


Forskere udvikler en metode til at identificere computergenereret tekst

Kredit:Petr Kratochvil/offentligt domæne
I en verden af dybe forfalskninger og alt for menneskeligt naturligt sprog AI, forskere ved Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) og IBM Research spurgte:Er der en bedre måde at hjælpe folk med at opdage AI-genereret tekst?
Det spørgsmål fik Sebastian Gehrmann til, en ph.d. kandidat hos SEAS, og Hendrik Strobelt, en forsker hos IBM, at udvikle en statistisk metode, sammen med et interaktivt værktøj med åben adgang, at detektere AI-genereret tekst.
Generatorer af naturlige sprog er trænet i titusinder af onlinetekster og efterligner menneskeligt sprog ved at forudsige de ord, der oftest kommer efter hinanden. For eksempel, ordene "har" "er" og "var" er statisk mest tilbøjelige til at komme efter ordet "jeg".
Ved at bruge den idé, Gehrmann og Strobelt udviklede en metode, der bl. i stedet for at identificere fejl i tekst, identificerer tekst, der er for forudsigelig.
"Idéen vi havde er, at efterhånden som modellerne bliver bedre og bedre, de går fra absolut værre end mennesker, som er sporbar, til lige så god som eller bedre end mennesker, som kan være svære at opdage med konventionelle metoder, sagde Gehrmann.
"Før, du kunne se på alle fejlene, at teksten var maskingenereret, sagde Strobelt. det er ikke længere fejlene, men snarere brugen af meget sandsynlige (og lidt kedelige) ord, der kalder maskingenereret tekst. Med dette værktøj, mennesker og kunstig intelligens kan arbejde sammen om at opdage falsk tekst."
Gehrmann og Strobelt vil præsentere deres forskning, som var medforfatter af Alexander Rush, Associate in Computer Science hos SEAS, ved Association for Computational Linguistics (ACL) konference den 28. juli - 2. august.
Gehrmann og Strobelts metode, kendt som GLTR, er baseret på en model, der er trænet på 45 millioner tekster fra websteder – den offentlige version af OpenAI-modellen, GPT-2. Fordi den bruger GPT-2 til at registrere genereret tekst, GLTR virker bedst mod GPT-2, men klarer sig også godt mod andre modeller.
Sådan fungerer det:
Hvis du fører en tekstpassage ind i værktøjet, det fremhæver teksten med grønt, gul, rød eller lilla, hver farve angiver forudsigeligheden af ordet i sammenhæng med ordet før det. Grøn betyder, at ordet var meget forudsigeligt, gul, moderat forudsigelig, rød ikke særlig forudsigelig og lilla betyder, at modellen slet ikke ville have forudsagt ordet.
Så et tekstafsnit genereret af GPT-2 vil se sådan ud:

Kredit:Harvard University
At sammenligne, dette er en rigtig New York Times artikel:
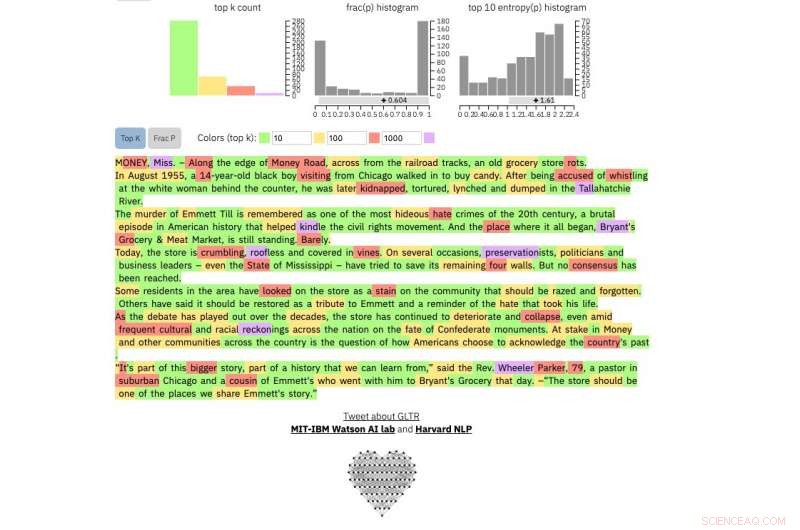
Kredit:Harvard University
Og dette er et uddrag fra uden tvivl den mest uforudsigelige menneskelige tekst, der nogensinde er skrevet, James Joyce's Finnegans Wake :
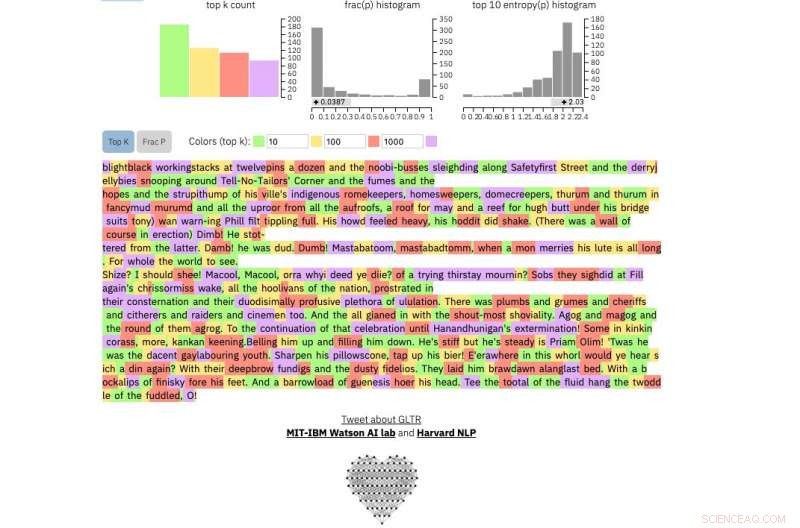
Kredit:Harvard University
Metoden er ikke beregnet til at erstatte mennesker med at identificere falske tekster, men snarere at understøtte menneskelig intuition og forståelse. Forskerne testede modellen med en gruppe studerende i en SEAS Computer Science-klasse.
Uden modellen, eleverne kunne identificere omkring 50 procent af AI-genereret tekst. Med farveoverlayet, eleverne kunne identificere 72 pct.
Gehrmann og Strobelt siger, at med lidt træning og erfaring med programmet, antallet kunne blive endnu bedre.
"Vores mål er at skabe menneskelige og AI-samarbejdssystemer, " sagde Gehrmann. "Denne forskning er rettet mod at give mennesker mere information, så de kan træffe en informeret beslutning om, hvad der er ægte, og hvad der er falsk."
 Varme artikler
Varme artikler
-
 Ford planlægger at øge 1, 150 job i Storbritannien:fagforeningStorbritannien planlægger i alt 1, 150 tab af job på Fords motorfabrik i Wales Ford planlægger at skære 1, 150 job i Storbritannien, meddelte en fagforening fredag, en dag efter at den amerikanske
Ford planlægger at øge 1, 150 job i Storbritannien:fagforeningStorbritannien planlægger i alt 1, 150 tab af job på Fords motorfabrik i Wales Ford planlægger at skære 1, 150 job i Storbritannien, meddelte en fagforening fredag, en dag efter at den amerikanske -
 Annoncering er lige blevet mikro-personlig-hvorfor er vi ligegladeKredit:CC0 Public Domain Med al den brummer og hysteri om, hvordan forbrugere snedigt mikromålrettes i et bud på tankekontrol, ikke kun af annoncører af produkter, men også af politiske partier, f
Annoncering er lige blevet mikro-personlig-hvorfor er vi ligegladeKredit:CC0 Public Domain Med al den brummer og hysteri om, hvordan forbrugere snedigt mikromålrettes i et bud på tankekontrol, ikke kun af annoncører af produkter, men også af politiske partier, f -
 Edmunds undersøger 3 semi-autonome køresystemerDette billede leveret af Nissan viser en 2018 Nissan Rogue, som fås med et semiautonomt køresystem kaldet ProPilot Assist. Nissans nye ProPilot Assist-system er bedst på motorveje med svage sving og g
Edmunds undersøger 3 semi-autonome køresystemerDette billede leveret af Nissan viser en 2018 Nissan Rogue, som fås med et semiautonomt køresystem kaldet ProPilot Assist. Nissans nye ProPilot Assist-system er bedst på motorveje med svage sving og g -
 Rise of the Robots:Kommer til en første-års Intro to Journalism-klasse nær digKredit:Lehigh University Kunstig intelligens (AI) transformerer menneskelig interaktion i næsten alle aspekter af livet, fra hvordan forretning drives til hvordan folk får adgang til sundhedspleje
Rise of the Robots:Kommer til en første-års Intro to Journalism-klasse nær digKredit:Lehigh University Kunstig intelligens (AI) transformerer menneskelig interaktion i næsten alle aspekter af livet, fra hvordan forretning drives til hvordan folk får adgang til sundhedspleje