


Forskere foreslår en ny og mere effektiv model for automatisk talegenkendelse
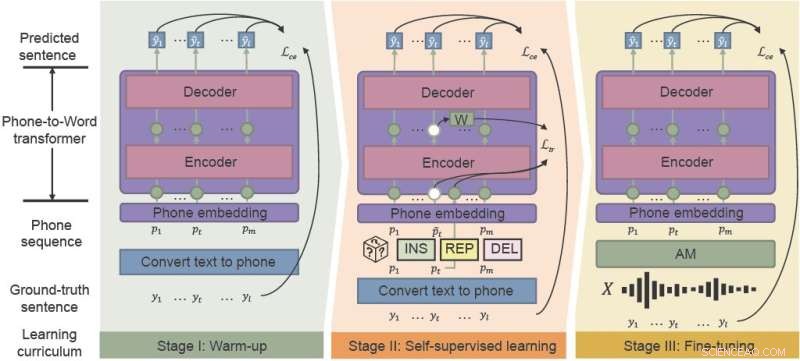
Den fonetisk-semantiske præ-træning (PSP)-ramme bruger "støjbevidst læseplan"-læring til effektivt at forbedre ydeevnen af ASR i støjende miljøer. integrere opvarmning, selvovervåget læring og finjustering. Kredit:CAAI Artificial Intelligence Research , Tsinghua University Press
Populære stemmeassistenter som Siri og Amazon Alexa har introduceret automatisk talegenkendelse (ASR) til den bredere offentlighed. Selvom der er årtier undervejs, kæmper ASR-modeller med konsistens og pålidelighed, især i støjende miljøer. Kinesiske forskere udviklede en ramme, der effektivt forbedrer ydeevnen af ASR til kaosset i hverdagens akustiske miljøer.
Forskere fra Hong Kong University of Science and Technology og WeBank foreslog en ny ramme - fonetisk-semantisk fortræning (PSP) og demonstrerede robustheden af deres nye model mod syntetiske meget støjende taledatasæt.
Deres undersøgelse blev offentliggjort i CAAI Artificial Intelligence Research den 28. august.
"Robusthed er en langvarig udfordring for ASR," sagde Xueyang Wu fra Hong Kong University of Science and Technology Department of Computer Science and Engineering. "Vi ønsker at øge robustheden af det kinesiske ASR-system til en lav pris."
ASR bruger maskinlæring og andre kunstige intelligensteknikker til automatisk at oversætte tale til tekst til brug som stemmeaktiverede systemer og transskriptionssoftware. Men nye forbrugerfokuserede applikationer kræver i stigende grad, at stemmegenkendelse fungerer bedre – håndtere flere sprog og accenter og yde mere pålideligt i virkelige situationer som videokonferencer og live-interviews.
Traditionelt kræver træning af de akustiske modeller og sprogmodeller, der omfatter ASR, store mængder støjspecifikke data, hvilket kan være tids- og omkostningskrævende.
Den akustiske model (AM) forvandler ord til "telefoner", som er sekvenser af grundlæggende lyde. Sprogmodellen (LM) afkoder telefoner til sætninger på naturligt sprog, normalt med en to-trins proces:en hurtig, men relativt svag LM genererer et sæt sætningskandidater, og en kraftfuld, men beregningsmæssigt dyr LM udvælger den bedste sætning blandt kandidaterne.
"Traditionelle læringsmodeller er ikke robuste over for støjende akustiske modeloutput, især for kinesiske polyfone ord med identisk udtale," sagde Wu. "Hvis den første gennemgang af indlæringsmodellens afkodning er forkert, er det ekstremt svært for den anden gennemgang at gøre det op."
Den nyligt foreslåede ramme-PSP gør det lettere at gendanne forkert klassificerede ord. Ved at fortræne en model, der oversætter AM-output direkte til sætning sammen med den fulde kontekstinformation, kan forskere hjælpe LM effektivt med at komme sig fra AM'ens støjende output.
PSP-rammen gør det muligt for modellen at forbedre sig gennem et før-træningsregime kaldet støjbevidst læseplan, der gradvist introducerer nye færdigheder, starter let og gradvist bevæger sig ind i mere komplekse opgaver.
"Den mest afgørende del af vores foreslåede metode, Noise-aware Curriculum Learning, simulerer mekanismen for, hvordan mennesker genkender en sætning fra støjende tale," sagde Wu.
Opvarmning er den første fase, hvor forskere fortræner en telefon-til-ord-transducer på en ren telefonsekvens, som kun er oversat fra umærkede tekstdata - for at skære ned på annoteringstiden. Dette trin "varmer" modellen op og initialiserer de grundlæggende parametre for at kortlægge telefonsekvenser til ord.
I anden fase, selvovervåget læring, lærer transduceren fra mere komplekse data genereret af selvovervågede træningsteknikker og -funktioner. Endelig finjusteres den resulterende telefon-til-ord-transducer med taledata fra den virkelige verden.
Forskerne demonstrerede eksperimentelt effektiviteten af deres rammer på to virkelige datasæt indsamlet fra industrielle scenarier og syntetisk støj. Resultaterne viste, at PSP-rammeværket effektivt forbedrer den traditionelle ASR-pipeline, hvilket reducerer de relative tegnfejlfrekvenser med 28,63 % for det første datasæt og 26,38 % for det andet.
I de næste trin vil forskerne undersøge mere effektive PSP-fortræningsmetoder med større uparrede datasæt, for at søge at maksimere effektiviteten af fortræning til støjstærk LM. + Udforsk yderligere
Brug af multi-task learning til taleoversættelse med lav latens
 Varme artikler
Varme artikler
-
 LearnedSketch AI-system til frekvensestimering forbedrer estimater af populære søgeforespørgslerKredit:Stuart Miles/Freerange Hvis du kigger under motorhjelmen på internettet, du vil finde masser af gear, der kører rundt, som gør det hele muligt. For eksempel, tag en virksomhed som AT&T. De
LearnedSketch AI-system til frekvensestimering forbedrer estimater af populære søgeforespørgslerKredit:Stuart Miles/Freerange Hvis du kigger under motorhjelmen på internettet, du vil finde masser af gear, der kører rundt, som gør det hele muligt. For eksempel, tag en virksomhed som AT&T. De -
 Cyklist og chauffør mellemfingerkrige:Indtast emoji-jakkenTænk Europa, tænk cykler, som voksne i alle aldre afsted på arbejde eller daglige ærinder er på vejen deles med biler. I 2020, cykler er blevet endnu mere populære, da miljøhensyn har ført til, at reg
Cyklist og chauffør mellemfingerkrige:Indtast emoji-jakkenTænk Europa, tænk cykler, som voksne i alle aldre afsted på arbejde eller daglige ærinder er på vejen deles med biler. I 2020, cykler er blevet endnu mere populære, da miljøhensyn har ført til, at reg -
 En mere præcis, lavpris 39 GHz beamforming transceiver til 5G kommunikationCMOS-chips på et 18 mm x 163,5 mm evalueringskort. Kredit:Atsushi Shirane, Kenichi Okada Forskere ved Tokyo Institute of Technology (Tokyo Tech) og NEC Corporation, Japan, præsentere en 39 GHz tra
En mere præcis, lavpris 39 GHz beamforming transceiver til 5G kommunikationCMOS-chips på et 18 mm x 163,5 mm evalueringskort. Kredit:Atsushi Shirane, Kenichi Okada Forskere ved Tokyo Institute of Technology (Tokyo Tech) og NEC Corporation, Japan, præsentere en 39 GHz tra -
 Fra bits til p-bits:Et skridt tættere på probabilistisk databehandlingUdsigt over en superparamagnetisk tunnelforbindelsesenhed (venstre). Set ovenfra af scanningselektronmikroskopbillede af den faktiske enhed (højre). Kredit:S. Kanai Forskere fra Tohoku University i
Fra bits til p-bits:Et skridt tættere på probabilistisk databehandlingUdsigt over en superparamagnetisk tunnelforbindelsesenhed (venstre). Set ovenfra af scanningselektronmikroskopbillede af den faktiske enhed (højre). Kredit:S. Kanai Forskere fra Tohoku University i
- Geofysiske observationer afslører vandfordelingen og effekten i Jordens kappe
- Organisationer, der behandler medarbejdere som børn, underminerer deres færdigheder og velvære
- Kinas ZTE standser aktiehandel efter amerikansk eksportforbud
- Snart vil din Cadillac skifte vognbane håndfrit med opgraderet Super Cruise-system
- Planteforsvarslaget har uventet effekt på flygtige forbindelser, undersøgelse finder
- Højpresterende i konkurrencedygtige kurser er mere tilbøjelige til at snyde til universitetseksame…