


Genkendelse af sygdom ved hjælp af færre data
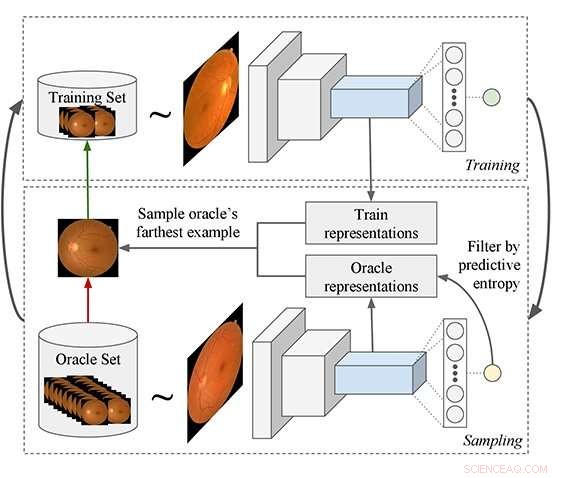
Foreslået aktiv læringspipeline:Processen starter med at træne en model og bruge den til at forespørge efter eksempler fra et umærket datasæt, som derefter føjes til træningssættet. Der foreslås en ny forespørgselsfunktion, der er bedre egnet til Deep Learning (DL) modeller. DL-modellen bruges til at udtrække funktioner fra både orakel- og træningssæteksempler, og så filtrerer algoritmen de orakeleksempler fra, der har lav forudsigelig entropi. Endelig, orakeleksemplet er valgt, der i gennemsnit er det fjerneste i feature space til alle træningseksempler. Kredit:Asim Smailagic
Efterhånden som kunstige intelligenssystemer lærer at bedre genkende og klassificere billeder, de bliver meget pålidelige til at diagnosticere sygdomme, såsom hudkræft, fra medicinske billeder. Men så gode som de er til at opdage mønstre, AI vil ikke erstatte din læge foreløbig. Selv når det bruges som værktøj, billedgenkendelsessystemer kræver stadig en ekspert til at mærke dataene, og en masse data dertil:den har brug for billeder af både raske patienter og syge patienter. Algoritmen finder mønstre i træningsdataene, og når den modtager nye data, den bruger, hvad den har lært til at identificere det nye billede.
En udfordring er, at det er tidskrævende og dyrt for en ekspert at opnå og mærke hvert billede. For at løse dette problem, en gruppe forskere fra Carnegie Mellon University's College of Engineering, herunder professorerne Hae Young Noh og Asim Smailagic, gik sammen om at udvikle en aktiv læringsteknik, der bruger et begrænset datasæt til at opnå en høj grad af nøjagtighed ved diagnosticering af sygdomme som diabetisk retinopati eller hudkræft.
Forskernes model begynder at arbejde med et sæt umærkede billeder. Modellen bestemmer, hvor mange billeder der skal mærkes for at have et robust og præcist sæt træningsdata. Den vælger et indledende sæt af tilfældige data til at mærke. Når disse data er mærket, det plotter disse data over en distribution, fordi billederne vil variere efter alder, køn, fysisk ejendom, osv. For at træffe en god beslutning baseret på disse data, prøverne skal dække et stort distributionsrum. Systemet beslutter derefter, hvilke nye data der skal tilføjes til datasættet, i betragtning af den aktuelle fordeling af data.
"Systemet måler, hvor optimal denne fordeling er, " sagde nej, en lektor i civil- og miljøteknik, "og derefter beregner metrics, når et bestemt sæt nye data tilføjes til det, og vælger det nye datasæt, der maksimerer dets optimalitet."
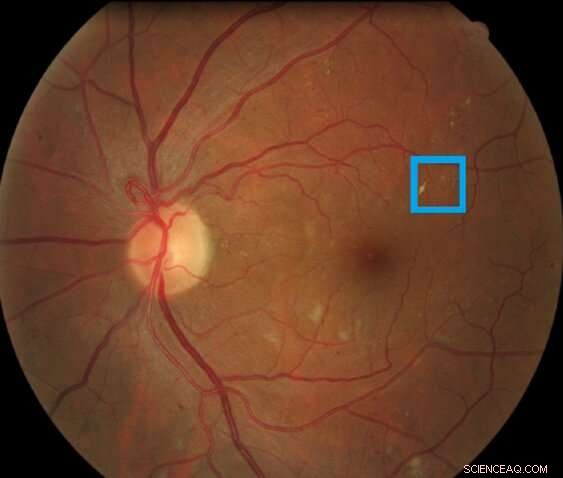
Billede af en nethinde indeholdende en nethindelæsion forbundet med diabetisk retinopati fremhævet i boksen. Denne form for læsion kaldes en mikroaneurisme. Kredit:Asim Smailagic
Processen gentages, indtil sættet af data har en god nok fordeling til at blive brugt som træningssæt. Deres metode, kaldet MedAL (til medicinsk aktiv læring), opnået 80 % nøjagtighed ved påvisning af diabetisk retinopati, bruger kun 425 mærkede billeder, hvilket er en reduktion på 32 % i antallet af påkrævede mærkede eksempler sammenlignet med standard usikkerhedsprøvetagningsteknikken, og en reduktion på 40 % sammenlignet med stikprøveudtagning.
De testede også modellen på andre sygdomme, herunder billeder af hudkræft og brystkræft, at vise, at det kunne gælde for en række forskellige medicinske billeder. Metoden er generaliserbar, da dens fokus er på, hvordan man bruger data strategisk frem for at forsøge at finde et specifikt mønster eller træk for en sygdom. Det kan også anvendes på andre problemer, der bruger deep learning, men som har databegrænsninger.
"Vores aktive læringstilgang kombinerer prædiktiv entropi-baseret usikkerhedssampling og en afstandsfunktion på et indlært funktionsområde for at optimere udvælgelsen af umærkede prøver, " sagde Smailagic, en forskningsprofessor i Carnegie Mellons Engineering Research Accelerator. "Metoden overvinder begrænsningerne ved de traditionelle tilgange ved effektivt kun at udvælge de billeder, der giver mest information om den overordnede datadistribution, reducere beregningsomkostninger og øge både hastighed og nøjagtighed."
Holdet omfattede civil- og miljøingeniør Ph.D. studerende Mostafa Mirshekari, Jonathan Fagert, og Susu Xu, og masterstuderende i el- og computeringeniør Devesh Walawalkar og Kartik Khandelwal. De præsenterede deres resultater på 2018 IEEE International Conference on Machine Learning and Applications i december, hvor de modtog en pris for bedste papir for deres romanværk.
 Varme artikler
Varme artikler
-
 BMW planlægger elektrisk Mini-produktion i KinaI en kinesisk satsning ville Minis blive bygget uden for Europa for første gang Den tyske bilgigant BMW sagde fredag, at de planlægger at bygge en elektrisk version af sin kompakte Mini i Kina. i
BMW planlægger elektrisk Mini-produktion i KinaI en kinesisk satsning ville Minis blive bygget uden for Europa for første gang Den tyske bilgigant BMW sagde fredag, at de planlægger at bygge en elektrisk version af sin kompakte Mini i Kina. i -
 VeryMal:Kampagne i billedbaseret malware spottetKredit:Confiant På dette tidspunkt, nyhedshistorier har lavet ord som fejl, vira og malware kendt og på alle måder hyppige, som computerbrugere kæmper for at selvuddanne sig til, hvordan man undgå
VeryMal:Kampagne i billedbaseret malware spottetKredit:Confiant På dette tidspunkt, nyhedshistorier har lavet ord som fejl, vira og malware kendt og på alle måder hyppige, som computerbrugere kæmper for at selvuddanne sig til, hvordan man undgå -
 Telegram beskylder Apple for at blokere opdateringerTelegram nægtede at give russiske myndigheder en måde at læse kommunikation over sit netværk, da Moskva presser på for at øge overvågningen af internetaktiviteter Sikker besked-app Telegram ankl
Telegram beskylder Apple for at blokere opdateringerTelegram nægtede at give russiske myndigheder en måde at læse kommunikation over sit netværk, da Moskva presser på for at øge overvågningen af internetaktiviteter Sikker besked-app Telegram ankl -
 AI hjælper med at reducere Amazon vandkraft dæmper kulstofaftrykKredit:CC0 Public Domain Et team af forskere har udviklet en beregningsmodel, der bruger kunstig intelligens til at finde steder til vandkraftdæmninger for at hjælpe med at reducere drivhusgasemis
AI hjælper med at reducere Amazon vandkraft dæmper kulstofaftrykKredit:CC0 Public Domain Et team af forskere har udviklet en beregningsmodel, der bruger kunstig intelligens til at finde steder til vandkraftdæmninger for at hjælpe med at reducere drivhusgasemis
- Stor dal fundet på Merkur
- Redirect2Own:En ny tilgang til at beskytte den intellektuelle ejendom af brugeruploadet indhold
- Costco eller Amazon Prime? Flere shoppere vælger begge dele
- Forskere forbedrer prognosen for stigende fare på den ecuadorianske vulkan
- InSight fanger stråler på Mars
- Ny klasse af materialer viser mærkelige elektronegenskaber