


Nye algoritmer træner AI for at undgå specifik dårlig adfærd

Som robotter, selvkørende biler og andre intelligente maskiner væver AI ind i hverdagen, en ny måde at designe algoritmer på kan hjælpe maskinlæringsudviklere med at indbygge sikkerhedsforanstaltninger mod specifikke, uønskede resultater som race- og kønsbias. Kredit:Deboki Chakravarti
Kunstig intelligens er flyttet ind i den kommercielle mainstream takket være den voksende dygtighed af maskinlæringsalgoritmer, der gør det muligt for computere at træne sig selv til at gøre ting som at køre bil, styre robotter eller automatisere beslutningstagning.
Men efterhånden som AI begynder at håndtere følsomme opgaver, såsom at hjælpe med at vælge, hvilke fanger der får kaution, politiske beslutningstagere insisterer på, at dataloger tilbyder forsikringer om, at automatiserede systemer er designet til at minimere, hvis ikke helt undgå, uønskede udfald såsom overdreven risiko eller race- og kønsbias.
Et hold ledet af forskere ved Stanford og University of Massachusetts Amherst offentliggjorde et papir 22. november i Videnskab foreslå, hvordan man kan give sådanne forsikringer. Papiret skitserer en ny teknik, der oversætter et fuzzy mål, såsom at undgå kønsbias, ind i de præcise matematiske kriterier, der ville tillade en maskinlæringsalgoritme at træne en AI-applikation for at undgå den adfærd.
"Vi ønsker at fremme kunstig intelligens, der respekterer værdierne for sine menneskelige brugere og retfærdiggør den tillid, vi har til autonome systemer, sagde Emma Brunskill, en assisterende professor i datalogi ved Stanford og seniorforfatter af papiret.
Undgå dårlig opførsel
Arbejdet er baseret på den opfattelse, at hvis "usikre" eller "uretfærdige" udfald eller adfærd kan defineres matematisk, så burde det være muligt at lave algoritmer, der kan lære af data om, hvordan man undgår disse uønskede resultater med høj tillid. Forskerne ønskede også at udvikle et sæt teknikker, der ville gøre det nemt for brugerne at specificere, hvilken slags uønsket adfærd de ønsker at begrænse, og sætte maskinlæringsdesignere i stand til med tillid til at forudsige, at et system trænet ved hjælp af tidligere data kan stole på, når det anvendes under virkelige omstændigheder.
"Vi viser, hvordan designere af maskinlæringsalgoritmer kan gøre det lettere for folk, der ønsker at indbygge AI i deres produkter og tjenester, at beskrive uønskede resultater eller adfærd, som AI-systemet vil undgå med høj sandsynlighed, sagde Philip Thomas, en assisterende professor i datalogi ved University of Massachusetts Amherst og første forfatter af papiret.
Retfærdighed og sikkerhed
Forskerne testede deres tilgang ved at forsøge at forbedre retfærdigheden af algoritmer, der forudsiger GPA'er for universitetsstuderende baseret på eksamensresultater, en almindelig praksis, der kan resultere i kønsbias. Ved hjælp af et eksperimentelt datasæt, de gav deres algoritme matematiske instruktioner for at undgå at udvikle en prædiktiv metode, der systematisk overvurderede eller undervurderede GPA'er for ét køn. Med disse instruktioner, Algoritmen identificerede en bedre måde at forudsige studerendes GPA'er med meget mindre systematisk kønsbias end eksisterende metoder. Tidligere metoder kæmpede i denne henseende enten fordi de ikke havde noget retfærdighedsfilter indbygget, eller fordi algoritmer udviklet til at opnå retfærdighed var for begrænset i omfang.
Gruppen udviklede en anden algoritme og brugte den til at balancere sikkerhed og ydeevne i en automatiseret insulinpumpe. Sådanne pumper skal bestemme, hvor stor eller lille en dosis insulin der skal gives til en patient ved måltiderne. Ideelt set pumpen leverer lige nok insulin til at holde blodsukkerniveauet stabilt. For lidt insulin får blodsukkeret til at stige, fører til kortvarige gener såsom kvalme, og forhøjet risiko for langsigtede komplikationer, herunder hjerte-kar-sygdomme. For meget og blodsukkeret falder - et potentielt dødeligt udfald.
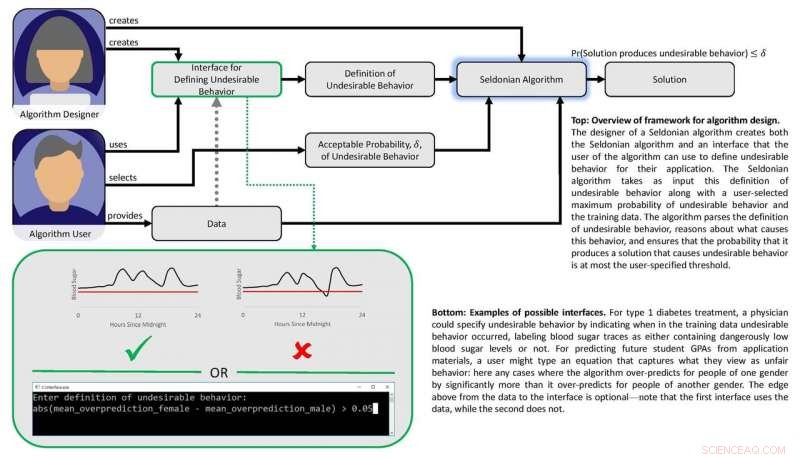
Diagram, der viser papirets ramme. Kredit:Philip Thomas
Maskinlæring kan hjælpe ved at identificere subtile mønstre i en persons blodsukkerrespons på doser, men eksisterende metoder gør det ikke nemt for læger at specificere resultater, som automatiserede doseringsalgoritmer bør undgå, som lavt blodsukkernedbrud. Ved hjælp af en blodsukkersimulator, Brunskill og Thomas viste, hvordan pumper kunne trænes til at identificere dosering, der er skræddersyet til den pågældende person – for at undgå komplikationer fra over- eller underdosering. Selvom gruppen ikke er klar til at teste denne algoritme på rigtige mennesker, det peger på en AI-tilgang, der i sidste ende kan forbedre livskvaliteten for diabetikere.
I deres Videnskab papir, Brunskill og Thomas bruger udtrykket "Seldonian algoritme" til at definere deres tilgang, en henvisning til Hari Seldon, en karakter opfundet af science fiction-forfatteren Isaac Asimov, der engang proklamerede tre love for robotteknologi, der begyndte med påbuddet om, at "En robot må ikke skade et menneske eller, gennem passivitet, tillade et menneske at komme til skade."
Mens jeg erkender, at feltet stadig er langt fra at garantere de tre love, Thomas sagde, at denne Seldonske ramme vil gøre det lettere for maskinlæringsdesignere at indbygge instruktioner til at undgå adfærd i alle mulige algoritmer, på en måde, der kan sætte dem i stand til at vurdere sandsynligheden for, at trænede systemer vil fungere korrekt i den virkelige verden.
Brunskill sagde, at denne foreslåede ramme bygger på den indsats, som mange dataloger gør for at finde en balance mellem at skabe kraftfulde algoritmer og udvikle metoder til at sikre, at deres troværdighed.
"At tænke på, hvordan vi kan skabe algoritmer, der bedst respekterer værdier som sikkerhed og retfærdighed, er afgørende, da samfundet i stigende grad stoler på AI, " sagde Brunskill.
 Varme artikler
Varme artikler
-
 Motorola foldbar dominerer patentsnakken som et friskere comebackKredit:patentansøgning Historier og snak hvisker foldbare side om side med navnet Motorola, i ringe grad ejer til den seneste historie i Wall Street Journal og, efter det, spotting af en patenta
Motorola foldbar dominerer patentsnakken som et friskere comebackKredit:patentansøgning Historier og snak hvisker foldbare side om side med navnet Motorola, i ringe grad ejer til den seneste historie i Wall Street Journal og, efter det, spotting af en patenta -
 Nyt AI-system efterligner, hvordan mennesker visualiserer og identificerer objekterEt computersyn -system udviklet på UCLA kan identificere objekter baseret på kun delvise glimt, som ved at bruge disse fotofremvisninger af en motorcykel. Kredit:University of California, Los Angeles
Nyt AI-system efterligner, hvordan mennesker visualiserer og identificerer objekterEt computersyn -system udviklet på UCLA kan identificere objekter baseret på kun delvise glimt, som ved at bruge disse fotofremvisninger af en motorcykel. Kredit:University of California, Los Angeles -
 Air France-KLM får løft fra medarbejdernes aftaleAir France-KLM rapporterede et stærkt tredje kvartal, komme sig efter lammende strejker tidligere på året Air France-KLM, tidligere i år hårdt ramt af strejker og ledelsesomvæltninger, rapportered
Air France-KLM får løft fra medarbejdernes aftaleAir France-KLM rapporterede et stærkt tredje kvartal, komme sig efter lammende strejker tidligere på året Air France-KLM, tidligere i år hårdt ramt af strejker og ledelsesomvæltninger, rapportered -
 Forsøger du at bestille dagligvarer online? Nogle tips til at gøre det med succesKredit:CC0 Public Domain Hvis du har prøvet at bestille dagligvarer til levering i denne uge, det er ikke dig. I en corona-æra, de gamle regler og forventninger er smidt ud af vinduet. At få leve
Forsøger du at bestille dagligvarer online? Nogle tips til at gøre det med succesKredit:CC0 Public Domain Hvis du har prøvet at bestille dagligvarer til levering i denne uge, det er ikke dig. I en corona-æra, de gamle regler og forventninger er smidt ud af vinduet. At få leve
- Sådan beregnes omkretsen af firkantede sider
- Er den kosmiske kolos RCS2J2327 tungere end tilladt?
- Rapport viser mangfoldighed på diagrammerne, men ikke i ledende rækker af musikselskaber
- Nye rammer til håndtering af usikkerhed inden for vandforvaltning
- Rørformede solceller kunne væves ind i tøj
- Mikrober, der lever på luft et globalt fænomen