


Træk-og-slip dataanalyse

Årevis, forskere fra MIT og Brown University har udviklet et interaktivt system, der lader brugere trække-og-slip og manipulere data på enhver berøringsskærm, herunder smartphones og interaktive tavler. Nu, de har inkluderet et værktøj, der øjeblikkeligt og automatisk genererer maskinlæringsmodeller til at køre forudsigelsesopgaver på disse data. Kredit:Melanie Gonick
I den Jernmand film, Tony Stark bruger en holografisk computer til at projicere 3D-data ud i den blå luft, manipulere dem med sine hænder, og finde løsninger på hans superhelteproblemer. På samme måde, forskere fra MIT og Brown University har nu udviklet et system til interaktiv dataanalyse, der kører på berøringsskærme og lader alle – ikke kun geni, milliardær, playboy-filantroper – takl problemer i den virkelige verden.
Årevis, forskerne har udviklet et interaktivt datavidenskabssystem kaldet Northstar, som kører i skyen, men har en grænseflade, der understøtter enhver berøringsskærmenhed, herunder smartphones og store interaktive tavler. Brugere fodrer systemdatasættene, og manipulere, forene, og udtræk funktioner på en brugervenlig grænseflade, ved at bruge deres fingre eller en digital pen, at afdække trends og mønstre.
I et papir, der præsenteres på ACM SIGMOD-konferencen, forskerne beskriver en ny komponent af Northstar, kaldet VDS for "virtuel dataforsker, ", der øjeblikkeligt genererer maskinlæringsmodeller til at køre forudsigelsesopgaver på deres datasæt. Læger, for eksempel, kan bruge systemet til at hjælpe med at forudsige, hvilke patienter der er mere tilbøjelige til at have visse sygdomme, mens virksomhedsejere måske ønsker at forudsige salg. Hvis du bruger en interaktiv tavle, alle kan også samarbejde i realtid.
Målet er at demokratisere datavidenskab ved at gøre det nemt at lave komplekse analyser, hurtigt og præcist.
"Selv en caféejer, der ikke kender til datavidenskab, burde være i stand til at forudsige deres salg i løbet af de næste par uger for at finde ud af, hvor meget kaffe de skal købe, " siger medforfatter og mangeårig Northstar-projektleder Tim Kraska, en lektor i elektroteknik og datalogi ved MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) og stiftende meddirektør for det nye Data System og AI Lab (DSAIL). "I virksomheder, der har dataforskere, der er meget frem og tilbage mellem dataforskere og ikke-eksperter, så vi kan også bringe dem ind i ét rum for at lave analyser sammen."
VDS er baseret på en stadig mere populær teknik inden for kunstig intelligens kaldet automatiseret machine-learning (AutoML), som lader folk med begrænset data-videnskab knowhow træne AI-modeller til at lave forudsigelser baseret på deres datasæt. I øjeblikket, værktøjet leder DARPA D3M Automatic Machine Learning-konkurrencen, som hvert halve år beslutter sig for det bedst ydende AutoML-værktøj.
Sammen med Kraska på papiret er:første forfatter Zeyuan Shang, en kandidatstuderende, og Emanuel Zgraggen, en postdoc og hovedbidragyder til Northstar, begge EECS, CSAIL, og DSAIL; Benedetto Buratti, Yeounoh Chung, Philipp Eichmann, og Eli Upfal, hele Brown; og Carsten Binnig, der for nylig flyttede fra Brown til det tekniske universitet i Darmstadt i Tyskland.

Kredit:Melanie Gonick
Et "ubegrænset lærred" til analyse
Det nye arbejde bygger på mange års samarbejde om Northstar mellem forskere ved MIT og Brown. Over fire år, forskerne har offentliggjort adskillige artikler, der beskriver komponenter af Northstar, inklusive den interaktive grænseflade, operationer på flere platforme, accelererende resultater, og undersøgelser af brugeradfærd.
Northstar starter som en blank, hvid grænseflade. Brugere uploader datasæt til systemet, som vises i en "datasæt" -boks til venstre. Eventuelle dataetiketter vil automatisk udfylde en separat "attributter"-boks nedenfor. Der er også en "operatør"-boks, der indeholder forskellige algoritmer, samt det nye AutoML-værktøj. Alle data gemmes og analyseres i skyen.
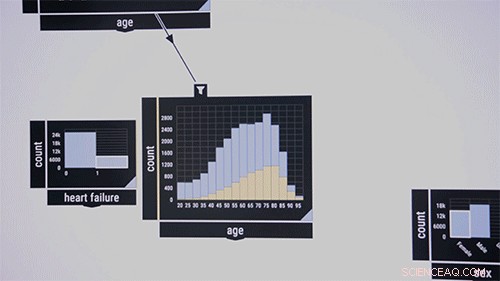
Forskerne kan godt lide at demonstrere systemet på et offentligt datasæt, der indeholder information om intensivpatienter. Overvej medicinske forskere, der ønsker at undersøge samtidige forekomster af visse sygdomme i bestemte aldersgrupper. De trækker og slipper ind i midten af grænsefladen en mønsterkontrolalgoritme, som først fremstår som en tom boks. Som input, de flytter ind i boksen sygdomstræk mærket, sige, "blod, " "smittende, " og "metabolisk." Procentdele af disse sygdomme i datasættet vises i boksen. Derefter de trækker "alder"-funktionen ind i grænsefladen, som viser et søjlediagram over patientens aldersfordeling. Tegning af en linje mellem de to felter forbinder dem med hinanden. Ved at kredse om aldersgrupper, Algoritmen beregner med det samme forekomsten af de tre sygdomme i aldersgruppen.
"Det er ligesom en stor, ubegrænset lærred, hvor du kan lægge ud, hvordan du vil have alt, " siger Zgraggen, som er nøgleopfinderen af Northstars interaktive grænseflade. "Derefter, du kan koble ting sammen for at skabe mere komplekse spørgsmål om dine data."
Tilnærmelsesvis AutoML
Med VDS, brugere kan nu også køre forudsigende analyser på disse data ved at få modeller tilpasset deres opgaver, såsom dataforudsigelse, billedklassificering, eller analysere komplekse grafstrukturer.
Ved hjælp af ovenstående eksempel, siger, at de medicinske forskere ønsker at forudsige, hvilke patienter der kan have blodsygdom baseret på alle funktioner i datasættet. De trækker og slipper "AutoML" fra listen over algoritmer. Det vil først producere en tom boks, men med en "mål"-fane, hvorunder de ville slippe funktionen "blod". Systemet vil automatisk finde de bedste maskinlæringsrørledninger, præsenteret som faner med konstant opdaterede nøjagtighedsprocenter. Brugere kan stoppe processen til enhver tid, finjuster søgningen, og undersøge hver models fejlprocenter, struktur, beregninger, og andre ting.
Kredit:Melanie Gonick
Ifølge forskerne, VDS er det hurtigste interaktive AutoML-værktøj til dato, tak, delvis, til deres brugerdefinerede "estimeringsmotor". Motoren sidder mellem grænsefladen og skylageret. Motoren udnytter automatisk flere repræsentative prøver af et datasæt, der gradvist kan behandles for at producere resultater af høj kvalitet på få sekunder.
"Sammen med mine medforfattere brugte jeg to år på at designe VDS for at efterligne, hvordan en dataforsker tænker, "Shang siger, hvilket betyder, at den øjeblikkeligt identificerer, hvilke modeller og forbehandlingstrin, den skal eller ikke bør køre på bestemte opgaver, baseret på forskellige indkodede regler. Den vælger først fra en stor liste over de mulige maskinlæringspipelines og kører simuleringer på prøvesættet. Derved, den husker resultater og forfiner sit valg. Efter at have leveret hurtige tilnærmede resultater, systemet forfiner resultaterne i bagenden. Men de endelige tal er normalt meget tæt på den første tilnærmelse.
"For at bruge en forudsigelse, du ønsker ikke at vente fire timer på at få dine første resultater tilbage. Du vil allerede se, hvad der sker, og hvis du opdager en fejl, du kan straks rette det. Det er normalt ikke muligt i noget andet system, "Siger Kraska. Forskernes tidligere brugerundersøgelse, faktisk, "viser, at i det øjeblik du udsætter at give brugerne resultater, de begynder at miste engagementet med systemet. "
Forskerne evaluerede værktøjet på 300 datasæt fra den virkelige verden. Sammenlignet med andre avancerede AutoML-systemer, VDS 'tilnærmelser var lige så nøjagtige, men blev genereret inden for få sekunder, som er meget hurtigere end andre værktøjer, som kører på minutter til timer.
Næste, forskerne søger at tilføje en funktion, der advarer brugerne om potentiel dataskævhed eller fejl. For eksempel, to protect patient privacy, sometimes researchers will label medical datasets with patients aged 0 (if they do not know the age) and 200 (if a patient is over 95 years old). But novices may not recognize such errors, which could completely throw off their analytics.
"If you're a new user, you may get results and think they're great, " Kraska says. "But we can warn people that there, faktisk, may be some outliers in the dataset that may indicate a problem."
Denne historie er genudgivet med tilladelse fra MIT News (web.mit.edu/newsoffice/), et populært websted, der dækker nyheder om MIT-forskning, innovation og undervisning.
 Varme artikler
Varme artikler
-
 Slanger hjælper ingeniører med at designe søge- og redningsrobotterJohns Hopkins Universitys Terradynamics Lab skabte denne slangerobot for at efterligne dens dyremodstykke. Kredit:JHU/Will Kirk Slanger lever i forskellige miljøer lige fra ulidelig varme ørkener
Slanger hjælper ingeniører med at designe søge- og redningsrobotterJohns Hopkins Universitys Terradynamics Lab skabte denne slangerobot for at efterligne dens dyremodstykke. Kredit:JHU/Will Kirk Slanger lever i forskellige miljøer lige fra ulidelig varme ørkener -
 Følelseslæsende algoritmer kan ikke forudsige intentioner via ansigtsudtrykKredit:CC0 Public Domain De fleste algoritmer har sandsynligvis aldrig hørt Eagles sang, Lyin Eyes. Ellers, de ville gøre et bedre stykke arbejde med at genkende dobbelthed. Computere er ikke sær
Følelseslæsende algoritmer kan ikke forudsige intentioner via ansigtsudtrykKredit:CC0 Public Domain De fleste algoritmer har sandsynligvis aldrig hørt Eagles sang, Lyin Eyes. Ellers, de ville gøre et bedre stykke arbejde med at genkende dobbelthed. Computere er ikke sær -
 Forskere udvikler en bedre måde at udnytte solpanelernes kraft påKredit:CC0 Public Domain Forskere ved University of Waterloo har udviklet en måde til bedre at udnytte mængden af energi, der indsamles af solpaneler. I en ny undersøgelse, forskerne udviklede
Forskere udvikler en bedre måde at udnytte solpanelernes kraft påKredit:CC0 Public Domain Forskere ved University of Waterloo har udviklet en måde til bedre at udnytte mængden af energi, der indsamles af solpaneler. I en ny undersøgelse, forskerne udviklede -
 Ryanairs overskud i første halvår falder 7% efter omfattende strejkerlavprispioner Ryanair sagde, at indtjeningen i første halvår faldt syv procent, efter at en omfattende strejke fra piloter og kabinepersonalet havde forstyrret driften. Ryanairs første halvår til
Ryanairs overskud i første halvår falder 7% efter omfattende strejkerlavprispioner Ryanair sagde, at indtjeningen i første halvår faldt syv procent, efter at en omfattende strejke fra piloter og kabinepersonalet havde forstyrret driften. Ryanairs første halvår til
- Hvad er Torrid Zone?
- Forskere opdager alvorlige bluetooth-kommunikationsbrud
- For superledere, opdagelse kommer fra uorden
- Japan lister Fukushima-strålingsniveauerne på S. Koreas ambassadested
- Klimaændringer kan undergrave børns uddannelse og udvikling i troperne
- Hvordan skolebestyrelsesmøder kunne tiltrække flere forskellige målgrupper og øge offentligheden…