


Maskinlæring afslører kulturens rolle i at forme betydninger af ord

Forskere brugte maskinlæring til at skabe den første storskala, datadrevet undersøgelse for at belyse, hvordan kultur påvirker betydningen af ord. Kredit:Maleri af Babelstårnet af Pieter Bruegel den Ældre, Kunsthistorisches Museum Wien, Wien, Østrig
Hvad mener vi med ordet smuk? Det afhænger ikke kun af, hvem du spørger, men på hvilket sprog du spørger dem. Ifølge en maskinlæringsanalyse af snesevis af sprog udført på Princeton University, betydningen af ord refererer ikke nødvendigvis til en iboende, væsentlig konstant. I stedet, det er væsentligt formet af kultur, historie og geografi. Denne konstatering gjaldt selv for nogle begreber, der synes at være universelle, såsom følelser, landskabstræk og kropsdele.
"Selv for hver dag ord, som du ville tro betyder det samme for alle, der er al denne variation derude, " sagde William Thompson, en postdoc-forsker i datalogi ved Princeton University, og hovedforfatter af resultaterne, udgivet i Natur Menneskelig adfærd 10. august "Vi har leveret det første datadrevne bevis på, at måden vi fortolker verden på gennem ord er en del af vores kulturarv."
Sproget er det prisme, hvorigennem vi begrebsliggør og forstår verden, og lingvister og antropologer har længe søgt at udrede de komplekse kræfter, der former disse kritiske kommunikationssystemer. Men undersøgelser, der forsøger at løse disse spørgsmål, kan være svære at udføre og tidskrævende, involverer ofte lange, omhyggelige interviews med tosprogede talere, som vurderer kvaliteten af oversættelser. "Det kan tage år og år at dokumentere et bestemt sprogpar og forskellene mellem dem, " sagde Thompson. "Men maskinlæringsmodeller er for nylig dukket op, som giver os mulighed for at stille disse spørgsmål med et nyt niveau af præcision."
I deres nye avis, Thompson og hans kolleger Seán Roberts fra University of Bristol, Storbritannien, og Gary Lupyan fra University of Wisconsin, Madison, udnyttet kraften i disse modeller til at analysere over 1, 000 ord på 41 sprog.
I stedet for at forsøge at definere ordene, den storstilede metode bruger begrebet "semantiske associationer, " eller blot ord, der har et meningsfuldt forhold til hinanden, som lingvister finder er en af de bedste måder at definere et ord på og sammenligne det med et andet. Semantiske associerede til "smuk, " for eksempel, inkludere "farverige, " "kærlighed, " "dyrbar" og "sart."
Forskerne byggede en algoritme, der undersøgte neurale netværk trænet på forskellige sprog for at sammenligne millioner af semantiske associationer. Algoritmen oversatte de semantiske associerede til et bestemt ord til et andet sprog, og gentog derefter processen den anden vej rundt. For eksempel, algoritmen oversatte de semantiske associates af "beautiful" til fransk og oversatte derefter de semantiske associates af beau til engelsk. Algoritmens endelige lighedsscore for et ords betydning kom fra at kvantificere, hvor tæt semantikken passede i begge retninger af oversættelsen.
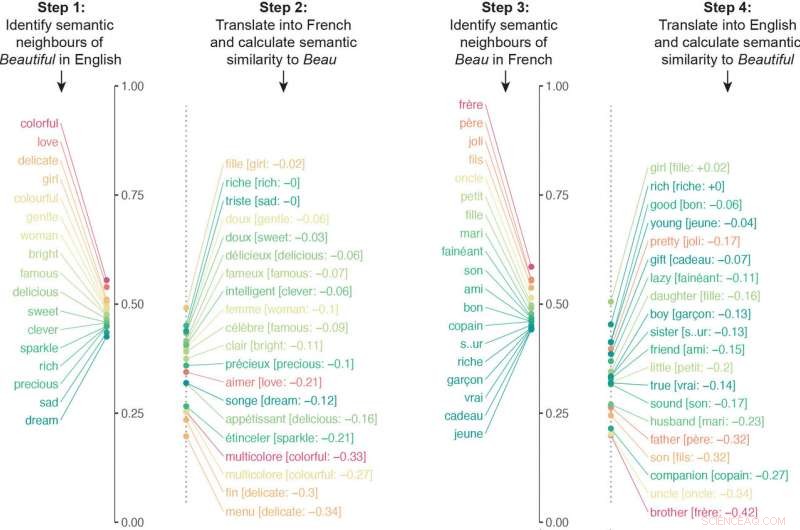
Algoritmen oversatte de semantiske associerede til et bestemt ord til et andet sprog, og gentog derefter processen den anden vej rundt. I dette eksempel, de semantiske naboer af "beautiful" blev oversat til fransk, og derefter blev de semantiske naboer af "beau" oversat til engelsk. De respektive lister var væsentligt forskellige på grund af forskellige kulturelle sammenslutninger. Billedet er udlånt af forskerne. Kredit:Princeton University
"En måde at se på, hvad vi har gjort, er en datadrevet måde at kvantificere, hvilke ord der er mest oversættelige, "Sagde Thompson.
Resultaterne afslørede, at der er nogle næsten universelt oversættelige ord, primært dem, der refererer til tal, erhverv, mængder, kalenderdatoer og slægtskab. Mange andre ordtyper, imidlertid, herunder dem, der refererede til dyr, mad og følelser, var meget mindre godt matchede i betydning.
I et sidste trin, forskerne anvendte en anden algoritme, der sammenlignede, hvor ens de kulturer, der producerede de to sprog, er, baseret på et antropologisk datasæt, der sammenligner ting som ægteskabspraksis, juridiske systemer og politisk organisering af givne sprogs talere.
Forskerne fandt ud af, at deres algoritme korrekt kunne forudsige, hvor let to sprog kunne oversættes baseret på, hvor ens de to kulturer, der taler dem, er. Dette viser, at variation i ordbetydning ikke kun er tilfældig. Kultur spiller en stærk rolle i at forme sprog - en hypotese, som teori længe har forudsagt, men at forskerne manglede kvantitative data at understøtte.
"Dette er et ekstremt flot papir, der giver en principiel kvantificering af spørgsmål, der har været centrale for studiet af leksikalsk semantik, " sagde Damián Blasi, en sprogforsker ved Harvard University, som ikke var involveret i den nye forskning. Selvom papiret ikke giver et endeligt svar på alle de kræfter, der former forskellene i ordbetydning, de metoder, forfatterne har etableret, er sunde, Blasi sagde, og brugen af flere, forskellige datakilder "er en positiv ændring i et felt, der systematisk har set bort fra kulturens rolle til fordel for mentale eller kognitive universaler."
Thompson var enig i, at han og hans kollegers resultater understreger værdien af at "kuratere usandsynlige datasæt, der normalt ikke ses under de samme omstændigheder." De maskinlæringsalgoritmer, han og hans kolleger brugte, blev oprindeligt trænet af dataloger, mens de datasæt, de indførte i modellerne for at analysere, blev skabt af det 20. århundredes antropologer såvel som nyere sproglige og psykologiske undersøgelser. Som Thompson sagde, "Bag disse fancy nye metoder, der er en hel historie med mennesker i flere felter, der indsamler data, som vi samler og ser på på en helt ny måde."
 Varme artikler
Varme artikler
-
 Reducer børns testangst med disse tips - og genovervej, hvad test betyderForældre kan forsikre børn om, at angst er en naturlig følelse, de kan lære at håndtere. Kredit:Shutterstock Udtrykket testangst fremmaner typisk billeder af en gymnasie- eller universitetsstudere
Reducer børns testangst med disse tips - og genovervej, hvad test betyderForældre kan forsikre børn om, at angst er en naturlig følelse, de kan lære at håndtere. Kredit:Shutterstock Udtrykket testangst fremmaner typisk billeder af en gymnasie- eller universitetsstudere -
 Forskere finder en sammenhæng mellem patogenhistorie og graden af moralsk vitalismeKredit:CC0 Public Domain Et internationalt hold af forskere har fundet beviser, der tyder på, at graden af moralsk vitalisme - at tro på kræfter på godt og ondt - i et givet samfund kan være rel
Forskere finder en sammenhæng mellem patogenhistorie og graden af moralsk vitalismeKredit:CC0 Public Domain Et internationalt hold af forskere har fundet beviser, der tyder på, at graden af moralsk vitalisme - at tro på kræfter på godt og ondt - i et givet samfund kan være rel -
 En virtual reality-tilgang til social interaktionKredit:Alexandra Georgescu Folk har en tendens til at kopiere andres adfærd, ansigtsudtryk eller tale, når de er socialt interagerende med dem. At forstå denne utilsigtede mimik ved hjælp af sofis
En virtual reality-tilgang til social interaktionKredit:Alexandra Georgescu Folk har en tendens til at kopiere andres adfærd, ansigtsudtryk eller tale, når de er socialt interagerende med dem. At forstå denne utilsigtede mimik ved hjælp af sofis -
 Derfor er bingewatching ikke længere på modeKredit:CC0 Public Domain En førende tv-akademiker mener, at binge-watching nu endelig er gået af mode. Skrivning i det akademiske tidsskrift Deltagelser:Journal of Audience &Reception Studies ,
Derfor er bingewatching ikke længere på modeKredit:CC0 Public Domain En førende tv-akademiker mener, at binge-watching nu endelig er gået af mode. Skrivning i det akademiske tidsskrift Deltagelser:Journal of Audience &Reception Studies ,
- Ny indsigt i strømmen af polymer og levende polymerløsninger
- Kasseret affald kan være en skatkammer af sjældne metaller
- Sådan bestemmes om en grænse eksisterer ved en funktionsgraf
- Jagten på udenjordisk liv i vandverdenerne tæt på hjemmet
- Ny forskning om bedrageriske stjerner kan forbedre astronomiske data
- Bearded Vs. Ikke-skæggede silkies