


Kemikere viser, hvordan bias kan dukke op i resultater fra maskinlæringsalgoritmer
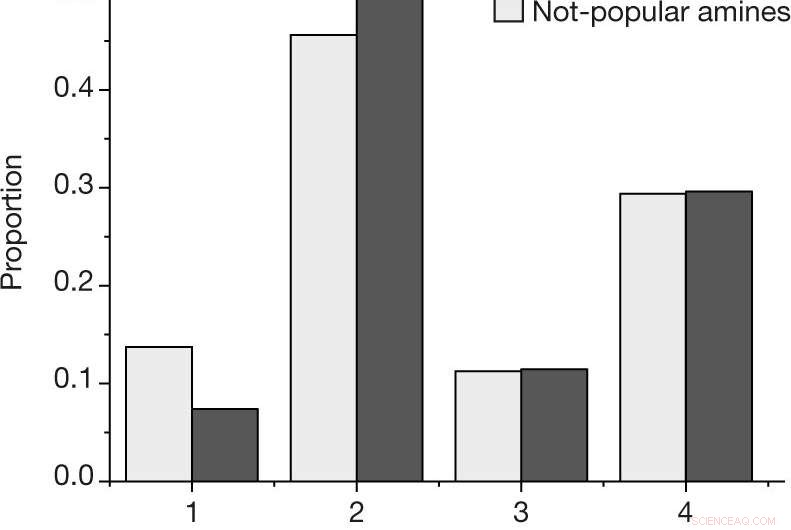
en, Andelen efter udfald for hver reaktion, ved hjælp af resultatskalaen beskrevet i Metoder, for de populære og ikke-populære aminer i det menneskevalgte datasæt. b, Estimeret sandsynlighed for at observere mindst én vellykket reaktion (udfald 4) eller fiasko (udfald 1, 2 og 3) for en given amin, for de N = 27 populære og N = 28 ikke-populære aminer blandt det menneskeligt udvalgte datasæt. Centerværdier angiver observeret andel af resultater. Fejlbjælker angiver et bootstrap-estimat af standardafvigelsen. Kredit: Natur (2019). DOI:10.1038/s41586-019-1540-5
Et team af materialeforskere ved Haverford College har vist, hvordan menneskelig skævhed i data kan påvirke resultaterne af maskinlæringsalgoritmer, der bruges til at forudsige nye reagenser til brug ved fremstilling af ønskede produkter. I deres papir offentliggjort i tidsskriftet Natur , gruppen beskriver test af en maskinlæringsalgoritme med forskellige typer datasæt, og hvad de fandt.
En af de mere velkendte anvendelser af maskinlæringsalgoritmer er ansigtsgenkendelse. Men der er mulige problemer med sådanne algoritmer. Et sådant problem opstår, når en ansigtsalgoritme, der er beregnet til at lede efter en person blandt mange ansigter, er blevet trænet ved hjælp af mennesker af kun én race. I denne nye indsats, forskerne spekulerede på, om bias, utilsigtet eller på anden måde, kan dukke op i maskinlæringsalgoritmeresultater, der bruges i kemiapplikationer designet til at lede efter nye produkter.
Sådanne algoritmer bruger data, der beskriver ingredienserne i reaktioner, der resulterer i skabelsen af et nyt produkt. Men de data, systemet er trænet på, kan have stor indflydelse på resultaterne. Forskerne bemærker, at pt. sådanne data er opnået fra offentliggjorte forskningsindsatser, hvilket betyder, at de typisk er genereret af mennesker. De bemærker, at dataene fra en sådan indsats kunne være blevet genereret af forskerne selv, eller af andre forskere, der arbejder med særskilte indsatser. Data kunne endda komme fra en enkelt person, der blot forholder sig fra hukommelsen, eller fra en professors forslag, eller en kandidatstuderende med en lys idé. Pointen er, dataene kan være partiske i forhold til baggrunden for ressourcen.
I denne nye indsats, forskerne ville vide, om sådanne skævheder kunne have en indvirkning på resultaterne af maskinlæringsalgoritmer, der bruges til kemiapplikationer. At finde ud af, de så på et specifikt sæt af materialer kaldet amin-templatede vanadiumborater. Når de er syntetiseret med succes, krystaller dannes - en nem måde at afgøre, om en reaktion var vellykket.
Eksperimentet bestod i at træne en maskinlæringsalgoritme på data omkring syntesen af vanadiumborater, og derefter programmere systemet til at skabe sit eget. Nogle af de data indsamlet af forskerne var menneskeskabte, og noget af det blev samlet tilfældigt. De rapporterer, at algoritmen trænet på de tilfældige data gjorde det bedre til at finde måder at syntetisere vanadiumboraterne på, end når den brugte data genereret fra mennesker. De hævder, at dette viser en klar skævhed i de data, der blev skabt af mennesker.
© 2019 Science X Network
 Varme artikler
Varme artikler
-
 Ekstrakt af ahornblade kan få rynker i hudenEkstrakter fra sommer- eller efterårsrøde ahornblade er formuleret til et pulver, der kan inkorporeres i hudplejeprodukter for at forhindre rynker. Kredit:Hang Ma Ahorntræer er bedst kendt for der
Ekstrakt af ahornblade kan få rynker i hudenEkstrakter fra sommer- eller efterårsrøde ahornblade er formuleret til et pulver, der kan inkorporeres i hudplejeprodukter for at forhindre rynker. Kredit:Hang Ma Ahorntræer er bedst kendt for der -
 Undersøgelse afslører en unik måde for cellemigration på bløde viskoelastiske overfladerKredit:CC0 Public Domain Inde i din krop, cellebevægelse spiller en afgørende rolle i mange væsentlige biologiske processer, herunder sårheling, immunreaktioner og den potentielle spredning af kræ
Undersøgelse afslører en unik måde for cellemigration på bløde viskoelastiske overfladerKredit:CC0 Public Domain Inde i din krop, cellebevægelse spiller en afgørende rolle i mange væsentlige biologiske processer, herunder sårheling, immunreaktioner og den potentielle spredning af kræ -
 Østrogene og anti-østrogene virkninger af PFAS'er kan afhænge af tilstedeværelsen af østrogenEstradiol, det største østrogen kønshormon hos mennesker og en meget brugt medicin. Kredit:Public Domain Perfluoralkylstoffer (PFASer) har modtaget intens kontrol i de seneste år på grund af deres
Østrogene og anti-østrogene virkninger af PFAS'er kan afhænge af tilstedeværelsen af østrogenEstradiol, det største østrogen kønshormon hos mennesker og en meget brugt medicin. Kredit:Public Domain Perfluoralkylstoffer (PFASer) har modtaget intens kontrol i de seneste år på grund af deres -
 Nye algoritmer vist at accelerere biofarmaceutisk procesKredit:Rensselaer Polytekniske Institut Biofarmaceutiske midler er nødvendige, livreddende værktøjer. Men processen for at lave dem er tidskrævende og dyr, især når det kommer til rensningsprocess
Nye algoritmer vist at accelerere biofarmaceutisk procesKredit:Rensselaer Polytekniske Institut Biofarmaceutiske midler er nødvendige, livreddende værktøjer. Men processen for at lave dem er tidskrævende og dyr, især når det kommer til rensningsprocess
- Hvad er spøgelsesvåben, og hvorfor er de så farlige?
- Sådan konverteres kubiske metre af naturgas til MMBTUs
- CES-gadgetshow:Hvordan det at se tv vil ændre sig i 2020'erne
- Hvad vil der ske med sedimentfaner forbundet med dybhavsminedrift?
- Forskere observerede først plasmoner på grafen
- Typer af begrundelse i Geometry