


For at drive AI fremad, lære computere at spille gammeldags teksteventyrspil
Klar spiller en? Kredit:Wikimedia
Spil har længe været brugt som test senge og benchmarks for kunstig intelligens, og der har ikke skortet på præstationer i de seneste måneder. Google DeepMinds AlphaGo og pokerbot Libratus fra Carnegie Mellon University har begge slået menneskelige eksperter i spil, der traditionelt har været hårde for kunstig intelligens – omkring 20 år efter, at IBMs DeepBlue opnåede samme bedrift i skak.
Spil som disse har tiltrækningen af klart definerede regler; de er relativt enkle og billige for AI-forskere at arbejde med, og de giver en række kognitive udfordringer på enhver ønsket sværhedsgrad. Ved at opfinde algoritmer, der spiller dem godt, forskere håber at få indsigt i de mekanismer, der er nødvendige for at fungere selvstændigt.
Med ankomsten af de nyeste teknikker inden for AI og maskinlæring, opmærksomheden rykker nu til visuelt detaljerede computerspil-herunder 3-D shooter Doom, forskellige 2-D Atari spil såsom Pong og Space Invaders, og realtidsstrategispillet StarCraft.
Det er helt sikkert fremskridt, men en vigtig del af det større AI-billede bliver overset. Forskning har prioriteret spil, hvor alle de handlinger, der kan udføres, er kendt på forhånd, det være sig at flytte en ridder eller affyre et våben. Computeren får alle muligheder fra starten og fokus er på, hvor godt den vælger imellem dem. Problemet er, at dette afbryder AI -forskning fra opgaven med at gøre computere virkelig autonome.
Bananskind
At få computere til at bestemme, hvilke handlinger der overhovedet eksisterer i en given kontekst, giver konceptuelle og praktiske udfordringer, som spilforskere næppe har forsøgt at løse indtil videre. Problemet med "abe og bananer" er et eksempel på en langvarig kunstig gåde, hvor der ikke er gjort fremskridt for nylig.
Problemet blev oprindeligt stillet af John McCarthy, en af grundlæggerne af AI, i 1963:der er et rum med en stol, En pind, en abe og en flok bananer hængende på en loftskrog. Opgaven er, at en computer kommer med en række handlinger, der gør aben i stand til at erhverve bananerne.
McCarthy lavede en central skelnen mellem to aspekter af denne opgave med hensyn til kunstig intelligens. Fysisk gennemførlighed - bestemmelse af, om en bestemt sekvens af handlinger er fysisk realiserbar; og epistemisk eller vidensrelateret gennemførlighed - bestemme hvilke mulige handlinger for aben der faktisk eksisterer.
At bestemme, hvad der er fysisk muligt for aben, er meget let for en computer, hvis den får at vide alle mulige handlinger på forhånd – "klatre på stolen", "bølgepind" og så videre. Et simpelt program, der instruerer computeren til at gennemgå alle mulige handlingssekvenser én efter én, vil hurtigt nå frem til den bedste løsning.
Hvis computeren først skal bestemme, hvilke handlinger der overhovedet er mulige, imidlertid, det er en meget hårdere udfordring. Det rejser spørgsmål om, hvordan vi repræsenterer viden, de nødvendige og tilstrækkelige betingelser for at vide noget, og hvordan vi ved, hvornår der er opnået tilstrækkelig viden. Ved at fremhæve disse problemer, McCarthy sagde:"Vores ultimative mål er at lave programmer, der lærer af deres erfaring lige så effektivt som mennesker gør."
Indtil computere kan tackle problemer uden nogen forudbestemt beskrivelse af mulige handlinger, dette mål kan ikke nås. Det er uheldigt, at AI-forskere ignorerer dette:ikke kun er disse problemer sværere og mere interessante, de ligner en forudsætning for at gøre yderligere meningsfulde fremskridt på området.
Tekstopfordring
At arbejde selvstændigt i et komplekst miljø, det er umuligt at på forhånd beskrive, hvordan man bedst manipulerer - eller endda karakteriserer - objekterne der. At lære computere at omgå disse vanskeligheder fører straks til dybe spørgsmål om at lære af tidligere erfaringer.
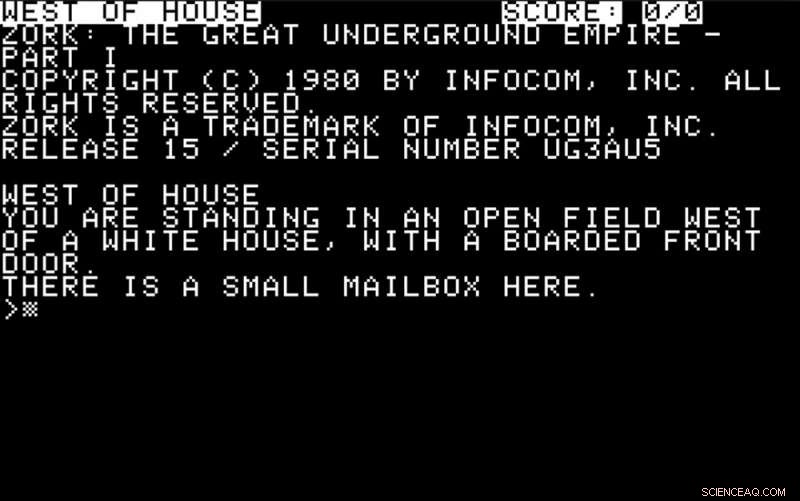
I stedet for at fokusere på spil som Doom eller StarCraft, hvor det er muligt at undgå dette problem, en mere lovende test for moderne kunstig intelligens kunne være det ydmyge teksteventyr fra 1970'erne og 1980'erne.
I dagene før computere havde sofistikerede grafikfunktioner, spil som Colossal Cave og Zork var populære. Spillere blev fortalt om deres miljø ved hjælp af beskeder på skærmen:
De skulle svare med enkle instruktioner, normalt i form af et verbum eller et verbum plus et substantiv – "se", "take box" og så videre. En del af udfordringen var at finde ud af, hvilke handlinger der var mulige og nyttige og at reagere derefter.
En god udfordring for moderne kunstig intelligens ville være at påtage sig rollen som en spiller i sådan et eventyr. Computeren skal give mening i tekstbeskrivelserne på skærmen og reagere på dem med handlinger, ved at bruge en forudsigelsesmekanisme til at bestemme deres sandsynlige effekt.
Mere sofistikeret adfærd på en del af computeren ville indebære at udforske miljøet, at definere mål, træffe målrettede handlingsvalg og løse de forskellige intellektuelle udfordringer, der typisk kræves for at komme videre.
Hvor godt moderne AI-metoder af den slags, der fremmes af teknologigiganter som IBM, Google, Facebook eller Microsoft ville klare sig i disse teksteventyr er et åbent spørgsmål - det samme er hvor meget specialiseret menneskelig viden, de ville kræve for hvert nyt scenario.
For at måle fremskridt på dette område, i de sidste to år har vi afviklet en konkurrence på IEEE Conference on Computational Intelligence and Games, som i år finder sted i Maastricht i Holland til august. Deltagere indsender bidrag på forhånd, og kan bruge AI-teknologien efter eget valg til at bygge programmer, der kan spille disse spil ved at give mening i en tekstbeskrivelse og udsende passende tekstkommandoer til gengæld.
Kort sagt, forskere er nødt til at genoverveje deres prioriteter, hvis AI skal fortsætte med at udvikle sig. Hvis det viser sig at være frugtbart at afdække disciplinens forsømte rødder, aben får endelig sine bananer.
Denne artikel blev oprindeligt publiceret på The Conversation. Læs den originale artikel. 
 Varme artikler
Varme artikler
-
 Amazon-arbejdergruppe opfordrer til strejke på grund af virus- og klimaproblemerE-handelskolossen menes at have haft COVID-19-tilfælde i en række af sine lagre Amazons teknologiarbejdere opfordrer til en virtuel endagsstrejke for at presse online-detailgiganten over lagersikk
Amazon-arbejdergruppe opfordrer til strejke på grund af virus- og klimaproblemerE-handelskolossen menes at have haft COVID-19-tilfælde i en række af sine lagre Amazons teknologiarbejdere opfordrer til en virtuel endagsstrejke for at presse online-detailgiganten over lagersikk -
 Virtuelle assistenter med personlighed kan hjælpe med psykisk sygdomKredit:CC0 Public Domain Computerforskere har været banebrydende for en ny metode, der kan bruges til at udvikle mere naturlige automatiserede virtuelle assistenter til at hjælpe mennesker, der li
Virtuelle assistenter med personlighed kan hjælpe med psykisk sygdomKredit:CC0 Public Domain Computerforskere har været banebrydende for en ny metode, der kan bruges til at udvikle mere naturlige automatiserede virtuelle assistenter til at hjælpe mennesker, der li -
 Toyotas kvartalsvise fortjeneste stiger på grund af stigende salg, omkostningsbesparelserI denne 13. nov. 2017, Foto, besøgende tager et kig på Toyota-biler i bilproducentens showroom i Tokyo. Toyota Motor Corp. har hævet sin indtjeningsprognose efter at have rapporteret, at dens fortjene
Toyotas kvartalsvise fortjeneste stiger på grund af stigende salg, omkostningsbesparelserI denne 13. nov. 2017, Foto, besøgende tager et kig på Toyota-biler i bilproducentens showroom i Tokyo. Toyota Motor Corp. har hævet sin indtjeningsprognose efter at have rapporteret, at dens fortjene -
 Kunne cryptocurrency detronisere dollaren?Dollaren er verdens bedste valuta, men hvor længe endnu? Bank of Englands guvernør Mark Carney har foreslået, at en virtuel valuta, modelleret på Facebooks Vægt, kunne en dag erstatte dollaren som
Kunne cryptocurrency detronisere dollaren?Dollaren er verdens bedste valuta, men hvor længe endnu? Bank of Englands guvernør Mark Carney har foreslået, at en virtuel valuta, modelleret på Facebooks Vægt, kunne en dag erstatte dollaren som
- Oprettelse af komplekse molekyler i nogle få trin
- Nye arter af træ-gumlende (og fallisk udseende) muslinger fundet på bunden af havet
- Ny mikroskopimetode med superopløsning nærmer sig atomskalaen
- Det er lettere at stole på automatiserede køretøjer, når vi ved, hvad de planlægger at gøre på…
- Hvilken proces udfører ribosomer?
- Pandemi lukker jordens øjne mod himlen