


Smartphone-videoer producerer yderst realistiske 3D-ansigtsrekonstruktioner
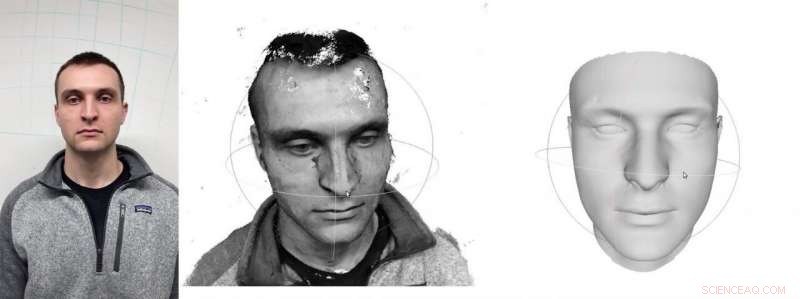
I en 3-D ansigtsrekonstruktionsproces udviklet på Carnegie Mellon University, smartphone video af en person, venstre, analyseres for at producere en ufuldkommen model af ansigtet, midten. Dyb læring kombineres derefter med konventionelle computervisionsteknikker for at fuldende rekonstruktionen, ret. Kredit:Carnegie Mellon University
Normalt, det kræver dyrt udstyr og ekspertise at skabe en nøjagtig 3D-rekonstruktion af en persons ansigt, der er realistisk og ikke ser uhyggelig ud. Nu, Forskere fra Carnegie Mellon University har udført bedriften ved at bruge video optaget på en almindelig smartphone.
Brug af en smartphone til at optage en kontinuerlig video af fronten og siderne af ansigtet genererer en tæt sky af data. En to-trins proces udviklet af CMU's Robotics Institute bruger disse data, med lidt hjælp fra deep learning algoritmer, at bygge en digital rekonstruktion af ansigtet. Holdets eksperimenter viser, at deres metode kan opnå sub-millimeter nøjagtighed, udkonkurrerer andre kamerabaserede processer.
Et digitalt ansigt kan bruges til at bygge en avatar til spil eller til virtual eller augmented reality, og kan også bruges i animation, biometrisk identifikation og endda medicinske procedurer. En nøjagtig 3D-gengivelse af ansigtet kan også være nyttig til at bygge skræddersyede kirurgiske masker eller åndedrætsværn.
"At bygge en 3D-rekonstruktion af ansigtet har været et åbent problem inden for computersyn og grafik, fordi folk er meget følsomme over for udseendet af ansigtstræk, " sagde Simon Lucey, en lektor i Robotics Institute. "Selv små anomalier i rekonstruktionerne kan få slutresultatet til at se urealistisk ud."
Laser scannere, struktureret lys og multikamera studieopsætninger kan producere meget nøjagtige scanninger af ansigtet, men disse specialiserede sensorer er uoverkommeligt dyre til de fleste applikationer. CMUs nyudviklede metode, imidlertid, kræver kun en smartphone.
Metoden, som Lucey udviklede med masterstuderende Shubham Agrawal og Anuj Pahuja, blev præsenteret i begyndelsen af marts på IEEE Winter Conference on Applications of Computer Vision (WACV) i Snowmass, Colorado. Det begynder med at optage 15-20 sekunders video. I dette tilfælde, forskerne brugte en iPhone X i slowmotion-indstillingen.
"Den høje billedhastighed af slowmotion er en af de vigtigste ting for vores metode, fordi den genererer en tæt punktsky, " sagde Lucey.
Forskerne anvender derefter en almindeligt brugt teknik kaldet visuel simultan lokalisering og kortlægning (SLAM). Visual SLAM triangulerer punkter på en overflade for at beregne dens form, samtidig med at du bruger disse oplysninger til at bestemme kameraets position. Dette skaber en indledende geometri af ansigtet, men manglende data efterlader huller i modellen.
I det andet trin af denne proces, forskerne arbejder på at udfylde disse huller, først ved at bruge deep learning algoritmer. Deep learning bruges på en begrænset måde, dog:det identificerer personens profil og vartegn, såsom ører, øjne og næse. Derefter bruges klassiske computersynsteknikker til at udfylde hullerne.
"Deep learning er et kraftfuldt værktøj, som vi bruger hver dag, " sagde Lucey. "Men deep learning har en tendens til at huske løsninger udenad, ", som modarbejder bestræbelser på at inkludere skelnende detaljer i ansigtet. "Hvis du bruger disse algoritmer bare for at finde vartegnene, du kan bruge klassiske metoder til at udfylde hullerne meget lettere."
Metoden er ikke nødvendigvis hurtig; det tog 30-40 minutters behandlingstid. Men hele processen kan udføres på en smartphone.
Ud over ansigtsrekonstruktioner, CMU-teamets metoder kan også bruges til at fange geometrien af næsten ethvert objekt, sagde Lucey. Digitale rekonstruktioner af disse objekter kan derefter inkorporeres i animationer eller måske overføres på tværs af internettet til websteder, hvor objekterne kan duplikeres med 3-D-printere.
Sidste artikelUvis klimafremtid kan forstyrre energisystemerne
Næste artikelGoogle træner chips til at designe sig selv
 Varme artikler
Varme artikler
-
 Efter årtier i udvikling, Hondas jetfly udvikler sig stille og roligtDenne 30. juli, 2019 viser et HondaJet Elite-fly i produktion i Honda Aircraft Co.s hovedkvarter i Greensboro, N.C. Næsten fire år efter at have leveret sit første jetfly, Honda står over for beslutni
Efter årtier i udvikling, Hondas jetfly udvikler sig stille og roligtDenne 30. juli, 2019 viser et HondaJet Elite-fly i produktion i Honda Aircraft Co.s hovedkvarter i Greensboro, N.C. Næsten fire år efter at have leveret sit første jetfly, Honda står over for beslutni -
 Shanghai får automatiseret bank med VR, robotter, ansigtsscanningI denne 13. april, 2018, Foto, bankkunder taler med en robot i en automatiseret filial i Shanghai. Outlet åbnet af Beijing-baserede China Construction Bank er blevet døbt Kinas første ubemandede bank
Shanghai får automatiseret bank med VR, robotter, ansigtsscanningI denne 13. april, 2018, Foto, bankkunder taler med en robot i en automatiseret filial i Shanghai. Outlet åbnet af Beijing-baserede China Construction Bank er blevet døbt Kinas første ubemandede bank -
 Blod og sved tager træningsappen til næste niveauArmbåndet måler dit blod og sved og sender informationen til en træningsapp. Kredit:KTH Det Kongelige Teknologiske Institut Sidste år omkring 1, 000 løbere blev tvunget til at forlade Stockholm Ma
Blod og sved tager træningsappen til næste niveauArmbåndet måler dit blod og sved og sender informationen til en træningsapp. Kredit:KTH Det Kongelige Teknologiske Institut Sidste år omkring 1, 000 løbere blev tvunget til at forlade Stockholm Ma -
 Mennesker og AI slår sig sammen for at forbedre clickbait-detektionKredit:CC0 Public Domain Mennesker og maskiner arbejdede sammen for at hjælpe med at træne en kunstig intelligens-AI-model, der udkonkurrerede andre clickbait-detektorer, ifølge forskere ved Penn
Mennesker og AI slår sig sammen for at forbedre clickbait-detektionKredit:CC0 Public Domain Mennesker og maskiner arbejdede sammen for at hjælpe med at træne en kunstig intelligens-AI-model, der udkonkurrerede andre clickbait-detektorer, ifølge forskere ved Penn
- Fjernelse af gamle strukturer fra floder kunne genoprette vital vandstrøm
- Ny opdagelse hjælper myndighederne med at identificere heroinets oprindelse
- Keck Observatory planet imager leverer første videnskab
- HP Labs finder memristorer kan beregne (med video)
- Hvilken rolle spiller dommerne i sager om chikane om beskæftigelse?
- Lunar sample fortæller gammel historie gennem internationalt samarbejde