


WayPtNav:En ny tilgang til robotnavigation i nye miljøer

Forskerne overvejer problemet med navigation fra en startposition til en målposition. Deres tilgang (WayPtNav) består af et læringsbaseret perceptionsmodul og et dynamikmodelbaseret planlægningsmodul. Perceptionsmodulet forudsiger et waypoint baseret på den aktuelle førstepersons RGB-billedobservation. Dette waypoint bruges af det modelbaserede planlægningsmodul til at designe en controller, der jævnt regulerer systemet til dette waypoint. Denne proces gentages for det næste billede, indtil robotten når målet. Kredit:Bansal et al.
Forskere ved UC Berkeley og Facebook AI Research har for nylig udviklet en ny tilgang til robotnavigation i ukendte miljøer. Deres tilgang, præsenteret i et papir, der er forududgivet på arXiv, kombinerer modelbaserede kontrolteknikker med læringsbaseret perception.
Udviklingen af værktøjer, der gør det muligt for robotter at navigere rundt i omgivelserne, er en central og vedvarende udfordring inden for robotteknologi. I de seneste årtier har forskere har forsøgt at tackle dette problem på en række forskellige måder.
Kontrolforskningsmiljøet har primært undersøgt navigation for en kendt agent (eller et kendt system) inden for et kendt miljø. I disse tilfælde, en dynamikmodel af agenten og et geometrisk kort over det miljø, den vil navigere i, er tilgængelige, Derfor kan optimale kontrolskemaer bruges til at opnå jævne og kollisionsfrie baner, så robotten kan nå et ønsket sted.
Disse skemaer bruges typisk til at styre en række rigtige fysiske systemer, såsom fly eller industrirobotter. Imidlertid, disse tilgange er noget begrænsede, da de kræver eksplicit viden om det miljø, som et system vil navigere i. I det lærende forskningsmiljø, på den anden side, robotnavigation studeres generelt for en ukendt agent, der udforsker et ukendt miljø. Dette betyder, at et system erhverver politikker til direkte at kortlægge indbyggede sensoraflæsninger for at styre kommandoer på en ende-til-ende måde.
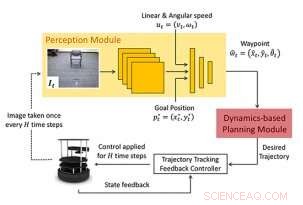
Foreslået ramme:Den nye tilgang til navigation består af et læringsbaseret perceptionsmodul og et dynamikmodelbaseret planlægningsmodul. Perceptionsmodulet består af en CNN, der udsender en ønsket næste tilstand eller et waypoint. Dette waypoint bruges af det modelbaserede planlægningsmodul til at designe en controller, der jævnt regulerer systemet til waypointet. Kredit:Bansal et al.
Disse tilgange kan have flere fordele, da de gør det muligt at lære politikker uden kendskab til systemet og det miljø, det vil navigere i. Ikke desto mindre, tidligere undersøgelser tyder på, at disse teknikker ikke generaliserer godt på tværs af forskellige midler. Ud over, At lære sådanne politikker kræver ofte et stort antal træningsprøver.
"I denne avis, vi studerer robotnavigation i statiske miljøer under antagelsen om perfekt robottilstandsmåling, " skrev forskerne i deres papir. "Vi gør den afgørende observation, at de mest interessante problemer involverer et kendt system i et ukendt miljø. Denne observation motiverer designet af en faktoriseret tilgang, der bruger læring til at tackle ukendte miljøer og udnytter optimal kontrol ved hjælp af kendt systemdynamik til at producere jævn bevægelse."
Holdet af forskere ved UC Berkeley og Facebook trænede en konvolutionelt neuralt netværk (CNN) baseret model på politikker på højt niveau, som bruger aktuelle RGB-billedobservationer til at producere en sekvens af mellemtilstande, eller 'waypoints'. Disse waypoints guider i sidste ende en robot til dens ønskede placering efter en kollisionsfri sti, i hidtil ukendte miljøer.
Deres tilgang, kaldet waypoint-baseret navigation (WayPtNav), i det væsentlige kobler modelbaserede kontrolteknikker med læringsbaseret perception. Det læringsbaserede perceptionsmodul genererer waypoints, som fører robotten til dens målposition via en kollisionsfri sti. Den modelbaserede planlægger, på den anden side, bruger disse waypoints til at generere en jævn og dynamisk gennemførlig bane, som derefter udføres på systemet ved hjælp af feedbackstyring.
Forskerne evaluerede deres tilgang på en hardware testbed, kaldet TurtleBot2. Deres tests samlede meget lovende resultater, med WayPtNav, der muliggør navigation i rodede og dynamiske miljøer, samtidig med at de udkonkurrerer en end-to-end læringstilgang.
"Vores eksperimenter i simulerede, rodede miljøer i den virkelige verden og på et faktisk landkøretøj viser, at den foreslåede tilgang kan nå målplaceringer mere pålideligt og effektivt i nye miljøer sammenlignet med et rent end-to-end læringsbaseret alternativ, " skrev forskerne.
Den nye tilgang præsenteret af dette team af forskere kan forbedre robotnavigation i nye indendørs miljøer. Fremtidige undersøgelser kunne forsøge at forbedre WayPtNav yderligere, adresserer nogle af dets nuværende begrænsninger.
"Vores foreslåede tilgang forudsætter perfekt robottilstandsestimat og anvender en rent reaktiv politik, " forklarede forskerne. "Disse antagelser og valg er muligvis ikke optimale, især til lang række opgaver. At inkorporere rumlig eller visuel hukommelse for at adressere disse begrænsninger ville være frugtbare fremtidige retninger."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Vil Netflix i sidste ende tjene penge på sine brugerdata?Kredit:CC0 Public Domain Selv i kølvandet på en nylig blandet indtjeningsrapport og volatile aktiekurser, Netflix forbliver årtiets mediasucceshistorie. Virksomheden, hvis brugerbase er vokset hur
Vil Netflix i sidste ende tjene penge på sine brugerdata?Kredit:CC0 Public Domain Selv i kølvandet på en nylig blandet indtjeningsrapport og volatile aktiekurser, Netflix forbliver årtiets mediasucceshistorie. Virksomheden, hvis brugerbase er vokset hur -
 Philly start-up Kapsul laver et mere støjsvagt klimaanlæg takket være $2,3 millioner fra crowdfun…Kredit:CC0 Public Domain Sommermånederne, hvor aircondition betragtes som en nødvendighed, er ved at afvikles, men en nystartet virksomhed i Philadelphia arbejder på at tilbyde forbedrede vinduese
Philly start-up Kapsul laver et mere støjsvagt klimaanlæg takket være $2,3 millioner fra crowdfun…Kredit:CC0 Public Domain Sommermånederne, hvor aircondition betragtes som en nødvendighed, er ved at afvikles, men en nystartet virksomhed i Philadelphia arbejder på at tilbyde forbedrede vinduese -
 Topologi optimering og 3-D print multimateriale magnetiske aktuatorer og displaysOversigt over den specifikationsdrevne 3D-printproces. Strukturen af individuelle aktuatorer (eller arrangementet af flere aktuatorer) optimeres ved hjælp af en multiobjektiv topologioptimeringsproc
Topologi optimering og 3-D print multimateriale magnetiske aktuatorer og displaysOversigt over den specifikationsdrevne 3D-printproces. Strukturen af individuelle aktuatorer (eller arrangementet af flere aktuatorer) optimeres ved hjælp af en multiobjektiv topologioptimeringsproc -
 MtGox bitcoin-baron får betinget dom for datamanipulationMark Karpeles, tidligere leder af den kollapsede bitcoin-børs MtGox, har fået en betinget dom på to et halvt år En japansk domstol idømte fredag den tidligere højtflyvende chef for MtGox bitcoin
MtGox bitcoin-baron får betinget dom for datamanipulationMark Karpeles, tidligere leder af den kollapsede bitcoin-børs MtGox, har fået en betinget dom på to et halvt år En japansk domstol idømte fredag den tidligere højtflyvende chef for MtGox bitcoin
- Sætter naturens krystalsymmetri på pause for at fremme målrettet medicinlevering
- NASA analyserer den nyeste subtropiske depression i Atlanterhavet
- Ny, Mælke- og fodermålingssystem i realtid hjælper med at optimere mælkeproduktionen
- Den vesteuropæiske trykanomali kan føre til forbedrede prognoser for ekstreme bølgeforhold
- Sådan fjerner du mus med Ammonia
- Hydrauliske kræfter hjælper med at fylde hjertet