


Hvordan maskinlæring kan hjælpe regulatorer
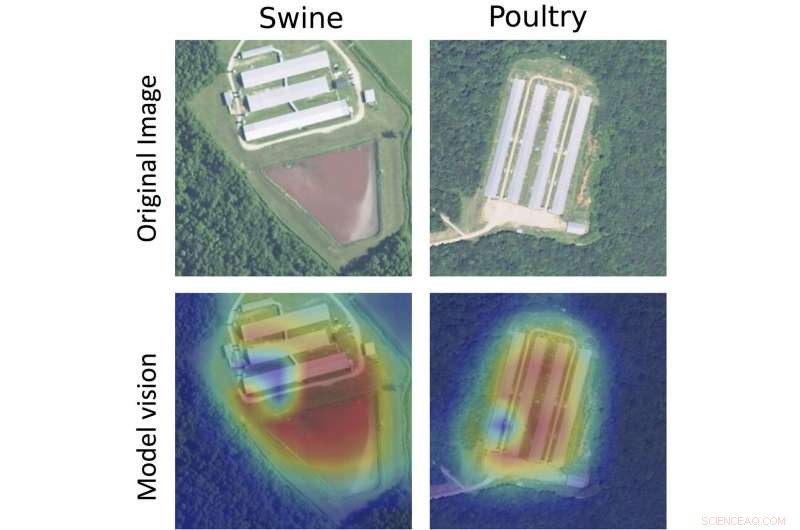
Prøvefaciliteter for svin (til venstre) og fjerkræ (til højre), med det originale billede (øverst) og et varmekort over den måde, de algoritmiske modeller behandlede billedet på (nederst). De røde områder viser, hvor modellen registrerede sandsynligheden for anlægsplaceringer. Kredit:National Agriculture Imagery Program / U.S. Department of Agriculture
Hvordan man lokaliserer potentielt forurenende dyrefarme har længe været et problem for miljøregulatorer. Nu, Stanford-forskere viser, hvordan en kortlæsningsalgoritme kan hjælpe regulatorer med at identificere faciliteter mere effektivt end nogensinde før.
Jura professor Daniel Ho, sammen med ph.d. studerende Cassandra Handan-Nader, har fundet ud af en måde til maskinlæring – at lære en computer at identificere og analysere mønstre i data – for effektivt at lokalisere industrielle dyrs operationer og hjælpe regulatorer med at bestemme hver enkelt facilitets miljørisiko. Forskernes resultater skal offentliggøres den 8. april i Naturens bæredygtighed .
"Vores arbejde viser, hvordan et regeringsorgan kan udnytte hurtige fremskridt inden for computervision for at beskytte rent vand mere effektivt, " sagde Ho, William Benjamin Scott og Luna M. Scott professor i jura, og en senior fellow ved Stanford Institute for Economic Policy Research.
Et grundlæggende problem, med komplekse konsekvenser
Ifølge Environmental Protection Agency (EPA), landbruget er den førende bidragyder af forurenende stoffer til landets vandforsyning, med betydelig forurening, der menes at stamme fra storskala, koncentrerede dyrefodringsoperationer, også kendt som CAFO'er.
Men indsatsen for miljøovervågning er blevet forhindret af et grundlæggende problem:Regulatorer har ingen systematisk måde at bestemme, hvor CAFO'er er placeret, sagde Ho. United States Government Accountability Office rapporterer, at intet føderalt agentur har pålidelige oplysninger om nummeret, størrelse og placering af store landbrugsaktiviteter.
Mens Clean Water Act kræver nogle føderale tilladelser, den gælder kun for operationer, der rent faktisk udleder forurenende stoffer i amerikanske vandveje – ikke anlæg, der potentielt kan forårsage forurening – bevidst eller ej, sagde Ho.
Uden en bestemt liste at henvende sig til, bestræbelser på at overvåge potentielt forurenende faciliteter er vanskelige, og i nogle tilfælde, umulig.
"Dette informationsunderskud kvæler håndhævelsen af miljølovgivningen i USA, " sagde Ho.
Nogle miljø- og offentlige interessegrupper har selv forsøgt at identificere faciliteter ved at scanne terræn manuelt eller gennemsøge luftfotos, men de har fundet det en utrolig tidskrævende opgave. Det tog én miljøgruppe over tre år at se på billeder fra kun én stat. Overvågningsindsatser som disse kunne aldrig skaleres eller udføres i realtid, sagde Ho.
Brug af big data til at udfylde hullerne
Ho og Handan-Nader, dengang stipendiat ved Stanford Law School og forfølger nu en doktorgrad i statskundskab, vendte deres opmærksomhed mod en type kunstig intelligens kaldet deep learning. En delmængde af maskinlæring, deep learning algoritmer har revolutioneret evnen til at opdage komplekse objekter i billeder.
Med hjælp fra adskillige open source-værktøjer og et team af studerende inden for økonomi og datalogi til at hjælpe med dataanalyse, Ho og Handan-Nader var i stand til at omskole en eksisterende billedgenkendelsesmodel til at genkende store dyrefaciliteter ved at bruge information indsamlet af to nonprofit-grupper og offentligt tilgængelige satellitbilleder fra USDA's National Agricultural Imagery Program (NAIP). Forskerne fokuserede på at forsøge at identificere fjerkræfaciliteter i North Carolina, fordi de fleste ikke er forpligtet til at opnå tilladelser, sagde Ho.
Modellen, allerede erfarne i at scanne billeder baseret på et enormt korpus af digitale billeder, blev omskolet til at opfange lignende spor, som miljøorganisationerne havde overvåget manuelt. For eksempel, svinefarme kunne identificeres ved kompakte rektangulære stalde, der støder op til store flydende gødningsgrave, og fjerkræ ved lange rektangulære stalde og tørgødningsopbevaring. Ved at tage udgangspunkt i disse fremtrædende træk, modellen var også i stand til at give størrelsesvurderinger for faciliteterne.
Forskerne fandt ud af, at deres algoritme var i stand til at identificere 15 procent flere fjerkræfarme, end hvad der oprindeligt blev fundet gennem manuelle bestræbelser. Og fordi deres tilgang kunne skalere på tværs af mange års NAIP-billeder, deres algoritme var i stand til nøjagtigt at estimere væksten i nærheden af en nyligt bygget fodermølle.
"Modellen opdagede 93 procent af alle fjerkræ CAFO'er i området, og var 97 procent nøjagtig til at bestemme, hvilke der dukkede op efter at fodermøllen åbnede, " skriver Handan-Nader og Ho i avisen.
Komplementær, tværfaglig tilgang
Ho og Handan-Nader håber, at maskinlæring kan supplere miljøagenturers og interessegruppers menneskelige overvågningsindsats.
"Nu kan alle slags forskere med programmeringsevne udnytte disse open source-værktøjer til nye applikationer, " sagde Handan-Nader, en medforfatter på papiret. "Du kan stå på skuldrene af giganter og uddybe, hvad eksperter i denne slags maskinlæringsteknikker har gjort."
Brug af maskinlæring til udenadslige opgaver kan frigøre folk til at udføre mere komplekse opgaver, såsom at bestemme de mulige miljøfarer ved et anlæg, sagde Handan-Nader. Forskerne vurderede, at deres algoritme kunne fange 95 procent af eksisterende storskalafaciliteter ved at bruge færre end 10 procent af de ressourcer, der kræves til en manuel folketælling.
Ho og Handan-Nader håber, til sidst, fremskridt inden for luftbilleder vil gøre det muligt for en computermodel at detektere faktisk udledning i vandveje.
"I stigende grad, komplekse sociale problemer kan ikke løses ud fra rammerne af en snæver disciplin alene, og evnen til at udnytte innovation på tværs af campus kan hjælpe med at løse kerneproblemer inden for lovgivning og offentlig politik, " sagde Ho.
 Varme artikler
Varme artikler
-
 Nordkoreansk atomprøve i 2017 10 gange større end tidligere forsøg, ny undersøgelse finderEstimeret eksplosiv størrelse af de seks atomprøvesprængninger på Punggye-ri teststedet på Mt. Mantap, Nordkorea, i enheder svarende til kilotons TNT. Sorte streger markerer det estimerede udbytte af
Nordkoreansk atomprøve i 2017 10 gange større end tidligere forsøg, ny undersøgelse finderEstimeret eksplosiv størrelse af de seks atomprøvesprængninger på Punggye-ri teststedet på Mt. Mantap, Nordkorea, i enheder svarende til kilotons TNT. Sorte streger markerer det estimerede udbytte af -
 Dæmninger kan efterligne floders frie strømning, men risici skal styresDæmninger, ligesom Kariba mellem Zambia og Zimbabwe, regulere flow til kunstvanding, vandkraft og vandforsyning. Leveres I de seneste årtier har mennesker har bygget mange dæmninger. Disse er desi
Dæmninger kan efterligne floders frie strømning, men risici skal styresDæmninger, ligesom Kariba mellem Zambia og Zimbabwe, regulere flow til kunstvanding, vandkraft og vandforsyning. Leveres I de seneste årtier har mennesker har bygget mange dæmninger. Disse er desi -
 Mellemøstlig ørkenstøv på det tibetanske plateau kan påvirke den indiske sommermonsunDette fotografi fra 2009 viser aflejring af store mængder støv fra ørkenerne på Colorado Plateau på snepose i Colorado Rockies. En ny undersøgelse ledet af University of Maryland tyder på, at støv fra
Mellemøstlig ørkenstøv på det tibetanske plateau kan påvirke den indiske sommermonsunDette fotografi fra 2009 viser aflejring af store mængder støv fra ørkenerne på Colorado Plateau på snepose i Colorado Rockies. En ny undersøgelse ledet af University of Maryland tyder på, at støv fra -
 Vandets kredsløb intensiveres, efterhånden som klimaet opvarmes, mere intense storme og oversvømm…Sammenlignet med gennemsnittet for 1850-1900. 1° Celsius stigning =1,8° Fahrenheit stigning. Kredit:Diagram:The Conversation/CC-BY-ND Kilde:IPCC Sixth Assessment Report Verden så i juli 2021, hvor
Vandets kredsløb intensiveres, efterhånden som klimaet opvarmes, mere intense storme og oversvømm…Sammenlignet med gennemsnittet for 1850-1900. 1° Celsius stigning =1,8° Fahrenheit stigning. Kredit:Diagram:The Conversation/CC-BY-ND Kilde:IPCC Sixth Assessment Report Verden så i juli 2021, hvor
- Astronauter er mindre tilbøjelige til at besvime på Jorden, hvis de træner i rummet
- Hvad er anvendelsen af carbondioxidgas?
- Rester af opdagelsesrejsende, der først rundede Australien, fundet i Storbritannien
- Fra vilde kameler til kokainflodheste, store dyr vilde verden igen
- Er månen runde?
- Sådan laver du grisjern i Minecraft