


Alphabets DeepMind mestrer Atari-spil
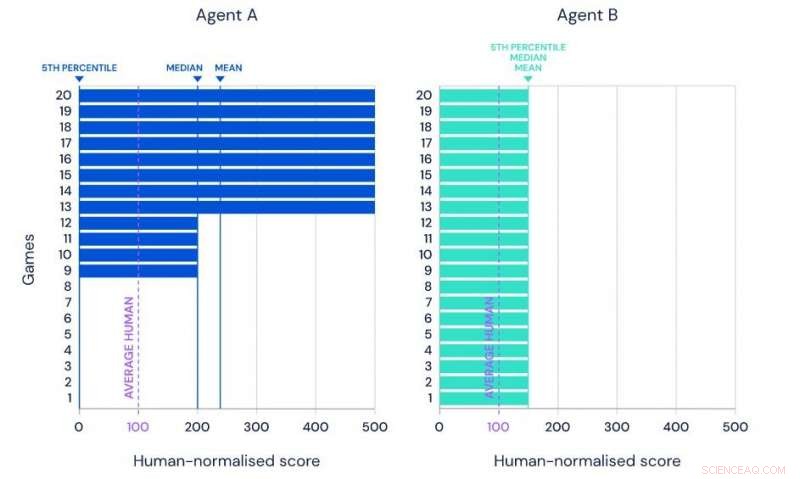
Illustration af middelværdien, median og 5. percentil præstation af to hypotetiske agenter på det samme benchmarksæt på 20 opgaver. Kredit:Google
For bedre at kunne løse komplekse udfordringer i begyndelsen af det tredje årti af det 21. århundrede, Alphabet Inc. har udnyttet relikvier fra 1980'erne:videospil.
Googles moderselskab rapporterede i denne uge, at dets DeepMind Technologies Artificial Intelligence-enhed med succes har lært at spille 57 Atari-videospil. Og computersystemet spiller bedre end noget menneske.
Atari, skaberen af Pong, et af de første succesrige videospil i 1970'erne, fortsatte med at popularisere mange af de store tidlige klassiske videospil ind i 1990'erne. Videospil bruges ofte sammen med AI-projekter, fordi de udfordrer algoritmer til at navigere mere og mere komplekse stier og muligheder, alt imens du møder skiftende scenarier, trusler og belønninger.
Kaldt AGENT57, Alphabets AI-system undersøgte 57 førende Atari-spil, der dækkede et stort udvalg af sværhedsgrader og forskellige successtrategier.
"Spil er en fremragende testplads til at bygge adaptive algoritmer, " sagde forskerne i en rapport på DeepMind-blogsiden. "De giver en rig række af opgaver, som spillere skal udvikle sofistikerede adfærdsstrategier for at mestre, men de giver også en let fremskridtsmåling — spilscore — at optimere imod.
"Det ultimative mål er ikke at udvikle systemer, der udmærker sig i spil, men snarere at bruge spil som et springbræt til at udvikle systemer, der lærer at udmærke sig ved en bred række udfordringer, " sagde rapporten.
DeepMinds AlphaGo-system fik bred anerkendelse i 2016, da det slog verdensmesteren Lee Sedol i det strategiske spil Go.
Blandt den nuværende høst af 57 Atari-spil, fire anses for at være særligt vanskelige for AI-projekter at mestre:Montezuma's Revenge, faldgrube, Solaris og skiløb. De første to spil udgør, hvad DeepMind kalder det forvirrende "udforskning-udnyttelsesproblem."
"Skal man blive ved med at udføre adfærd, man ved virker (udnytte), eller skal man prøve noget nyt (udforske) for at opdage nye strategier, der kan være endnu mere succesfulde?" spørger DeepMind. "F.eks. skal man altid bestille deres samme yndlingsret på en lokal restaurant, eller prøve noget nyt, der måske overgår den gamle favorit? Udforskning involverer at tage mange suboptimale handlinger for at indsamle den information, der er nødvendig for at opdage en i sidste ende stærkere adfærd."
De to andre udfordrende spil pålægger lange ventetider mellem udfordringer og belønninger, gør det sværere for AI-systemer at analysere succesfuldt.
Tidligere bestræbelser på at mestre de fire spil med AI mislykkedes alle.
Rapporten siger, at der stadig er plads til forbedringer. For en, lange beregningstider er fortsat et problem. Også, mens han erkender, at "jo længere den trænede, jo højere dens score blev, "DeepMind-forskere ønsker, at Agent57 skal gøre det bedre. De vil have det til at mestre flere spil samtidigt; pt. det kan kun lære et spil ad gangen, og det skal gennemgå træning, hver gang det genstarter et spil.
Ultimativt, DeepMind-forskere forudser et program, der kan anvende menneskelignende beslutningstagningsvalg, mens de møder stadigt skiftende og hidtil usete udfordringer.
"Ægte alsidighed, som kommer så let til et menneskeligt spædbarn, er stadig langt uden for AI'ers rækkevidde, " konkluderede rapporten.
© 2020 Science X Network
 Varme artikler
Varme artikler
-
 NTSB:Autopiloten var i brug, før Tesla ramte sættevognenDenne 3. okt. 2018, filbillede viser logoet for Tesla model 3 på biludstillingen i Paris. National Transportation Safety Board siger, at Teslas semiautonome autopilot-køresystem var i brug, da en af
NTSB:Autopiloten var i brug, før Tesla ramte sættevognenDenne 3. okt. 2018, filbillede viser logoet for Tesla model 3 på biludstillingen i Paris. National Transportation Safety Board siger, at Teslas semiautonome autopilot-køresystem var i brug, da en af -
 Simulering for nettransmission, fordelingI Californien, forsyningsselskaber har mandat til at få mindst halvdelen af deres strøm fra vedvarende ressourcer, som sol og vind, i 2030. Kredit:Lawrence Livermore National Laboratory Vedvaren
Simulering for nettransmission, fordelingI Californien, forsyningsselskaber har mandat til at få mindst halvdelen af deres strøm fra vedvarende ressourcer, som sol og vind, i 2030. Kredit:Lawrence Livermore National Laboratory Vedvaren -
 Hvordan forbundethed kan fremme kompleks dynamik på tværs af forskellige netværkTanken bag denne undersøgelse er, at i et netværk arrangeret med en given arkitektur (f.eks. et stjernenetværk) og under passende forhold, knudepunkterne, der har det største antal forbindelser (øvers
Hvordan forbundethed kan fremme kompleks dynamik på tværs af forskellige netværkTanken bag denne undersøgelse er, at i et netværk arrangeret med en given arkitektur (f.eks. et stjernenetværk) og under passende forhold, knudepunkterne, der har det største antal forbindelser (øvers -
 USA undersøger Kia, Hyundai over ikke-ulykkesbrandeNæsten tre millioner køretøjer fra de to producenter kunne tilbagekaldes efter undersøgelser, der begyndte den 29. marts, herunder 1,7 millioner Kiaer og 1,3 millioner Hyundaier Amerikanske myndig
USA undersøger Kia, Hyundai over ikke-ulykkesbrandeNæsten tre millioner køretøjer fra de to producenter kunne tilbagekaldes efter undersøgelser, der begyndte den 29. marts, herunder 1,7 millioner Kiaer og 1,3 millioner Hyundaier Amerikanske myndig
- De mærkelige storme på Jupiter
- Hvor skal fremtidige astronauter lande på Mars? Følg vandet
- Hård cider, med en sjat sukker
- Ny lydproduktionsteknologi forbedrer brugeroplevelsen af broadcast-indhold
- Ny undersøgelse skitserer, hvordan arbejde hjemmefra kunne tilpasse sig for at fortsætte effektivt
- NATO-forskere:Sociale medier formår ikke at stoppe manipulation