


CycleMatch:en ny tilgang til at matche billeder og tekst
Kredit:Liu et al.
Forskere ved Leiden University og National University of Defense Technology (NUDT), i Kina, for nylig har udviklet en ny tilgang til billed-tekstmatchning, kaldet CycleMatch. Deres tilgang, præsenteret i et papir offentliggjort i Elsevier's Mønster genkendelse tidsskrift, er baseret på cyklus-konsekvent læring, en teknik, der undertiden bruges til at træne kunstige neurale netværk om billed-til-billede oversættelsesopgaver. Den generelle idé bag cykluskonsistens er, at når kildedata transformeres til måldata og så omvendt, man skulle endelig få de originale kildeprøver.
Når det kommer til at udvikle kunstig intelligens (AI) -værktøjer, der fungerer godt i multimodale eller multimediebaserede opgaver, at finde måder at bygge bro mellem billeder og tekstrepræsentationer er af afgørende betydning. Tidligere undersøgelser har forsøgt at opnå dette ved at afdække semantik eller funktioner, der er relevante for både vision og sprog.
Når man træner algoritmer på sammenhænge mellem forskellige modaliteter, imidlertid, disse undersøgelser har ofte forsømt eller undladt at behandle intra-modal semantisk konsistens, som er konsistensen af semantikken for de enkelte modaliteter (dvs. syn og sprog). For at afhjælpe denne mangel, teamet af forskere ved Leiden University og NUDT foreslog en tilgang, der anvender cyklus-konsistente indlejringer til et dybt neuralt netværk for at matche visuelle og tekstuelle repræsentationer.
"Vores tilgang, navngivet som CycleMatch, kan opretholde både intermodale korrelationer og intra-modal konsistens ved at kaskadegøre dobbelte kortlægninger og rekonstruerede kortlægninger på en cyklisk måde, " skrev forskerne i deres papir. "Desuden, for at opnå en robust slutning, Vi foreslår at anvende to metoder til sen fusion:gennemsnitlig fusion og adaptiv fusion. "
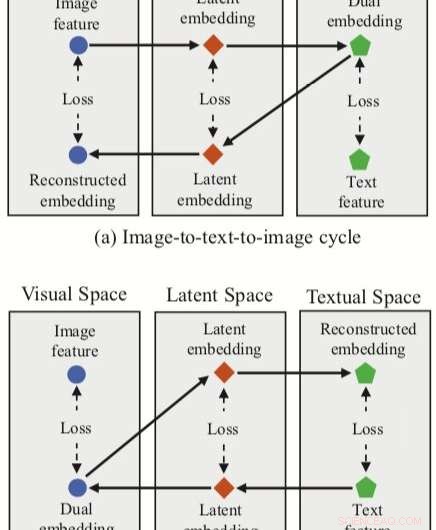
Den tilgang, som forskerne har udtænkt, integrerer tre funktionsindlejringer (dobbelt, rekonstruerede og latente indlejringer) med et neuralt netværk til billed-tekst-matchning. Metoden har to cyklusgrene, et med udgangspunkt i et billedtræk i det visuelle rum og et fra et teksttræk i det tekstlige rum.
For hver af disse cyklusser, deres tilgang opnår en dobbelt kortlægning, oversætte en inputfunktion i kildeområdet til en dobbelt indlejring i målrummet. Forskerne anvender derefter rekonstrueret kortlægning, forsøger at oversætte denne dobbelte indlejring tilbage til kildeområdet.
Deres tilgang giver også forskerne mulighed for at erhverve et 'latent rum' under både dobbelte og rekonstruerede kortlægninger, og efterfølgende korrelere latente indlejringer. I modsætning til andre teknikker til billed-tekst-matchning, derfor, deres metode kan lære både intermodale kortlægninger (dvs. billede-til-tekst og tekst-til-billede) og intra-modale kortlægninger (billede-til-billede og tekst-til-tekst).
For at evaluere deres tilgang, forskerne udførte en række eksperimenter med to anerkendte multimodale datasæt, Flickr30K og MSCOCO. Deres metode opnåede state-of-the-art resultater, udkonkurrerer traditionelle tilgange og fører til betydelige forbedringer i tværmodal genfinding.
Disse resultater tyder på, at cykluskonsistente indlejringer kunne forbedre ydeevnen af neurale netværk i multimodale opgaver, såsom billed-tekst-matchning, giver dem mulighed for at erhverve både intermodale og intra-modale kortlægninger. I deres fremtidige arbejde, forskerne planlægger at udvikle deres tilgang yderligere, ved at tage hensyn til lokale relationer i matchende billeder og tekst (f.eks. semantiske sammenhænge mellem visuelle regioner og sætninger).
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Disney overtager Hulu fra Comcast, da stream wars bliver varmereDenne 27. juni, 2015, fil foto, viser Hulu -logoet på et vindue i Milk Studios -rummet i New York. Disney har indgået en aftale med Comcast, der giver den fuld kontrol over streamingtjenesten Hulu. Se
Disney overtager Hulu fra Comcast, da stream wars bliver varmereDenne 27. juni, 2015, fil foto, viser Hulu -logoet på et vindue i Milk Studios -rummet i New York. Disney har indgået en aftale med Comcast, der giver den fuld kontrol over streamingtjenesten Hulu. Se -
 Amerikanske flyselskaber skærer ned på flyvninger på grund af viruskriseKredit:CC0 Public Domain Amerikanske flyselskaber har annonceret drastiske reduktioner i antallet af flyvninger, efter at præsident Donald Trumps administration forbød udenlandske rejsende at anko
Amerikanske flyselskaber skærer ned på flyvninger på grund af viruskriseKredit:CC0 Public Domain Amerikanske flyselskaber har annonceret drastiske reduktioner i antallet af flyvninger, efter at præsident Donald Trumps administration forbød udenlandske rejsende at anko -
 Specifikationssårbarhed på enheder, der taler Bluetooth, behandlesKredit:CC0 Public Domain Opdagelsen af en fejl i Bluetooth -specifikationen, der kunne muliggøre et angreb for at spionere på dine oplysninger, fik nyheder i denne uge; angriberen kunne svække k
Specifikationssårbarhed på enheder, der taler Bluetooth, behandlesKredit:CC0 Public Domain Opdagelsen af en fejl i Bluetooth -specifikationen, der kunne muliggøre et angreb for at spionere på dine oplysninger, fik nyheder i denne uge; angriberen kunne svække k -
 Undersøgelse finder, at brugere, der forlader Facebook, er gladere, men mindre informeretKredit:Henryk Ditze, Shutterstock Kritikere siger, at Facebooks kontroverser og kritik alene i 2018, fra bekymringer om privatlivets fred til Cambridge Analytica-dataskandalen, burde være nok til
Undersøgelse finder, at brugere, der forlader Facebook, er gladere, men mindre informeretKredit:Henryk Ditze, Shutterstock Kritikere siger, at Facebooks kontroverser og kritik alene i 2018, fra bekymringer om privatlivets fred til Cambridge Analytica-dataskandalen, burde være nok til
- En oplysende mulighed for slagtilfældebehandling:Nano-fotosyntese
- En ny sphenodontian fra Brasilien er den ældste rekord for gruppen i Gondwana
- Journalistjob er usikre, økonomisk usikker og kræver familiestøtte
- FN's klimarapport:Ændre arealanvendelse for at undgå en sulten fremtid
- Forudsigelse af amerikanske økonomiske og demografiske skift ved højere opløsning
- Indisk opsendelsesforsøg af jordobservationssatellit mislykkes