


Det første open source-datasæt til maskinlæringsapplikationer i hurtigt chipdesign

Eksempel på makroplaceringsalgoritmen foreslået af Google. Kredit:Science China Press
Electronic design automation (EDA) eller computer-aided design (CAD) er en kategori af softwareværktøjer til design af elektroniske systemer, såsom integrerede kredsløb (IC'er). Med EDA-værktøjer kan designere afslutte designflowet af integrerede (VLSI)-chips i meget stor skala med milliarder af transistorer. EDA-værktøjer er afgørende for moderne VLSI-design på grund af den store skala og høje kompleksitet af elektroniske systemer.
For nylig, med boomet af kunstig intelligens (AI) algoritmer, udforsker EDA-fællesskabet aktivt AI for IC-teknikker til design af avancerede chips. Mange undersøgelser har udforsket maskinlæring (ML)-baserede teknikker til forudsigelsesopgaver på tværs af stadier i designflowet for at opnå hurtigere designkonvergens. For eksempel udgav Google en artikel i Nature i 2021 med titlen "En grafplaceringsmetodologi til hurtigt chipdesign", der udnytter forstærkningslæring (RL) til at placere makroer i et chipdesign.
Den grundlæggende idé er at betragte chip-layoutet som et Go-bræt, mens hver makro er en sten. På denne måde kan en RL-agent på forhånd trænes med 10.000 interne designprøver og lære at placere én makro ad gangen. Ved at finjustere agenten på hvert design i omkring 6 timer kan den overgå ydeevnen af konventionelle EDA-værktøjer på Googles TPU-chips og opnå bedre ydeevne, kraft og areal (PPA).
Det kan ses, at "AI for EDA" bliver aktivt udforsket i designautomatiseringsfællesskabet. Selvom opbygning af ML-modeller normalt kræver en stor mængde data, kan de fleste undersøgelser kun generere små interne datasæt til validering, på grund af manglen på store offentlige datasæt og vanskeligheden ved datagenerering. Til dette formål er et open source-datasæt dedikeret til ML-opgaver i EDA påtrængende ønsket.
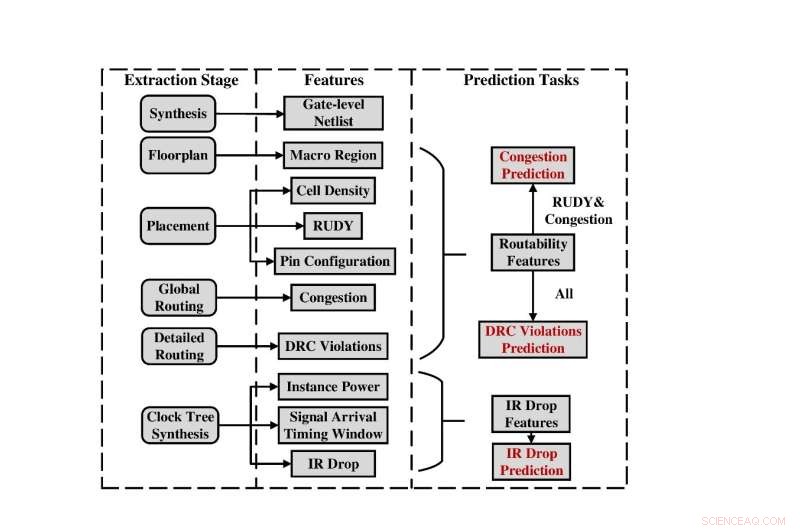
Samlet flow til dataindsamling og udtræk af funktioner. Kredit:Science China Press
For at løse dette problem har forskningsgruppen fra Peking University udgivet det første open source-datasæt, kaldet CircuitNet, som er dedikeret til AI til IC-applikationer i VLSI CAD. Datasættet består af over 10.000 prøver og 54 syntetiserede kredsløbsnetlister fra seks open source RISC-V-designs, giver holistisk støtte til forudsigelsesopgaver på tværs af stadier og understøtter opgaver, herunder forudsigelse af ruteoverbelastning, forudsigelse af overtrædelse af designregelkontrol (DRC) og IR fald forudsigelse. De vigtigste egenskaber ved CircuitNet kan opsummeres som følger:
- Stor skala:Datasættet består af mere end 10.000 prøver udtrukket fra alsidige kørsler af kommercielle EDA-værktøjer med kommercielle PDK'er (i øjeblikket i 28nm teknologiknude, og vil snart understøtte 14nm teknologi).
- Diversitet:Forskellige indstillinger i logisk syntese og fysisk design introduceres for at afspejle forskellige situationer i designflowet.
- Flere opgaver:Datasættet understøtter tre forudsigelsesopgaver, dvs. forudsigelse af overbelastning, forudsigelse af DRC-overtrædelse og forudsigelse af IR-fald. Datasættet indeholder funktioner, der er vidt brugt i de avancerede metoder og er valideret gennem eksperimenter.
- Nem at bruge formater:Funktioner er forbehandlet og transformeret til Numpy-arrays med begrænset information fjernet. Brugere kan nemt indlæse dataene gennem Python-scripts.
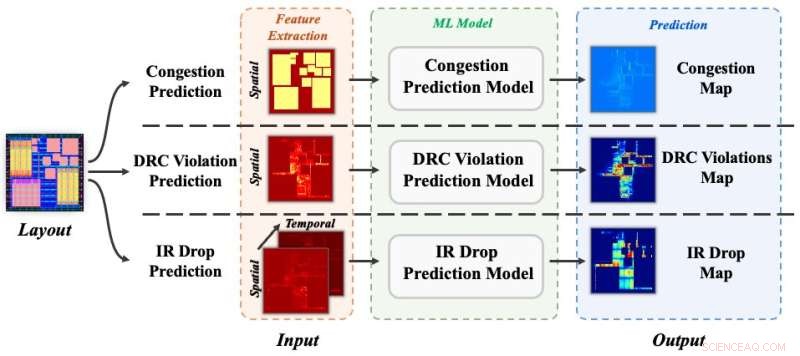
Tre forudsigelsesopgaver på tværs:overbelastning, DRC-overtrædelser og IR-fald. Kredit:Science China Press
For at evaluere effektiviteten af CircuitNet validerer forfatterne datasættet ved eksperimenter på tre forudsigelsesopgaver:overbelastning, DRC-overtrædelser og IR-fald. Hvert eksperiment tager en metode fra nyere undersøgelser og evaluerer dets resultat på CircuitNet med de samme evalueringsmetrikker som de originale undersøgelser. Samlet set stemmer resultaterne overens med de originale publikationer, hvilket demonstrerer effektiviteten af CircuitNet. En detaljeret vejledning om den eksperimentelle opsætning er tilgængelig på GitHub. I fremtiden planlægger forfatterne at inkorporere flere dataeksempler med storskaladesign i avancerede teknologiknuder for at forbedre datasættets skala og mangfoldighed.
Forskningen blev offentliggjort i Science China Information Sciences . + Udforsk yderligere
Byens digitale tvillinger hjælper med at træne deep learning-modeller til at adskille bygningsfacader
 Varme artikler
Varme artikler
-
 Hackere retter sig mod FN's humanitære organisationer:LookoutSikkerhedsforskere siger, at FN og andre humanitære arbejdere bliver ramt af falske e-mails fra hackere, der leder efter adgangskoder Hackere retter sig mod FN og humanitære hjælpearbejdere med en
Hackere retter sig mod FN's humanitære organisationer:LookoutSikkerhedsforskere siger, at FN og andre humanitære arbejdere bliver ramt af falske e-mails fra hackere, der leder efter adgangskoder Hackere retter sig mod FN og humanitære hjælpearbejdere med en -
 Hjulene kommer fra Gobee.bike -lejeservice i FrankrigGobee.bike -tjenesten i Frankrig er afbrudt på grund af hærværk og tyverier Folk, der ønsker at stige på deres cykler i Frankrig, har en mulighed mindre at gøre, efter at Gobee.bike -lejetjenesten
Hjulene kommer fra Gobee.bike -lejeservice i FrankrigGobee.bike -tjenesten i Frankrig er afbrudt på grund af hærværk og tyverier Folk, der ønsker at stige på deres cykler i Frankrig, har en mulighed mindre at gøre, efter at Gobee.bike -lejetjenesten -
 United Airlines beordrer 50 Airbus -fly til at erstatte Boeing 757'erUnited Airlines, hvis flåde hovedsageligt består af Boeing -fly (svarende til de 737 MAX -fly, der er afbilledet), afgav en ordre på 50 Airbus A321XLR fly United Airlines sagde tirsdag, at det hav
United Airlines beordrer 50 Airbus -fly til at erstatte Boeing 757'erUnited Airlines, hvis flåde hovedsageligt består af Boeing -fly (svarende til de 737 MAX -fly, der er afbilledet), afgav en ordre på 50 Airbus A321XLR fly United Airlines sagde tirsdag, at det hav -
 Indsigt fra Uganda om, hvorfor solcellegadelys giver meningSolcelledrevne gadelys i Kampala, Uganda. Kredit:George_TheGiwi/Shutterstock Gadebelysning er vigtig. Det giver uformelle sælgere og handlende mulighed for at arbejde i længere timer og forbedrer
Indsigt fra Uganda om, hvorfor solcellegadelys giver meningSolcelledrevne gadelys i Kampala, Uganda. Kredit:George_TheGiwi/Shutterstock Gadebelysning er vigtig. Det giver uformelle sælgere og handlende mulighed for at arbejde i længere timer og forbedrer
- Billede:Mulighedernes endelige krydskort
- Personlige mikrorobotter svømmer gennem biologiske barrierer, levere medicin til celler
- En laserteknik viser sig effektiv til at genvinde materiale designet til at beskytte industriprodukt…
- Sjældne flyvende ræve skudt i et forfærdeligt angreb i Australien
- Hjemme mister vand, da brønde løber tørre i tørkehærget bassin
- Afgiver højeffekt laserlys på plasmatæthedsgrænsen