


En brugervenlig tilgang til aktiv belønningslæring i robotter
Kredit:Bıyık et al.
I de seneste år, forskere har forsøgt at udvikle metoder, der gør robotter i stand til at lære nye færdigheder. En mulighed er, at en robot lærer disse nye færdigheder fra mennesker, stille spørgsmål, når den er usikker på, hvordan man skal opføre sig, og lære af den menneskelige brugers svar.
Et forskerhold ved Stanford University har for nylig udviklet en brugervenlig tilgang til aktiv belønningslæring, som kan bruges til at træne robotter ved at få menneskelige brugere til at svare på deres spørgsmål. Denne nye tilgang, præsenteret i et papir, der er forudgivet på arXiv, træner robotter til at stille spørgsmål, som vil være nemme for en menneskelig bruger at besvare, og som ikke er overflødige eller unødvendige.
"Vores gruppe er interesseret i, hvordan robotter kan lære, hvad mennesker vil have, " fortalte forskerne TechXplore via e-mail. "En intuitiv måde at lære på er ved at stille spørgsmål. For eksempel, vil du hellere køre en selvkørende bil forsigtigt eller aggressivt? Skal denne autonome bil smelte sammen foran eller bagved en menneskedrevet bil?"
Hovedantagelsen bag den nylige undersøgelse er, at ideelt set, Robotter bør stille informative spørgsmål, der får så meget information som muligt fra menneskelige brugere. Med andre ord, en robot skal være i stand til at forstå, hvad et menneske har brug for eller vil have dem til at gøre ved at stille så få spørgsmål som muligt.
I virkeligheden, imidlertid, de fleste eksisterende træningsmetoder baseret på spørgsmålsbesvarelse tager ikke højde for, hvor let det vil være for menneskelige brugere at besvare specifikke spørgsmål formuleret af robotten. Dette resulterer ofte i, at brugere spilder deres tid på at svare på masser af unødvendige spørgsmål eller ikke er i stand til at svare med sikkerhed.
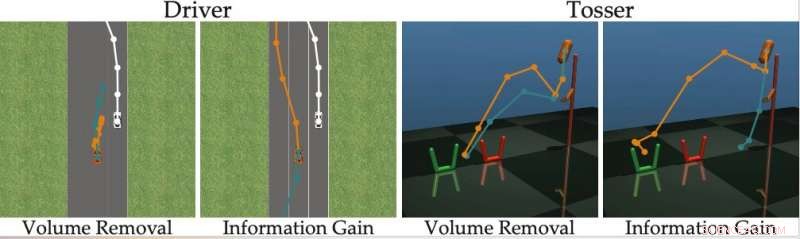
"Vi fandt ud af, at de fleste avancerede algoritmer viser de menneskelige alternativer, der (næsten) ikke kan skelnes, forhindrer personen i at svare korrekt på robottens spørgsmål, " sagde forskerne. "Vend tilbage til vores eksempel, disse tilgange kan spørge:"Vil du hellere smelte sammen foran den menneskedrevne bil med en hastighed på 49 km/t, eller en hastighed på 31 mph?" Dette kan være informativt for robotten at beslutte, om mennesket vil køre hurtigere end 30 mph eller ej, men mulighederne er så tætte, at mennesker ikke kan reagere pålideligt."
For at overvinde begrænsningerne ved eksisterende aktive læringsmetoder, forskerne udviklede en algoritme, der kan vælge mere effektive spørgsmål at stille menneskelige brugere. Algoritmen identificerer spørgsmål, der mest reducerer robottens usikkerhed om en menneskelig brugers præferencer (dvs. som maksimerer informationsgevinsten), mens man også overvejer, hvor nemt det vil være for en menneskelig bruger at besvare dem.

Kredit:Bıyık et al.
"Inspireret af manglerne i tidligere værker, da vi udviklede denne algoritme, vi fokuserede på at redegøre for menneskets evne til faktisk at besvare de spørgsmål, som robotten stiller, " sagde forskerne. "Dette er baseret på ideen om, at kun robotter, der redegør for menneskets evne til at svare, kan præcist og effektivt lære, hvad mennesker vil have."
Forskerne beregnede informationsgevinst ved at måle faldet i entropi (dvs. et mål for usikkerhed) over den menneskelige brugers præferencer som funktion af spørgsmålet stillet af robotten. Med andre ord, et spørgsmål, der maksimerer informationsgevinsten, vil mest reducere robottens usikkerhed om, hvad den menneskelige brugers præferencer er. Dette giver robotter et formelt mål, som de kan bruge til at vælge spørgsmål, der er mest informative.
"Et godt kendetegn ved informationsgevinst er, at den i sagens natur maksimerer robottens usikkerhed (så robotten lærer meget af spørgsmålet), samtidig med at den minimerer menneskets usikkerhed (så spørgsmålet er nemt for mennesket at svare på), " forklarede forskerne. "At generere spørgsmålene ved hjælp af informationsindvinding forbedrer således aktiv læring, ikke kun fordi spørgsmålene er maksimalt informative, men også fordi mennesket giver færre fejlagtige svar."
Den tilgang, som forskerne har udtænkt, udvælger grådigt det spørgsmål, der maksimerer informationsindvindingen på hvert tidspunkt. I det væsentlige, robotten fastholder en tro (dvs. en sandsynlighedsfordeling) over præferencerne hos den bruger, den interagerer med, og prøver fra både denne overbevisning og rummet af mulige spørgsmål.
Ultimativt, robotten vælger det spørgsmål, der giver størst informationsgevinst på tværs af den aktuelle fordeling af mulige menneskelige præferencer. Efterfølgende den opdaterer sin overbevisning om, hvad brugeren ønsker, baseret på det svar, den modtager. Denne proces gentages løbende, giver robotten mulighed for gradvist at forbedre sin ydeevne ved at lære om brugerens præferencer.
"Vi formulerede en beregningsmæssigt håndterbar metode, der giver os mulighed for hurtigt at opdage menneskelige præferencer på rigtige robotopgaver, bedre end tidligere metoder, " sagde forskerne. "I vores undersøgelse, brugere foretrak vores metode frem for andre avancerede teknikker."
I deres undersøgelse, Det Stanford-baserede team viste, at træning af en robot til at stille spørgsmål, der maksimerer informationsgevinsten, har samme beregningsmæssige kompleksitet som avancerede metoder. Med andre ord, det er ikke sværere for robotten at finde disse informative spørgsmål, sammenlignet med dem, der genereres af andre tilgange.
"Vi påpeger også, at vores tilgang har flere ønskelige matematiske egenskaber, såsom submodularitet, som sætter os i stand til at tage de udvidelser og teoretiske grænser, der blev udviklet for tidligere tilgange, og også bruge dem med vores metode, " sagde forskerne. "F.eks. vi kan bruge tidligere værker til at finde flere informative spørgsmål på én gang, i stedet for at søge efter ét spørgsmål ad gangen."
Holdet evaluerede deres aktive belønningslæringstilgang i en række simuleringer og fandt ud af, at det giver robotter mulighed for at forstå menneskelige præferencer hurtigere og mere præcist end andre avancerede metoder. Dette viste sig også at være sandt i situationer, hvor mennesker kan besvare vanskelige spørgsmål korrekt, eller når deres svar er "Jeg ved det ikke."
Forskerne udførte også en brugerundersøgelse, hvor de bad menneskelige deltagere om at besvare spørgsmål genereret af deres metode og andre genereret ved hjælp af andre state-of-the-art tilgange. Den feedback, de har indsamlet, tyder på, at folk synes, at spørgsmål genereret af deres tilgang er meget nemmere at besvare. Ud over, brugere følte ofte, at robotter, der brugte den nye metode, havde opnået en mere præcis repræsentation af deres præferencer, end de gjorde med tidligere foreslåede tilgange.
"I betragtning af alle vores bidrag samlet, vi tog et skridt hen imod at sætte robotter i stand til at bestemme menneskelige præferencer, " sagde forskerne. "Vi viste, at det sande mål, som vi oprindeligt ønskede, at robotten skulle maksimere - at stille spørgsmål for at få så meget information som muligt - faktisk kan løses med samme beregningsmæssige kompleksitet som eksisterende metoder."
I fremtiden, the active reward-learning technique developed by this team of researchers could help to train robots more effectively, making them more attuned to user preferences. Ud over, it could be used to teach robots to ask questions that humans can easily understand and answer. In their future studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
"We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively."
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Næste generation af solceller yder bedre, når der er et kamera omkringPerovskite solceller badet i blåt lys, og reagerer i infrarødt. Kredit:Exciton Science Et bogstaveligt lysets trick kan opdage ufuldkommenheder i næste generations solceller, øge deres effektivite
Næste generation af solceller yder bedre, når der er et kamera omkringPerovskite solceller badet i blåt lys, og reagerer i infrarødt. Kredit:Exciton Science Et bogstaveligt lysets trick kan opdage ufuldkommenheder i næste generations solceller, øge deres effektivite -
 Ingeniører bygger mindste volumen, mest effektive trådløse nervestimulatorDen lille størrelse af StimDust kan ses i forhold til en skilling. Kredit:Rikky Muller I 2016 University of California, Berkeley, ingeniører demonstrerede den første implanterede, ultralyds neural
Ingeniører bygger mindste volumen, mest effektive trådløse nervestimulatorDen lille størrelse af StimDust kan ses i forhold til en skilling. Kredit:Rikky Muller I 2016 University of California, Berkeley, ingeniører demonstrerede den første implanterede, ultralyds neural -
 Selvflyvende svævefly lærer at svæve som en fuglGlideren svæver selvstændigt i marken. Kredit:Gautam Reddy og Jerome Wong-Ng Forskere har skabt et selvflyvende svævefly, der bruger maskinlæring til at navigere i stigende luftstrømme, i et ekspe
Selvflyvende svævefly lærer at svæve som en fuglGlideren svæver selvstændigt i marken. Kredit:Gautam Reddy og Jerome Wong-Ng Forskere har skabt et selvflyvende svævefly, der bruger maskinlæring til at navigere i stigende luftstrømme, i et ekspe -
 Ny metode gør ethvert 3D-objekt til en kubisk stilDataloger fra University of Toronto har udviklet en beregningsmetode til at kvantificere en abstrakt kubisk stil. Forskerne, Hsueh-Ti Derek Liu og Alec Jacobson fra University of Toronto, skal præsent
Ny metode gør ethvert 3D-objekt til en kubisk stilDataloger fra University of Toronto har udviklet en beregningsmetode til at kvantificere en abstrakt kubisk stil. Forskerne, Hsueh-Ti Derek Liu og Alec Jacobson fra University of Toronto, skal præsent
- Deepfakes rangeret som den mest alvorlige AI-kriminalitetstrussel
- Forskere opdager en nærliggende superjord
- Nyt madfrysningskoncept forbedrer kvaliteten, øger sikkerheden, reducerer energiforbruget
- Historiske oversvømmelser afslører, hvordan strandenge kan redde liv i fremtiden
- COVID-19-pandemien har øget ensomhed og andre sociale problemer, især for kvinder
- Hvad er dåse dåser lavet af?