


Spørgsmål og svar:Sådan laver du bæredygtige produkter hurtigere med kunstig intelligens og automatisering
Ved at modificere genomerne af planter og mikroorganismer kan syntetiske biologer designe biologiske systemer, der opfylder en specifikation, såsom at producere værdifulde kemiske forbindelser, gøre bakterier følsomme over for lys eller programmere bakterieceller til at invadere kræftceller.
Dette videnskabsområde, selvom det kun er et par årtier gammelt, har muliggjort storskalaproduktion af medicinske lægemidler og etableret evnen til at fremstille oliefrie kemikalier, brændstoffer og materialer. Det ser ud til, at biofremstillede produkter er kommet for at blive, og at vi vil stole mere og mere på dem, efterhånden som vi skifter væk fra traditionelle, kulstofintensive fremstillingsprocesser.
Men der er en stor hindring - syntetisk biologi er arbejdskrævende og langsom. Fra at forstå de gener, der kræves for at fremstille et produkt, til at få dem til at fungere ordentligt i en værtsorganisme, og til sidst til at få den organisme til at trives i et industrielt miljø i stor skala, så den kan producere nok produkt til at imødekomme markedets efterspørgsel, udvikling af en biofremstillingsproces kan tage mange år og mange millioner dollars i investeringer.
Héctor García Martín, en stabsforsker i Biosciences Area of Lawrence Berkeley National Laboratory (Berkeley Lab), arbejder på at accelerere og forfine dette F&U-landskab ved at anvende kunstig intelligens og de matematiske værktøjer, han mestrede under sin uddannelse som fysiker.
Vi talte med ham for at lære, hvordan kunstig intelligens, skræddersyede algoritmer, matematisk modellering og robotautomatisering kan samles som en sum, der er større end dens dele, og give en ny tilgang til syntetisk biologi.
Hvorfor tager syntetisk biologi forskning og procesopskalering stadig lang tid?
Jeg tror, at de forhindringer, vi finder i syntetisk biologi for at skabe vedvarende produkter, alle stammer fra en meget grundlæggende videnskabelig mangel:vores manglende evne til at forudsige biologiske systemer. Mange syntetiske biologer kan være uenige med mig og pege på vanskeligheden i at skalere processer fra milliliter til tusindvis af liter, eller kampene for at udvinde høje nok udbytter til at garantere kommerciel levedygtighed, eller endda den besværlige litteratur søger efter molekyler med de rigtige egenskaber til at syntetisere. Og det er alt sammen sandt.
Men jeg tror, at de alle er en konsekvens af vores manglende evne til at forudsige biologiske systemer. Lad os sige, at vi havde en med en tidsmaskine (eller Gud eller dit yndlings alvidende væsen) til at komme og give os en perfekt designet DNA-sekvens til at sætte i en mikrobe, så den ville skabe den optimale mængde af vores ønskede målmolekyle (f.eks. et biobrændstof) i store skalaer (tusindvis af liter).
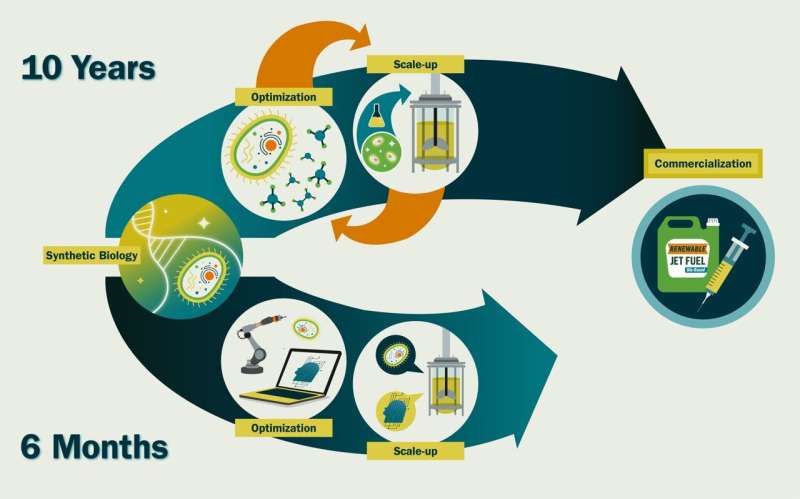
Det ville tage et par uger at syntetisere og omdanne det til en celle, og tre til seks måneder at dyrke det i kommerciel skala. Forskellen mellem de 6,5 måneder og de ~10 år, det tager os nu, er tid brugt på at finjustere genetiske sekvenser og dyrkningsbetingelser - for eksempel at sænke ekspressionen af et bestemt gen for at undgå giftig opbygning eller øge iltniveauet for hurtigere vækst —fordi vi ikke ved, hvordan disse vil påvirke celleadfærd.
Hvis vi kunne forudsige det præcist, ville vi være i stand til at konstruere dem meget mere effektivt. Og sådan gør man det i andre fag. Vi designer ikke fly ved at bygge nye flyformer og flyve dem for at se, hvor godt de fungerer. Vores viden om væskedynamik og konstruktionsteknik er så god, at vi kan simulere og forudsige den effekt, som noget som en ændring af flykroppen vil have på flyvningen.
Hvordan accelererer kunstig intelligens disse processer? Kan du give nogle eksempler på nyere arbejde?
Vi bruger maskinlæring og kunstig intelligens til at give den forudsigelseskraft, som syntetisk biologi har brug for. Vores tilgang omgår behovet for fuldt ud at forstå de involverede molekylære mekanismer, hvilket er, hvordan det sparer betydelig tid. Dette vækker dog en vis mistanke hos traditionelle molekylærbiologer.
Normalt skal disse værktøjer trænes på enorme datasæt, men vi har bare ikke så meget data inden for syntetisk biologi, som du måske har i noget som astronomi, så vi udviklede unikke metoder til at overvinde den begrænsning. For eksempel har vi brugt maskinlæring til at forudsige, hvilke promotorer (DNA-sekvenser, der medierer genekspression), der skal vælges for at opnå maksimal produktivitet.
Vi har også brugt maskinlæring til at forudsige de rigtige vækstmedier for optimal produktion, til at forudsige cellers metaboliske dynamik, til at øge udbyttet af bæredygtige flybrændstofprækursorer og til at forudsige, hvordan man konstruerer fungerende polyketidsyntaser (enzymer, der kan producere en enorm variation af værdifulde molekyler, men er berygtet svære at forudsigeligt konstruere).
I mange af disse tilfælde var vi nødt til at automatisere de videnskabelige eksperimenter for at opnå de store mængder af højkvalitetsdata, som vi har brug for, for at AI-metoder virkelig kan være effektive. For eksempel har vi brugt robotvæskebehandlere til at skabe nye vækstmedier til mikrober og teste deres effektivitet, og vi har udviklet mikrofluidchips til at forsøge at automatisere genetisk redigering. Jeg arbejder aktivt sammen med andre på laboratoriet (og eksterne samarbejdspartnere) for at skabe selvkørende laboratorier til syntetisk biologi.
Er der mange andre grupper i USA, der udfører lignende arbejde? Tror du, at dette felt vil blive større med tiden?
Antallet af forskergrupper med ekspertise i krydsfeltet mellem AI, syntetisk biologi og automatisering er meget lille, især uden for industrien. Jeg vil fremhæve Philip Romero ved University of Wisconsin og Huimin Zhao ved University of Illinois Urbana-Champaign Men i betragtning af potentialet ved denne kombination af teknologier til at have en enorm samfundsmæssig indvirkning (f.eks. i bekæmpelse af klimaændringer eller fremstilling af nye terapeutiske lægemidler ), tror jeg, at dette felt vil vokse meget hurtigt i den nærmeste fremtid.
Jeg har været en del af flere arbejdsgrupper, kommissioner og workshops, herunder et møde med eksperter for National Security Commission on Emerging Biotechnology, som diskuterede mulighederne på dette område og udarbejder rapporter med aktive anbefalinger.
Hvilken slags fremskridt forventer du i fremtiden ved at fortsætte dette arbejde?
Jeg tror, at en intens anvendelse af kunstig intelligens og robotteknologi/automatisering til syntetisk biologi kan accelerere syntetisk biologi-tidslinjer ~20 gange. Vi kunne skabe et nyt kommercielt levedygtigt molekyle på ~6 måneder i stedet for ~10 år. Dette er hårdt tiltrængt, hvis vi ønsker at muliggøre en cirkulær bioøkonomi – bæredygtig brug af vedvarende biomasse (kulstofkilder) til at generere energi og mellem- og slutprodukter.
Der er anslået 3.574 højproduktionsvolumen (HPV) kemikalier (kemikalier, som USA producerer eller importerer i mængder på mindst 1 million pund om året), der kommer fra petrokemikalier i dag. Et bioteknologifirma ved navn Genencor havde brug for 575 års arbejde for at producere en vedvarende vej til fremstilling af et af disse meget brugte kemikalier, 1,3-propandiol, og dette er et typisk tal.
Hvis vi antager, at det er hvor lang tid det ville tage at designe en biofremstillingsproces til at erstatte olieraffineringsprocessen for hver af disse tusindvis af kemikalier, ville vi have brug for ~ 2.000.000 personår. Hvis vi sætter alle de anslåede ~5.000 amerikanske syntetiske biologer (lad os sige 10 % af alle biologiske forskere i USA, og det er en overvurdering) til at arbejde på dette, ville det tage ~371 år at skabe den cirkulære bioøkonomi.
Med temperaturanomalien, der vokser hvert år, har vi ikke rigtig 371 år. Disse tal er naturligvis hurtige bagud-af-kuvert-beregninger, men de giver en idé om størrelsesordenen, hvis vi fortsætter den nuværende vej. Vi har brug for en disruptiv tilgang.
Ydermere vil denne tilgang muliggøre forfølgelsen af mere ambitiøse mål, som er uigennemførlige med nuværende tilgange, såsom:konstruktion af mikrobielle samfund til miljøformål og menneskers sundhed, biomaterialer, biomanipuleret væv osv.
Hvordan er Berkeley Lab et unikt miljø for denne forskning?
Berkeley Lab har haft en stærk investering i syntetisk biologi i de sidste to årtier og udviser betydelig ekspertise på området. Desuden er Berkeley Lab hjemstedet for "big science":store teams, multidisciplinær videnskab og
Jeg tror, det er den rigtige vej for syntetisk biologi i dette øjeblik. Meget er blevet opnået i de sidste halvfjerds år siden opdagelsen af DNA gennem traditionelle molekylærbiologiske tilgange med enkeltforskere, men jeg tror, at udfordringerne forude kræver en tværfaglig tilgang, der involverer syntetiske biologer, matematikere, elektroingeniører, dataloger, molekylærbiologer, kemiingeniører osv. Jeg synes, Berkeley Lab burde være det naturlige sted for den slags arbejde.
Fortæl os lidt om din baggrund, hvad inspirerede dig til at studere matematisk modellering af biologiske systemer?
Siden meget tidligt har jeg været meget interesseret i naturvidenskab, specielt biologi og fysik. Jeg husker tydeligt, at min far fortalte mig om dinosaurernes udryddelse. Jeg husker også, at jeg fik at vide, hvordan der i Perm-perioden var kæmpe guldsmede (~75 cm), fordi iltniveauet var meget højere end nu (~30% vs. 20%), og insekter får deres ilt gennem diffusion, ikke lunger. Derfor muliggjorde større iltniveauer meget større insekter.
Jeg var også fascineret af den evne, matematik og fysik giver os til at forstå og konstruere ting omkring os. Fysik var mit første valg, fordi den måde, biologi blev undervist på dengang involverede meget mere udenadslære end kvantitative forudsigelser. Men jeg har altid haft en interesse i at lære, hvilke videnskabelige principper der førte til liv på Jorden, som vi ser det nu.
Jeg opnåede min Ph.D. i teoretisk fysik, hvor jeg simulerede Bose-Einstein-kondensater (en tilstand af stof, der opstår, når partikler kaldet bosoner, en gruppe, der inkluderer fotoner, er tæt på det absolutte nulpunkt) og ved hjælp af vejintegralet Monte Carlo-teknikker, men det gav også en forklaring på et 100+ år gammelt puslespil i økologi:hvorfor skalaer antallet af arter i et område med en tilsyneladende universel magtlov afhængighed af området (S=cA z , z=0,25)? Fra da af kunne jeg have arbejdet videre med fysik, men jeg tænkte, at jeg kunne få mere indflydelse ved at anvende forudsigelige evner til biologi.
Af denne grund tog jeg en stor satsning på en fysik Ph.D. og accepterede en postdoc ved DOE Joint Genome Institute i metagenomics - sekventering af mikrobielle samfund for at optrevle deres underliggende cellulære aktiviteter - med håbet om at udvikle prædiktive modeller for mikrobiomer. Jeg fandt dog ud af, at de fleste mikrobielle økologer havde begrænset interesse for prædiktive modeller, så jeg begyndte at arbejde med syntetisk biologi, som har brug for forudsigelsesevner, fordi det har til formål at konstruere celler til en specifikation.
Min nuværende stilling giver mig mulighed for at bruge min matematiske viden til at prøve og forudsigeligt konstruere celler til at producere biobrændstoffer og bekæmpe klimaændringer. Vi har gjort mange fremskridt og har givet nogle af de første eksempler på AI-styret syntetisk biologi, men der er stadig meget arbejde at gøre for at gøre biologien forudsigelig.
Leveret af Lawrence Berkeley National Laboratory
 Varme artikler
Varme artikler
-
 Det mægtige Banyan -træ kan gå og leve i århundrederBanyan træer sender rødder ned fra deres grene i jorden, tillader dem at sprede sig lateralt over lange afstande. florentina georgescu photography/Getty Images I hovedstaden i den indiske delstat Wes
Det mægtige Banyan -træ kan gå og leve i århundrederBanyan træer sender rødder ned fra deres grene i jorden, tillader dem at sprede sig lateralt over lange afstande. florentina georgescu photography/Getty Images I hovedstaden i den indiske delstat Wes -
 At se i mørket - hvordan plantens rødder opfatter vand gennem vækstTegninger ved hjælp af beregningsmodellen, som indikerede, at opfattelsen af vand som observeret ved vandbevægelse ind i roden blev dramatisk påvirket af rodvæksthastigheden, er givet af Neil Robbin
At se i mørket - hvordan plantens rødder opfatter vand gennem vækstTegninger ved hjælp af beregningsmodellen, som indikerede, at opfattelsen af vand som observeret ved vandbevægelse ind i roden blev dramatisk påvirket af rodvæksthastigheden, er givet af Neil Robbin -
 Livets forbløffende effektivitetNeonceller. Kredit:Zighuo.he, via Wikimedia Commons Alt liv på jorden udfører beregninger - og alle beregninger kræver energi. Fra encellet amøbe til flercellede organismer som mennesker, en af
Livets forbløffende effektivitetNeonceller. Kredit:Zighuo.he, via Wikimedia Commons Alt liv på jorden udfører beregninger - og alle beregninger kræver energi. Fra encellet amøbe til flercellede organismer som mennesker, en af -
 Forskere foreslår nye rammer for regulering af manipulerede afgrøderSikkerhedstest vil blive anbefalet for produkter med nye egenskaber, der har potentiale for sundheds- eller miljøeffekter, eller for produkter med forskelle, der ikke kan fortolkes. De fleste nye vari
Forskere foreslår nye rammer for regulering af manipulerede afgrøderSikkerhedstest vil blive anbefalet for produkter med nye egenskaber, der har potentiale for sundheds- eller miljøeffekter, eller for produkter med forskelle, der ikke kan fortolkes. De fleste nye vari
- Forskere kaster nyt lys over molekylær adfærd
- Første store naturbrand i det sydlige Californien i 2020 raser fortsat
- Magnetisme opdaget i Jordens kappe
- Den første mærkning af Amazonas delfiner nogensinde for at øge bevaringsindsatsen
- Stimuleringsmidler øger social distancering for at stoppe spredningen af COVID-19
- ISS-sensorer viser terrestrisk gammastråle-flash og ionosfæriske UV-emissioner ansporet af lyn