


AI-læringsteknik kan illustrere funktionen af belønningsveje i hjernen

Når fremtiden er usikker, fremtidig belønning kan repræsenteres som en sandsynlighedsfordeling. nogle mulige fremtider er gode (grøngrøn), andre er dårlige (røde). Fordelingsforstærkningslæring kan lære om denne fordeling over forudsagte belønninger gennem en variant af TD-algoritmen. Kredit: Natur (2020). DOI:10.1038/s41586-019-1924-6
Et team af forskere fra DeepMind, University College og Harvard University har fundet ud af, at erfaringer med at anvende læringsteknikker til AI-systemer kan hjælpe med at forklare, hvordan belønningsveje fungerer i hjernen. I deres papir offentliggjort i tidsskriftet Natur , gruppen beskriver sammenligning af distributionsmæssig forstærkningslæring i en computer med dopaminbehandling i musehjernen, og hvad de lærte af det.
Tidligere forskning har vist, at dopamin produceret i hjernen er involveret i belønningsbehandling - det produceres når noget godt sker, og dets udtryk resulterer i følelser af nydelse. Nogle undersøgelser har også antydet, at neuronerne i hjernen, der reagerer på tilstedeværelsen af dopamin, alle reagerer på samme måde - en begivenhed får en person eller en mus til at føle sig enten god eller dårlig. Andre undersøgelser har antydet, at neuronal respons er mere en gradient. I denne nye indsats, forskerne har fundet beviser, der understøtter sidstnævnte teori.
Distributionel forstærkningslæring er en type maskinlæring baseret på forstærkning. Det bruges ofte, når man designer spil som Starcraft II eller Go. Den holder styr på gode træk kontra dårlige træk og lærer at reducere antallet af dårlige træk, forbedrer dens ydeevne, jo mere den spiller. Men sådanne systemer behandler ikke alle gode og dårlige træk ens – hvert træk vægtes, efterhånden som det er registreret, og vægtene er en del af de beregninger, der bruges, når du foretager fremtidige trækvalg.
Forskere har bemærket, at mennesker ser ud til at bruge en lignende strategi til at forbedre deres spilleniveau, såvel. Forskerne i London havde mistanke om, at lighederne mellem AI-systemerne og den måde, hjernen udfører belønningsbehandling på, sandsynligvis var ens, såvel. For at finde ud af, om de var korrekte, de udførte forsøg med mus. De indsatte enheder i deres hjerner, der var i stand til at optage reaktioner fra individuelle dopaminneuroner. Musene blev derefter trænet til at udføre en opgave, hvor de modtog belønninger for at reagere på en ønsket måde.
Museneuron-reaktionerne afslørede, at de ikke alle reagerede på samme måde, som tidligere teori havde forudsagt. I stedet, de reagerede på pålidelige forskellige måder - en indikation af, at niveauet af nydelse, som musene oplevede, var mere en gradient, som holdet havde forudsagt.
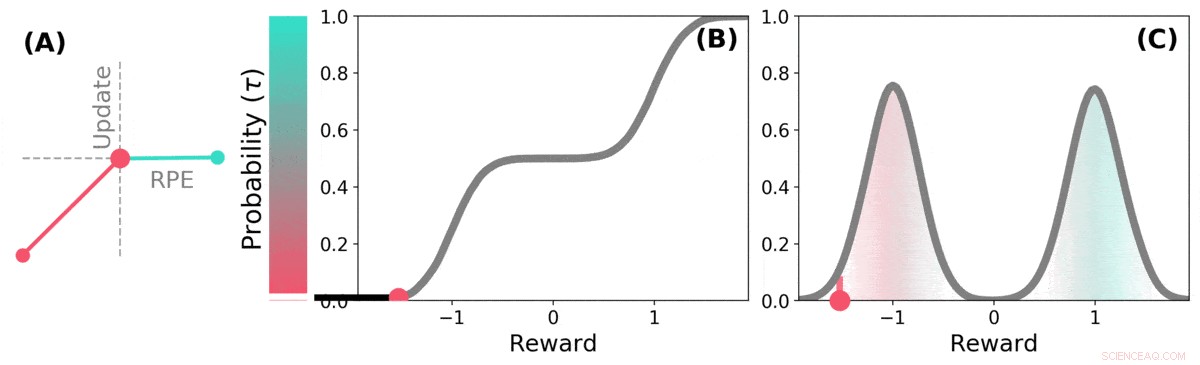
Distributions-TD lærer værdiestimater for mange forskellige dele af fordelingen af belønninger. hvilken del et bestemt estimat dækker, bestemmes af typen af asymmetrisk opdatering, der anvendes på det estimat. (a) En "pessimistisk" celle ville forstærke negative opdateringer og ignorere positive opdateringer, en 'optimistisk' celle ville forstærke positive opdateringer og ignorere negative opdateringer. (b) Dette resulterer i en mangfoldighed af pessimistiske eller optimistiske værdiestimater, vist her som point langs den kumulative fordeling af belønninger, der fanger (c) Den fulde fordeling af belønninger. Kredit: Natur (2020). DOI:10.1038/s41586-019-1924-6
© 2020 Science X Network
 Varme artikler
Varme artikler
-
 Coronavirus-pandemien har udløst en bølge af cyberangreb:Sådan beskytter du dig selvKredit:ét foto/Shutterstock Mens det meste af verden forsøger at håndtere COVID-19-pandemien, Det ser ud til, at hackere ikke er låst. Cyberkriminelle forsøger at udnytte nødsituationen ved at uds
Coronavirus-pandemien har udløst en bølge af cyberangreb:Sådan beskytter du dig selvKredit:ét foto/Shutterstock Mens det meste af verden forsøger at håndtere COVID-19-pandemien, Det ser ud til, at hackere ikke er låst. Cyberkriminelle forsøger at udnytte nødsituationen ved at uds -
 Boeing annoncerer nye MAX-ordrer, efterhånden som grundstødningskrisen trækker udDen urolige amerikanske flyproducent Boeing har vundet et nyt løft på Dubai Air Show med en hensigtserklæring fra det kasakhiske flag luftfartsselskab Air Astana om at købe 30 af deres 737 MAX-8 model
Boeing annoncerer nye MAX-ordrer, efterhånden som grundstødningskrisen trækker udDen urolige amerikanske flyproducent Boeing har vundet et nyt løft på Dubai Air Show med en hensigtserklæring fra det kasakhiske flag luftfartsselskab Air Astana om at købe 30 af deres 737 MAX-8 model -
 Airbus A380:Fra højteknologisk vidunder til kommercielt flopDe endelige leverancer af A380 forventes i 2021. Kredit:Mike Fuchslocher/Shutterstock Denne gang er det virkelig slut. Airbus administrerende direktør, Tom Enders, annoncerede for nylig slutningen
Airbus A380:Fra højteknologisk vidunder til kommercielt flopDe endelige leverancer af A380 forventes i 2021. Kredit:Mike Fuchslocher/Shutterstock Denne gang er det virkelig slut. Airbus administrerende direktør, Tom Enders, annoncerede for nylig slutningen -
 Fødevareteknologi går fra månen til købmandsgangen, forbedring af fødevareproduktion og kvalite…Kredit:CC0 Public Domain Teknologi, der oprindeligt blev udviklet i samarbejde med NASA for at hjælpe månekolonier, kan snart opvarme maden, der findes på mange feriemiddagsborde. Purdue Universi
Fødevareteknologi går fra månen til købmandsgangen, forbedring af fødevareproduktion og kvalite…Kredit:CC0 Public Domain Teknologi, der oprindeligt blev udviklet i samarbejde med NASA for at hjælpe månekolonier, kan snart opvarme maden, der findes på mange feriemiddagsborde. Purdue Universi
- Facebook udvider faktatjekindsatsen til fotos, videoer
- Honeywell hævder at have bygget den kvantecomputer, der har den bedst ydelse
- Forskere finder en billigere måde at oplyse OLED-skærme på
- Stigende CO2 forårsager mere end en klimakrise – det kan direkte skade vores evne til at tænke
- Jordforskere bruger mineaffald til at genoprette menneskeskabte ødemarker
- Newtons Principia blandt poster i påstået $ 8M bogordning