


Forskere udvikler kunstig intelligens til at forudsige startup-virksomheders succes
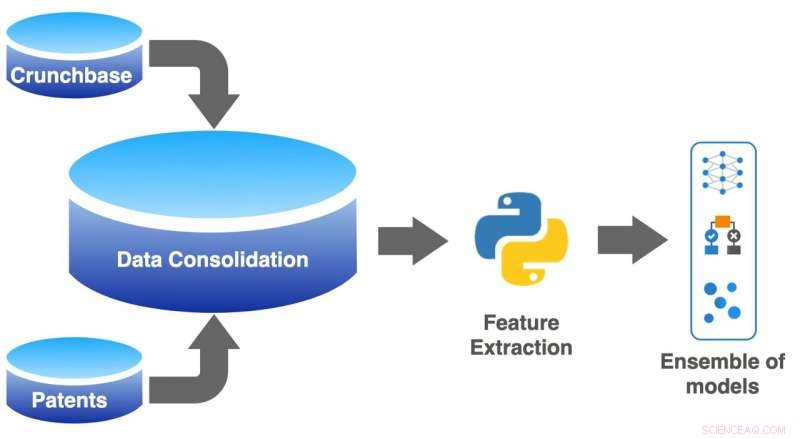
Maskinlæringspipelinen brugt til at træne modellerne. Kredit:Greg Ross
En undersøgelse, hvor maskinlæringsmodeller blev trænet til at vurdere over 1 million virksomheder, har vist, at kunstig intelligens (AI) nøjagtigt kan afgøre, om en startup-virksomhed vil fejle eller få succes. Resultatet er et værktøj, Venhound, som har potentialet til at hjælpe investorer med at identificere den næste enhjørning.
Det er velkendt, at omkring 90 % af startups mislykkes:Mellem 10 % og 22 % fejler inden for deres første år, og dette udgør en betydelig risiko for venturekapitalister og andre investorer i virksomheder i tidlig fase. I et forsøg på at identificere, hvilke virksomheder der har størst sandsynlighed for at få succes, forskere har udviklet maskinlæringsmodeller, der er trænet i over 1 million virksomheders historiske præstationer. Deres resultater, udgivet i KeAi's Journal of Finance and Data Science , viser, at disse modeller kan forudsige resultatet af en virksomhed med op til 90 % nøjagtighed. Det betyder, at potentielt er 9 ud af 10 virksomheder korrekt vurderet.
"Denne forskning viser, hvordan ensembler af ikke-lineære maskinlæringsmodeller anvendt på big data har et enormt potentiale til at kortlægge store funktionssæt til forretningsresultater, noget, der er uopnåeligt med traditionelle lineære regressionsmodeller, " forklarer medforfatter Sanjiv Das, Professor i finans- og datavidenskab ved Santa Clara University's Leavey School of Business i USA.
Forfatterne udviklede et nyt ensemble af modeller, hvor det kombinerede bidrag fra modellerne opvejer hver enkelts forudsigelsespotentiale. Hver model klassificerer en virksomhed, at placere den i en af flere succeskategorier eller en fiaskokategori med en specifik sandsynlighed. For eksempel, en virksomhed kan have stor sandsynlighed for at få succes, hvis ensemblet siger, at den har 75 % sandsynlighed for at være i kategorien IPO (noteret på børsen) eller 'opkøbt af en anden virksomhed', mens kun 25% af dens forudsigelse ville falde i kategorien mislykkedes.
Forskerne trænede modellerne på data hentet fra Crunchbase, en crowd-sourcet platform, der indeholder detaljerede oplysninger om mange virksomheder. De giftede sig med Crunchbase-observationerne med patentdata fra USPTO (United States Patent and Trademark Office). I betragtning af Crunchbases crowd-sourcede karakter, det var ingen overraskelse at høre, at nogle virksomheders indtastninger mangler information. Denne observation inspirerede forfatterne til at måle mængden af information, der mangler for hver virksomhed og bruge denne værdi som input til modellen. Denne observation viste sig at være en af de mest kritiske træk ved bestemmelsen af, om en virksomhed ville blive opkøbt eller på anden måde mislykkes.
Hovedforfatter Greg Ross fra Venhound Inc. bemærker, at ensemblet af modeller, sammen med nye datafunktioner, "genererer et niveau af nøjagtighed, præcision og tilbagekaldelse, der overstiger andre lignende undersøgelser. Investorer kan bruge dette til hurtigt at evaluere kundeemner, løfte potentielle røde flag og træffe mere informerede beslutninger om sammensætningen af deres porteføljer."
 Varme artikler
Varme artikler
-
 Genomanalyse afslører ukendt gammel menneskelig migration i EuropaRester fundet i Bacho Kiro-hulen i Bulgarien går tilbage til 45, 000 år i nogle tilfælde Genetisk sekventering af menneskelige efterladenskaber, der går tilbage 45, 000 år har afsløret en hidtil u
Genomanalyse afslører ukendt gammel menneskelig migration i EuropaRester fundet i Bacho Kiro-hulen i Bulgarien går tilbage til 45, 000 år i nogle tilfælde Genetisk sekventering af menneskelige efterladenskaber, der går tilbage 45, 000 år har afsløret en hidtil u -
 Er ligestilling på arbejdspladsen økonomiens skjulte motor?Kredit:CC0 Public Domain I 1960, 94 procent af læger og advokater var hvide mænd. I dag er det tal faldet til 60 procent, og økonomien har draget dramatisk fordel af det. I en sang fra 1989, Laur
Er ligestilling på arbejdspladsen økonomiens skjulte motor?Kredit:CC0 Public Domain I 1960, 94 procent af læger og advokater var hvide mænd. I dag er det tal faldet til 60 procent, og økonomien har draget dramatisk fordel af det. I en sang fra 1989, Laur -
 Er du mentalt godt nok til college?Universitetsstuderende søger mental sundhed behandling på campus på rekordhøje niveauer. Kredit:Monkey Business Images/Shutterstock.com Sidste forår kom en 18-årig nybegynder på universitetet, som
Er du mentalt godt nok til college?Universitetsstuderende søger mental sundhed behandling på campus på rekordhøje niveauer. Kredit:Monkey Business Images/Shutterstock.com Sidste forår kom en 18-årig nybegynder på universitetet, som -
 Hvad er de mystiske Havana Syndrome Attacks i DC?Siden 2016 har Amerikanske statsansatte har klaget over bizarre neurologiske symptomer, som hovedpine, ringer i ørerne, svimmelhed og endda hukommelsestab. Regeringen har nu indrømmet, at disse sympto
Hvad er de mystiske Havana Syndrome Attacks i DC?Siden 2016 har Amerikanske statsansatte har klaget over bizarre neurologiske symptomer, som hovedpine, ringer i ørerne, svimmelhed og endda hukommelsestab. Regeringen har nu indrømmet, at disse sympto
- Regeringen fejlregner reduktioner af drivhusgasemissioner
- Slap af, udvidelsen af universet accelererer stadig
- De fleste medarbejdere kan arbejde smartere, givet chancen
- Robocop på patrulje ved topmødet i Singapore
- Amerikas nye normal:En grad varmere end for to årtier siden
- Populær nanopartikel forårsager toksicitet hos fisk, undersøgelse viser