


Retningslinjer for et standardiseret dataformat til brug i tværsproglige undersøgelser
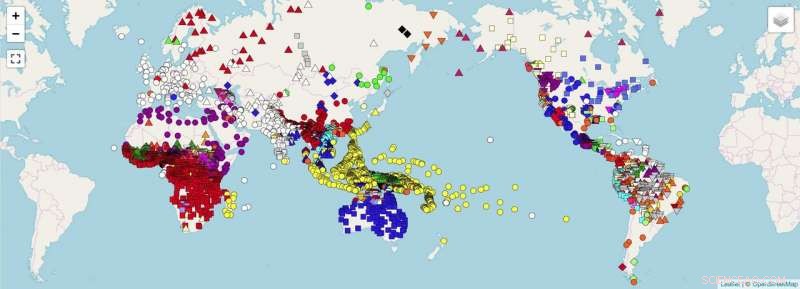
Et verdenskort, der viser datapunkter, for hvilke forskerne planlægger at indsamle ensartede data (f.eks. data, der er direkte sammenlignelige) ved hjælp af retningslinjerne i papiret. Kredit:OpenStreetMap. Forkel et al. 2018. Tværsproglige dataformater, fremme af datadeling og genbrug i komparativ lingvistik. Videnskabelige data .
Et internationalt team af forskere, medlemmer af Cross-Linguistic Data Formats Initiative (CLDF) ledet af Max Planck Institute for Science of Human History, har foreslået nye retningslinjer for tværsproglige dataformater for at lette deling og datasammenligninger mellem det voksende antal store sproglige databaser verden over. Dette format giver en softwarepakke, en grundlæggende ontologi og brugseksempler.
Der er et stigende antal sproglige databaser verden over, øger muligheden for et stort netværk til potentielle sammenlignende undersøgelser. Imidlertid, disse databaser er generelt oprettet uafhængigt af hinanden, og har ofte et unikt og snævert fokus. Det betyder, at de formater, der bruges til at kode dataene, ofte er forskellige, skabe vanskeligheder med at sammenligne data på tværs af databaser.
Cross-Linguistic Data Formats Initiative (CLDF) er et forsøg på at løse disse problemer. I et blad udgivet i Videnskabelige data , CLDF opstiller foreslåede retningslinjer for et standardiseret format for sproglige databaser, og leverer også en softwarepakke, en grundlæggende ontologi og brugseksempler på bedste praksis. Målet med denne indsats er at lette deling og genbrug af data i komparativ lingvistik.
CLDF leverer en datamodel, der ligger til grund for sine anbefalinger, som sigter mod at være enkel, dog udtryksfuld, og er baseret på den datamodel, der tidligere er udviklet til Cross-Linguistic Data-projektet. Denne model har fire hovedenheder:(a) sprog; (b) parametre; (c) værdier; og (d) kilder. I modellen, hver værdi er relateret til en parameter og et sprog, og kan være baseret på flere kilder. Der er desuden referencer til kilder, og referencer kan også have sammenhænge (som, for eksempel, for trykte referencer ville være sidetal).
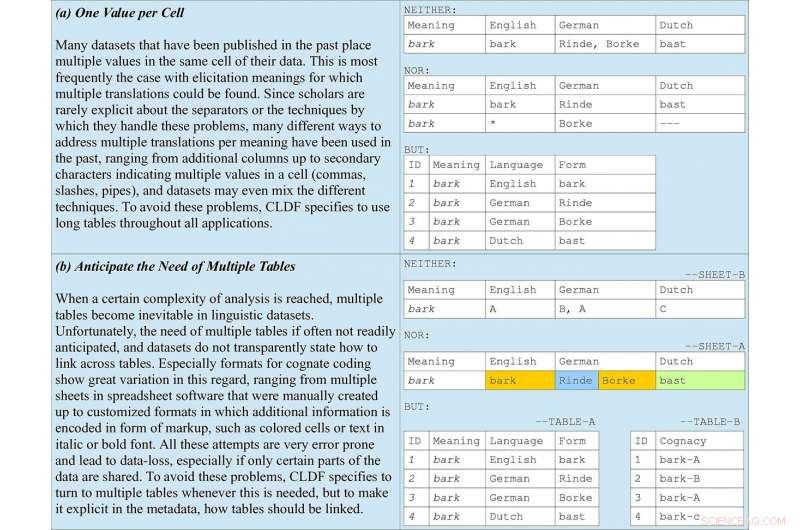
Grundlæggende regler for datakodning inkluderet i retningslinjerne, tager beslægtet kodning i ordlister som eksempel. (a) illustrerer, hvorfor lange tabeller bør foretrækkes i alle ansøgninger. (b) understreger vigtigheden af at forudse flere tabeller sammen med metadata, der angiver, hvordan de skal sammenkædes. Kredit:Forkel et al. 2018. Tværsproglige dataformater, fremme af datadeling og genbrug i komparativ lingvistik. Videnskabelige data .
CLDF-datamodellen er et pakkeformat, hvor et datasæt vil bestå af et sæt datafiler, der indeholder tabeller, og en beskrivende fil, der definerer relationerne mellem tabellerne. Hver sproglig datatype ville have et CLDF-modul og yderligere komponenter, hvilket ville være de aspekter af dataene i modulet, der går igen på tværs af flere datatyper. CLDF-modulerne vil også indeholde termer fra CLDF-ontologien. Ontologien er en liste over ordforråd, der repræsenterer objekter og egenskaber med velkendt semantik i komparativ lingvistik. Dette gør det muligt for brugerne at henvise til disse vilkår på en ensartet måde.
En softwarepakke til at muliggøre validering og manipulation
CLDF-specifikationerne bruger almindelige filformater - såsom CSV, JSON og BibTeX - der er bredt understøttet, med det mål, at disse filer nemt kan læses og skrives på mange platforme. Endnu vigtigere, det standardiserede format vil give forskere uden programmeringsfærdigheder adgang til og manipulere dataene med allerede eksisterende værktøjer, for at undgå at begrænse pakken til kun forskere med tilstrækkelige programmeringsevner til at skabe deres egne værktøjer. For at lette dette, CLDF har oprettet et "kogebog"-lager til scripts til brug med CLDF-specifikationerne.
"Vi ønsker at give adgang til disse data og muligheden for at sammenligne dem med så mange forskere som muligt, " siger Johann-Mattis List fra Max Planck Institute for Science of Human History. Robert Forkel, en af drivkræfterne bag CLDF-initiativet, bemærker også, at CLDF-formatet ikke er begrænset til sproglige data alene, men kan også inkorporere databaser med kulturelle og geografiske data, for eksempel. "CLDF kan drastisk lette afprøvningen af spørgsmål vedrørende samspillet mellem sproglige, kulturel, og miljøfaktorer i sproglig og kulturel udvikling."
 Varme artikler
Varme artikler
-
 Små og mellemstore byer er overraskende innovativeDe 152 små og mellemstore byer (SMSTer) i Schweiz blev grupperet i syv typer ved klyngeanalyse. Hver af typerne fik et navn afledt af klyngens dominerende karakteristika. På kortet har hver type en sæ
Små og mellemstore byer er overraskende innovativeDe 152 små og mellemstore byer (SMSTer) i Schweiz blev grupperet i syv typer ved klyngeanalyse. Hver af typerne fik et navn afledt af klyngens dominerende karakteristika. På kortet har hver type en sæ -
 At lære børn socialt ansvar – som hvordan man beder om hjælp – kan reducere mobningGrundskoleelever i Brasilien lærer sunde måder at løse konflikter på under en tre-dages workshop i 2019. Kredit:Sarah Roza, CC BY-NC-ND Skoler, der opmuntrer deres elever til at tage sig af deres
At lære børn socialt ansvar – som hvordan man beder om hjælp – kan reducere mobningGrundskoleelever i Brasilien lærer sunde måder at løse konflikter på under en tre-dages workshop i 2019. Kredit:Sarah Roza, CC BY-NC-ND Skoler, der opmuntrer deres elever til at tage sig af deres -
 Kvantitative Vs. Kvalitative data og laboratorietestKvantitative data er numeriske data, mens kvalitative data ikke har nogen tilknytning til dem. Respondenternes køn i en undersøgelse, der opdeler lyspærer i kategorier som meget lys, noget lys og svag
Kvantitative Vs. Kvalitative data og laboratorietestKvantitative data er numeriske data, mens kvalitative data ikke har nogen tilknytning til dem. Respondenternes køn i en undersøgelse, der opdeler lyspærer i kategorier som meget lys, noget lys og svag -
 Selfiekultur:Hvad dit valg af kameravinkel siger om digKameravinkler og selfie-sammensætning er proxyer for, hvordan du kan placere dig selv i et rum. Kredit:PxHere, FAL I løbet af det seneste årti, Selfies er blevet en grundpille i populærkulturen. H
Selfiekultur:Hvad dit valg af kameravinkel siger om digKameravinkler og selfie-sammensætning er proxyer for, hvordan du kan placere dig selv i et rum. Kredit:PxHere, FAL I løbet af det seneste årti, Selfies er blevet en grundpille i populærkulturen. H
- Forskere foreslår nye højtydende dual-ion-batterier med 3-D porøs struktur
- Stormscanningssatellitter går ind i driftsfasen
- Sådan læses en Western Blot
- Oliegiganter godkender kulstofafgifter efter Trumps Paris -exit
- Den garvede amerikanske pilot Wally Funk for at opfylde rumdrømmen 60 år efter
- Undersøgelse kaster lys over, hvordan planter får deres nitrogenfix