


Det er svært at måle AIs evne til at lære
Kredit:CC0 Public Domain
Organisationer, der ønsker at drage fordel af revolutionen med kunstig intelligens (AI), bør være forsigtige med at lægge alle deres æg i én kurv, har en undersøgelse fra University of Waterloo fundet.
I en undersøgelse offentliggjort i Nature Machine Intelligence , Waterloo-forskere fandt ud af, at i modsætning til konventionel visdom, der kan ikke være nogen nøjagtig metode til at afgøre, om et givet problem kan løses med succes med maskinlæringsværktøjer.
"Vi skal gå frem med forsigtighed, " sagde Shai Ben-David, hovedforfatter af undersøgelsen og professor ved Waterloo's School of Computer Science. "Der er en stor trend af værktøjer, der er meget succesfulde, men ingen forstår hvorfor de har succes, og ingen kan give garantier for, at de fortsat vil have succes.
"I situationer, hvor der kun kræves et ja eller nej svar, vi ved præcis, hvad der kan eller ikke kan gøres med maskinlæringsalgoritmer. Imidlertid, når det kommer til mere generelle opsætninger, vi kan ikke skelne lærlige fra ulærelige opgaver."
I undersøgelsen, Ben-David og hans kolleger overvejede en læringsmodel kaldet estimering af maksimum (EMX), som fanger mange almindelige maskinlæringsopgaver. For eksempel, opgaver som at identificere det bedste sted at lokalisere et sæt distributionsfaciliteter for at optimere deres tilgængelighed for fremtidige forventede forbrugere. Forskningen viste, at ingen matematisk metode nogensinde ville være i stand til at fortælle, fået en opgave i den model, om et AI-baseret værktøj kunne klare den opgave eller ej.
"Dette fund kommer som en overraskelse for forskersamfundet, da det længe har været troet, at når en præcis beskrivelse af en opgave er givet, det kan derefter bestemmes, om maskinlæringsalgoritmer vil være i stand til at lære og udføre denne opgave, sagde Ben-David.
Studiet, Lærbarhed kan være ubeslutsom, var medforfatter af Ben-David, Pavel Hrubeš fra Institut for Matematik ved Videnskabsakademiet i Tjekkiet, Shay Morgan fra Institut for Datalogi, Princeton University, Amir Shpilka, Institut for Datalogi, Tel Aviv Universitet, og Amir Yehudayoff fra Institut for Matematik, Technion-IIT.
 Varme artikler
Varme artikler
-
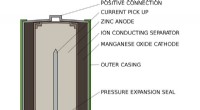 Hvordan virker lithium-ion-batterier?Sådan ser et standard AA alkalisk batteri ud på indersiden. Kredit:Lead holder/Wikimedia Commons Smartphone-æraen er kun lidt over et årti gammel, men computere i lommeformat i hjertet af den samf
Hvordan virker lithium-ion-batterier?Sådan ser et standard AA alkalisk batteri ud på indersiden. Kredit:Lead holder/Wikimedia Commons Smartphone-æraen er kun lidt over et årti gammel, men computere i lommeformat i hjertet af den samf -
 Der er mere end nok solenergi til at opfylde energibehovet - problemet er at lagre detTeslas massive 100 megawatt batterifacilitet i South Australia gemmer vedvarende energi fra vindmøller-men at flytte hele verden til kilder som vind og solenergi vil kræve nye måder at lagre energien
Der er mere end nok solenergi til at opfylde energibehovet - problemet er at lagre detTeslas massive 100 megawatt batterifacilitet i South Australia gemmer vedvarende energi fra vindmøller-men at flytte hele verden til kilder som vind og solenergi vil kræve nye måder at lagre energien -
 Svindelannoncer, der promoverer falske skattelettelser, trives på FacebookI dette skærmbillede lavet fra en Facebook-side, et søgeresultat for solenergiguvernør i Facebooks annoncearkiv viser annoncer, der fejlagtigt lovede sociale mediebrugere, at de kunne få betalt for at
Svindelannoncer, der promoverer falske skattelettelser, trives på FacebookI dette skærmbillede lavet fra en Facebook-side, et søgeresultat for solenergiguvernør i Facebooks annoncearkiv viser annoncer, der fejlagtigt lovede sociale mediebrugere, at de kunne få betalt for at -
 Hvor meget seksualiseret billedsprog former indflydelse på Instagram - og chikane er udbredtKroppen spiller en afgørende rolle i Instagram -influencers selfies. Kredit:https://pixabay.com/photos/adult-body-bra-woman-lingerie-1869735/ Australierne er nogle af de mest aktive sociale medieb
Hvor meget seksualiseret billedsprog former indflydelse på Instagram - og chikane er udbredtKroppen spiller en afgørende rolle i Instagram -influencers selfies. Kredit:https://pixabay.com/photos/adult-body-bra-woman-lingerie-1869735/ Australierne er nogle af de mest aktive sociale medieb
- Aflytning af enkelte molekyler med lys ved at afspille snakken igen
- NASA ser udviklingen af den tropiske storm Ophelia
- Habitater af Centipedes
- Sådan opbevares Fireflies Alive
- Sådan beregnes procentandelen af Change
- Overraskende opdagelse - hvordan den afrikanske tsetse-flue virkelig drikker dit blod