


En multirepræsentativ konvolutionel neural netværksarkitektur til tekstklassificering
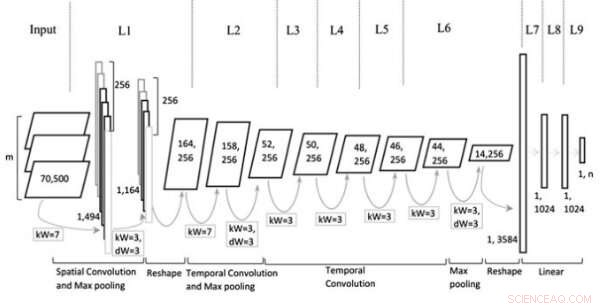
Model arkitektur. Kredit:Jin et al. Wiley Computational Intelligence journal.
I løbet af det seneste årti eller deromkring, konvolutionelle neurale netværk (CNN'er) har vist sig at være meget effektive til at løse forskellige opgaver, herunder naturlig sprogbehandling (NLP) opgaver. NLP indebærer brug af beregningsteknikker til at analysere eller syntetisere sprog, både i skriftlig og mundtlig form. Forskere har med succes anvendt CNN'er til adskillige NLP-opgaver, inklusive semantisk parsing, hentning af søgeforespørgsler og tekstklassificering.
Typisk, CNN'er, der er uddannet til tekstklassificeringsopgaver, behandler sætninger på ordniveau, repræsenterer individuelle ord som vektorer. Selvom denne tilgang kan forekomme i overensstemmelse med, hvordan mennesker behandler sprog, nyere undersøgelser har vist, at CNN'er, der behandler sætninger på karakterniveau, også kan opnå bemærkelsesværdige resultater.
En vigtig fordel ved analyser på karakterniveau er, at de ikke kræver forudgående kendskab til ord. Dette gør det lettere for CNN'er at tilpasse sig forskellige sprog og tilegne sig unormale ord forårsaget af stavefejl.
Tidligere undersøgelser tyder på, at forskellige niveauer af tekstindlejring (dvs. karakter-, ord-, eller -dokumentniveau) er mere effektive til forskellige typer opgaver, men der er stadig ingen klar vejledning om, hvordan man vælger den rigtige indlejring, eller hvornår man skal skifte til en anden. Med det i tankerne, et team af forskere ved Tianjin Polytechnic University i Kina har for nylig udviklet en ny CNN-arkitektur baseret på typer af repræsentation, der typisk bruges i tekstklassificeringsopgaver.
"Vi foreslår en ny arkitektur af CNN baseret på flere repræsentationer for tekstklassificering ved at konstruere flere fly, så flere oplysninger kan dumpes ind i netværkerne, såsom forskellige dele af tekst opnået gennem en navngivet enhedsgenkendelse eller ordstemmetaggingværktøjer, forskellige niveauer af tekstindlejring eller kontekstuelle sætninger, " skrev forskerne i deres papir.
Den multirepræsentative CNN-model (Mr-CNN) udviklet af forskerne er baseret på den antagelse, at alle dele af skrevet tekst (f.eks. navneord, verber, osv.) spiller en nøglerolle i klassifikationsopgaver, og at forskellige tekstindlejringer er mere effektive til forskellige formål. Deres model kombinerer to nøgleværktøjer, den Stanford-navngivne enhedsgenkender (NER) og tag-delemaskinen (POS). Førstnævnte er en metode til mærkning af tinges semantiske roller i tekster (f.eks. Person, Selskab, etc.); sidstnævnte er en teknik, der bruges til at tildele del af tale-tags til hver tekstblok (f.eks. navneord eller verbum).
Forskerne brugte disse værktøjer til at forbehandle sætninger, opnå flere delmængder af den oprindelige sætning, som hver især indeholder bestemte typer ord i teksten. De brugte derefter undersættene og den fulde sætning som flere repræsentationer for deres Mr-CNN-model.
Når det evalueres på tekstklassificeringsopgaver med tekst fra forskellige store og domænespecifikke datasæt, Mr-CNN-modellen opnåede en bemærkelsesværdig præstation, med en forbedring på maksimalt 13 procent fejlprocent på ét datasæt og en forbedring på 8 procent på et andet. Dette tyder på, at flere repræsentationer af tekst giver netværket mulighed for adaptivt at fokusere sin opmærksomhed på den mest relevante information, forbedre dets klassificeringsmuligheder.
"Forskellige store, domænespecifikke datasæt blev brugt til at validere den foreslåede arkitektur, " skrev forskerne. "De analyserede opgaver omfatter ontologisk dokumentklassificering, kategorisering af biomedicinske begivenheder, og sentimentanalyse, viser, at multirepræsentative CNN'er, som lærer at fokusere opmærksomheden på specifikke repræsentationer af tekst, kan opnå yderligere gevinster i ydelse i forhold til state-of-the-art dybe neurale netværksmodeller. "
I deres fremtidige arbejde, forskerne planlægger at undersøge, om finkornede funktioner kan være med til at forhindre overtilpasning af træningsdatasættet. De ønsker også at udforske andre metoder, der kan forbedre analysen af specifikke dele af sætninger, potentielt forbedre modellens ydeevne yderligere.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 At lukke internettet ned virker ikke - men regeringer bliver ved med at gøre detKredit:CC0 Public Domain Efterhånden som internettet fortsætter med at vinde betydelig magt og handlekraft rundt om i verden, mange regeringer har flyttet for at regulere det. Og hvor regulering m
At lukke internettet ned virker ikke - men regeringer bliver ved med at gøre detKredit:CC0 Public Domain Efterhånden som internettet fortsætter med at vinde betydelig magt og handlekraft rundt om i verden, mange regeringer har flyttet for at regulere det. Og hvor regulering m -
 Havudforskningssansning med lys og lydKAUST-forskere modellerer forskellige teknikker til at forbedre trådløse undervandssensornetværk. For eksempel, nye trådløse hybridsensorer, der bruger både akustisk og optisk kommunikation, kan forbe
Havudforskningssansning med lys og lydKAUST-forskere modellerer forskellige teknikker til at forbedre trådløse undervandssensornetværk. For eksempel, nye trådløse hybridsensorer, der bruger både akustisk og optisk kommunikation, kan forbe -
 Twitter:1 million konti suspenderet for fremme af terrorismeTwitter siger, at mere end en million konti er blevet suspenderet siden 2015 for fremme af terrorisme Twitter sagde torsdag, at det har suspenderet over en million konti for fremme af terrorisme s
Twitter:1 million konti suspenderet for fremme af terrorismeTwitter siger, at mere end en million konti er blevet suspenderet siden 2015 for fremme af terrorisme Twitter sagde torsdag, at det har suspenderet over en million konti for fremme af terrorisme s -
 Health tracking sensor til kæledyr og mennesker overvåger vitale tegn gennem pels eller tøjBombe -sniffende hund med sensoren og dens resultater. Kredit:Imperial College London Imperial College London -forskere har opfundet en ny sundhedssporingssensor til kæledyr og mennesker, der over
Health tracking sensor til kæledyr og mennesker overvåger vitale tegn gennem pels eller tøjBombe -sniffende hund med sensoren og dens resultater. Kredit:Imperial College London Imperial College London -forskere har opfundet en ny sundhedssporingssensor til kæledyr og mennesker, der over
- Forholdet mellem ENSO og indisk sommermonsunregn styrker igen
- Ankelmonitorer kan stigmatisere brugere, siger forskning
- Farver der tiltrækker sorte fluer
- Forskere afslører, hvordan et mikrotubuli-relateret gen påvirker neural udvikling
- Hvordan man hæver shiners til fisk agn
- Forskning finder, at flere næringsstoffer er nødvendige for, at planteplankton kan trives