og indre dele af Sun
- NASAs Terra ser enden på Atlantic Tropical Depression 3
- Himalaya gletscher viser tegn på starten på den industrielle revolution
- Forskning finder, at virkningen af tornadoskader kan tredobles i slutningen af det 21. århundre…
- Slanger i Pinal County, Arizona
- Schweizisk arkæolog opdager den tidligste grav af en skytisk prins