


Skalerbar og fuldt koblet kvante-inspireret processor løser optimeringsproblemer

I et nyt studie har forskere fra TUS, Japan, foreslået en fuldt tilsluttet skalerbar annealing-processor, der, når den implementeres i FPGA, nemt kan udkonkurrere en moderne CPU i løsning af forskellige kombinatoriske optimeringsproblemer med hensyn til hastighed og energiforbrug. Den foreslåede metode opnår dette ved at bruge en "array-beregner", der består af flere koblede chips og en "kontrolchip". Det kunne anvendes til at løse lignende komplekse optimeringsproblemer inden for logistik, netværksrouting, lagerstyring, personaletildeling, lægemiddellevering og materialevidenskab. Kredit:Takayuki Kawahara fra TUS, Japan
Har du nogensinde stået med et problem, hvor du skulle finde en optimal løsning ud af mange mulige muligheder, såsom at finde den hurtigste rute til et bestemt sted, både med tanke på afstand og trafik?
Hvis det er tilfældet, er det problem, du havde at gøre med, det, der formelt er kendt som et "kombinatorisk optimeringsproblem." Selvom de er matematisk formulerede, er disse problemer almindelige i den virkelige verden og dukker op på tværs af flere områder, herunder logistik, netværksrouting, maskinlæring og materialevidenskab.
Imidlertid er store kombinatoriske optimeringsproblemer meget beregningsintensive at løse ved hjælp af standardcomputere, hvilket får forskere til at vende sig til andre tilgange. En sådan tilgang er baseret på "Ising-modellen", som matematisk repræsenterer den magnetiske orientering af atomer eller "spin" i et ferromagnetisk materiale.
Ved høje temperaturer er disse atomare spins orienteret tilfældigt. Men efterhånden som temperaturen falder, stiller spinsene op for at nå den minimale energitilstand, hvor orienteringen af hvert spin afhænger af dens naboer. Det viser sig, at denne proces, kendt som "annealing", kan bruges til at modellere kombinatoriske optimeringsproblemer, således at den endelige tilstand af spins giver den optimale løsning.
I et nyt studie har forskere fra TUS, Japan, foreslået en fuldt tilsluttet skalerbar annealing-processor, der, når den implementeres i FPGA, nemt kan udkonkurrere en moderne CPU i løsning af forskellige kombinatoriske optimeringsproblemer med hensyn til hastighed og energiforbrug. Den foreslåede metode opnår dette ved at bruge en "array-beregner", der består af flere koblede chips og en "kontrolchip". Det kunne anvendes til at løse lignende komplekse optimeringsproblemer inden for logistik, netværksrouting, lagerstyring, personaletildeling, lægemiddellevering og materialevidenskab. Kredit:Takayuki Kawahara fra TUS, Japan
Forskere har forsøgt at skabe annealing-processorer, der efterligner opførslen af spins ved hjælp af kvanteenheder, og har forsøgt at udvikle halvlederenheder ved hjælp af storskala-integration (LSI) teknologi med det formål at gøre det samme. Især professor Takayuki Kawaharas forskningsgruppe ved Tokyo University of Science (TUS) i Japan har gjort vigtige gennembrud på netop dette område.
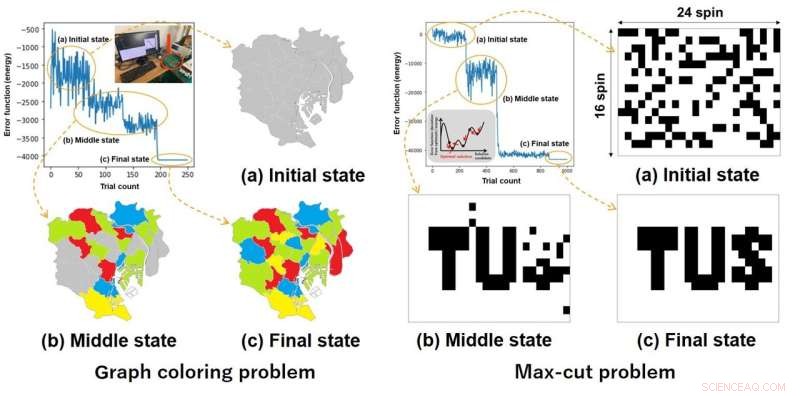
I 2020 præsenterede prof. Kawahara og hans kolleger på den internationale konference i 2020, IEEE SAMI 2020, en af de første fuldt koblede (det vil sige, der tager højde for alle mulige spin-spin-interaktioner i stedet for interaktioner med kun nabo-spins) LSI-annealing-processorer, bestående af 512 fuldt forbundne spins.
Deres arbejde udkom i tidsskriftet IEEE Transactions on Circuits and Systems I:Regular Papers . Disse systemer er notorisk svære at implementere og opskalere på grund af det store antal forbindelser mellem spins, der skal overvejes. Mens brug af flere fuldt tilsluttede chips parallelt var en potentiel løsning på skalerbarhedsproblemet, gjorde dette det nødvendige antal sammenkoblinger (ledninger) mellem chips uoverkommeligt stort.
I en nylig undersøgelse offentliggjort i Microprocessors and Microsystems , Prof. Kawahara og hans kollega demonstrerede en smart løsning på dette problem. De udviklede en ny metode, hvor beregningen af systemets energitilstand først deles mellem flere fuldt koblede chips og danner en "array-beregner".
En anden type chip, kaldet "kontrolchip", indsamler derefter resultaterne fra resten af chipsene og beregner den samlede energi, som bruges til at opdatere værdierne af de simulerede spins. "Fordelen ved vores tilgang er, at mængden af data, der transmitteres mellem chipsene, er ekstremt lille," forklarer prof. Kawahara. "Selvom dens princip er enkelt, giver denne metode os mulighed for at realisere et skalerbart, fuldt tilsluttet LSI-system til løsning af kombinatoriske optimeringsproblemer gennem simuleret udglødning."
Forskerne implementerede med succes deres tilgang ved hjælp af kommercielle FPGA-chips, som er meget udbredte programmerbare halvlederenheder. De byggede et fuldt tilsluttet udglødningssystem med 384 spins og brugte det til at løse adskillige optimeringsproblemer, herunder et 92-node graffarveproblem og et 384-node maksimum cut-problem.
Vigtigst af alt viste disse proof-of-concept-eksperimenter, at den foreslåede metode bringer sande præstationsfordele. Sammenlignet med en standard, moderne CPU, der modellerer det samme annealing-system, var FPGA-implementeringen 584 gange hurtigere og 46 gange mere energieffektiv, når man løste det maksimale cut-problem.
Nu, med denne succesfulde demonstration af driftsprincippet for deres metode i FPGA, planlægger forskerne at tage det til næste niveau. "Vi ønsker at producere en specialdesignet LSI-chip for at øge kapaciteten og i høj grad forbedre ydeevnen og strømeffektiviteten af vores metode," siger prof. Kawahara. "Dette vil gøre os i stand til at realisere den præstation, der kræves inden for materialeudvikling og lægemiddelopdagelse, som involverer meget komplekse optimeringsproblemer."
Endelig bemærker prof. Kawahara, at han ønsker at fremme implementeringen af deres resultater for at løse reelle problemer i samfundet. Hans gruppe håber at engagere sig i fælles forskning med virksomheder og bringe deres tilgang til kernen af halvlederdesignteknologi, hvilket åbner døre til genoplivningen af halvledere i Japan. + Udforsk yderligere
En ny processor, der løser notorisk komplekse matematiske problemer
 Varme artikler
Varme artikler
-
 Innovativ metode fører til mindre, billigere IoT-sensorerNUS-forskere opfandt en lavpris batteriløs opvågningstimer, der reducerer strømforbruget for IoT-sensorknuder med 1, 000 gange, bidrager til langvarig drift. Wake-up timeren er indlejret i en testchip
Innovativ metode fører til mindre, billigere IoT-sensorerNUS-forskere opfandt en lavpris batteriløs opvågningstimer, der reducerer strømforbruget for IoT-sensorknuder med 1, 000 gange, bidrager til langvarig drift. Wake-up timeren er indlejret i en testchip -
 Teslas næste store ting:Kan det være med Apple?Hvis Tesla-administrerende direktør Elon Musk troede, at en stopper for hans plan om at tage elbilproducenten privat ville berolige al den opmærksomhed, Tesla havde fået om sin fremtid, han burde tænk
Teslas næste store ting:Kan det være med Apple?Hvis Tesla-administrerende direktør Elon Musk troede, at en stopper for hans plan om at tage elbilproducenten privat ville berolige al den opmærksomhed, Tesla havde fået om sin fremtid, han burde tænk -
 Amerikaneren forventer, at 350 millioner dollars vil blive ramt af et jordforbundet Boeing -flyI denne 13. marts, 2019, filfoto en medarbejder går forbi en motor på et Boeing 737 MAX 8 -fly, der bygges til American Airlines hos Boeing Cos American Airlines forventer at få et hit på 1 milliard d
Amerikaneren forventer, at 350 millioner dollars vil blive ramt af et jordforbundet Boeing -flyI denne 13. marts, 2019, filfoto en medarbejder går forbi en motor på et Boeing 737 MAX 8 -fly, der bygges til American Airlines hos Boeing Cos American Airlines forventer at få et hit på 1 milliard d -
 Airbus overskud stiger, mens rivalen Boeing snublerAirbus leverede 389 kommercielle fly i løbet af første halvår, op fra 303 i samme periode i 2018 Den europæiske flyproducent Airbus leverede onsdag robuste halvårsoverskud på stærk efterspørgsel f
Airbus overskud stiger, mens rivalen Boeing snublerAirbus leverede 389 kommercielle fly i løbet af første halvår, op fra 303 i samme periode i 2018 Den europæiske flyproducent Airbus leverede onsdag robuste halvårsoverskud på stærk efterspørgsel f
- En nm tyk grafenmotor efterligner totaktsmotor
- Osmoseforsøg med kartofler til børn
- Satellitter til at spore tog og fremme jernbanesikkerheden
- Skæring af nanopartikler ned til størrelse
- Magnetisk kontrollerede nanopartikler forbedrer slagtilfældebehandling
- Metasurface-teknologi kunne fremme jordvidenskaben fra kredsløb